Pandas 数据分组
分组统计 - groupby功能
- 根据某些条件将数据拆分成组
- 对每个组独立应用函数
- 将结果合并到一个数据结构中
Dataframe在行(axis=0)或列(axis=1)上进行分组,将一个函数应用到各个分组并产生一个新值,然后函数执行结果被合并到最终的结果对象中。
df.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
1.
# 分组 df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar','foo', 'bar', 'foo', 'foo'], 'B' : ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'], 'C' : np.random.randn(8), 'D' : np.random.randn(8)}) print(df) print('------') print(df.groupby('A'), type(df.groupby('A'))) print('------') # 直接分组得到一个groupby对象,是一个中间数据,没有进行计算 a = df.groupby('A').mean() # (0.494839+0.977357 -0.079595)/3 b = df.groupby(['A','B']).mean() c = df.groupby(['A'])['D'].mean() # 以A分组,但是只计算D的平均值 print(a,type(a),'\n',a.columns) print(b,type(b),'\n',b.columns) print(c,type(c)) # 通过分组后的计算,得到一个新的dataframe # 默认axis = 0,以行来分组 # 可单个或多个([])列分组
输出结果:
A B C D 0 foo one 0.539903 -0.291392 1 bar one 0.243375 1.093706 2 foo two -0.552425 -0.333666 3 bar three 0.307315 -0.094833 4 foo two -1.011648 -0.856448 5 bar two 1.078264 1.590439 6 foo one 0.550491 -0.044095 7 foo three 0.162069 0.445236 ------ <pandas.core.groupby.DataFrameGroupBy object at 0x000001DCA7B527B8> <class 'pandas.core.groupby.DataFrameGroupBy'> ------ C D A bar 0.542985 0.863104 foo -0.062322 -0.216073 <class 'pandas.core.frame.DataFrame'> Index(['C', 'D'], dtype='object') C D A B bar one 0.243375 1.093706 three 0.307315 -0.094833 two 1.078264 1.590439 foo one 0.545197 -0.167744 three 0.162069 0.445236 two -0.782036 -0.595057 <class 'pandas.core.frame.DataFrame'> Index(['C', 'D'], dtype='object') A bar 0.863104 foo -0.216073 Name: D, dtype: float64 <class 'pandas.core.series.Series'>
2.
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar','foo', 'bar', 'foo', 'foo'],
'B' : ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],
'C' : np.random.randn(8),
'D' : np.random.randn(8)})
b = df.groupby(['A','B']).mean()
b.reset_index(inplace = True)
print(b)
输出结果:
A B C D
0 bar one -1.501298 -1.450693
1 bar three -0.623903 0.832721
2 bar two 1.264561 0.265831
3 foo one 0.996789 0.645541
4 foo three 1.338508 -1.213098
5 foo two 0.934279 -1.139260
3.
# 分组 - 可迭代对象 df = pd.DataFrame({'X' : ['A', 'B', 'A', 'B'], 'Y' : [1, 4, 3, 2]}) print(df) print(df.groupby('X'), type(df.groupby('X'))) #输出的类型为可迭代的对象 print('-----') print(list(df.groupby('X')), '→ 可迭代对象,直接生成list\n') print(list(df.groupby('X'))[0], '→ 以元祖形式显示\n') for n,g in df.groupby('X'): print(n) print(g) print('###') print('-----') # n是组名,g是分组后的Dataframe print(df.groupby(['X']).get_group('A'),'\n') print(df.groupby(['X']).get_group('B'),'\n') print('-----') # .get_group()提取分组后的组 grouped = df.groupby(['X']) print(grouped.groups,'\n') print(grouped.groups['A']) # 也可写:df.groupby('X').groups['A'] print('-----') # .groups:将分组后的groups转为dict # 可以字典索引方法来查看groups里的元素 sz = grouped.size() print(sz,type(sz)) print('-----') # .size():查看分组后的长度 df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar','foo', 'bar', 'foo', 'foo'], 'B' : ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'], 'C' : np.random.randn(8), 'D' : np.random.randn(8)}) grouped = df.groupby(['A','B']).groups print(df,'\n') print(grouped,'\n') print(grouped[('foo', 'three')]) # 按照两个列进行分组
输出结果:
X Y 0 A 1 1 B 4 2 A 3 3 B 2 <pandas.core.groupby.DataFrameGroupBy object at 0x000001DCA7BA6908> <class 'pandas.core.groupby.DataFrameGroupBy'> ----- [('A', X Y 0 A 1 2 A 3), ('B', X Y 1 B 4 3 B 2)] → 可迭代对象,直接生成list ('A', X Y 0 A 1 2 A 3) → 以元祖形式显示 A X Y 0 A 1 2 A 3 ### B X Y 1 B 4 3 B 2 ### ----- X Y 0 A 1 2 A 3 X Y 1 B 4 3 B 2 ----- {'A': Int64Index([0, 2], dtype='int64'), 'B': Int64Index([1, 3], dtype='int64')} Int64Index([0, 2], dtype='int64') ----- X A 2 B 2 dtype: int64 <class 'pandas.core.series.Series'> ----- A B C D 0 foo one 0.185932 -0.128426 1 bar one 1.205172 0.860480 2 foo two 0.965735 1.008437 3 bar three 0.442906 0.065548 4 foo two 0.461985 -1.591069 5 bar two -0.917835 -0.707424 6 foo one 0.537916 -0.031545 7 foo three 0.838332 -0.804244 {('foo', 'two'): Int64Index([2, 4], dtype='int64'), ('bar', 'one'): Int64Index([1], dtype='int64'), ('bar', 'two'): Int64Index([5], dtype='int64'), ('foo', 'three'): Int64Index([7], dtype='int64'), ('foo', 'one'): Int64Index([0, 6], dtype='int64'), ('bar', 'three'): Int64Index([3], dtype='int64')} Int64Index([7], dtype='int64')
4.
df = pd.DataFrame({'X' : ['A', 'B', 'A', 'B'], 'Y' : [1, 4, 3, 2]})
print(df)
print(df.groupby('X'), type(df.groupby('X'))) #输出的类型为可迭代的对象
print('-----')
print(list(df.groupby('X')), '→ 可迭代对象,直接生成list\n')
print(list(df.groupby('X'))[0], '→ 以元祖形式显示\n')
tup = list(df.groupby('X'))[0]
print(tup[0],type(tup[0]))
print(tup[1],type(tup[1]))
输出结果:
X Y 0 A 1 1 B 4 2 A 3 3 B 2 <pandas.core.groupby.DataFrameGroupBy object at 0x000001DCA7B87A20> <class 'pandas.core.groupby.DataFrameGroupBy'> ----- [('A', X Y 0 A 1 2 A 3), ('B', X Y 1 B 4 3 B 2)] → 可迭代对象,直接生成list ('A', X Y 0 A 1 2 A 3) → 以元祖形式显示 A <class 'str'> X Y 0 A 1 2 A 3 <class 'pandas.core.frame.DataFrame'>
5.
# 分组计算函数方法 s = pd.Series([1, 2, 3, 10, 20, 30], index = [1, 2, 3, 1, 2, 3]) grouped = s.groupby(level=0) # 唯一索引用.groupby(level=0),将同一个index的分为一组 当用index做分组的时候,用level print(grouped) print(grouped.first(),'→ first:非NaN的第一个值\n') print(grouped.last(),'→ last:非NaN的最后一个值\n') print(grouped.sum(),'→ sum:非NaN的和\n') print(grouped.mean(),'→ mean:非NaN的平均值\n') print(grouped.median(),'→ median:非NaN的算术中位数\n') print(grouped.count(),'→ count:非NaN的值\n') print(grouped.min(),'→ min、max:非NaN的最小值、最大值\n') print(grouped.std(),'→ std,var:非NaN的标准差和方差\n') print(grouped.prod(),'→ prod:非NaN的积\n')
输出结果:
<pandas.core.groupby.groupby.SeriesGroupBy object at 0x000002B38F39B4E0> 1 1 2 2 3 3 dtype: int64 → first:非NaN的第一个值 1 10 2 20 3 30 dtype: int64 → last:非NaN的最后一个值 1 11 2 22 3 33 dtype: int64 → sum:非NaN的和 1 5.5 2 11.0 3 16.5 dtype: float64 → mean:非NaN的平均值 1 5.5 2 11.0 3 16.5 dtype: float64 → median:非NaN的算术中位数 1 2 2 2 3 2 dtype: int64 → count:非NaN的值 1 1 2 2 3 3 dtype: int64 → min、max:非NaN的最小值、最大值 1 6.363961 2 12.727922 3 19.091883 dtype: float64 → std,var:非NaN的标准差和方差 1 10 2 40 3 90 dtype: int64 → prod:非NaN的积
6.
多函数计算:agg() df = pd.DataFrame({'a':[1,1,2,2], 'b':np.random.rand(4), 'c':np.random.rand(4), 'd':np.random.rand(4),}) print(df) print(df.groupby('a').agg(['mean',np.sum])) #计算一个均值和一个求和 会把b,c,d的每一列都会计算一个mean和sum print(df.groupby('a')['b'].agg({'result1':np.mean, 'result2':np.sum})) #按a分组后b这一列的均值和求和 # 函数写法可以用str,或者np.方法 # 可以通过list,dict传入,当用dict时,key名为columns → 更新pandas后会出现警告 # 尽量用list传入
输出结果:
a b c d 0 1 0.758848 0.375900 0.962917 1 1 0.430484 0.322437 0.402809 2 2 0.285699 0.230663 0.525483 3 2 0.676740 0.191693 0.874899 b c d mean sum mean sum mean sum a 1 0.594666 1.189331 0.349169 0.698337 0.682863 1.365727 2 0.481219 0.962438 0.211178 0.422356 0.700191 1.400382 result1 result2 a 1 0.594666 1.189331 2 0.481219 0.962438 C:\Users\__main__.py:10: FutureWarning: using a dict on a Series for aggregation is deprecated and will be removed in a future version
练习题:
作业1:按要求创建Dataframe df,并通过分组得到以下结果
① 以A分组,求出C,D的分组平均值
② 以A,B分组,求出D,E的分组求和
③ 以A分组,得到所有分组,以字典显示
④ 按照数值类型分组,求和
⑤ 将C,D作为一组分出来,并计算求和
⑥ 以B分组,求出每组的均值,求和,最大值,最小值


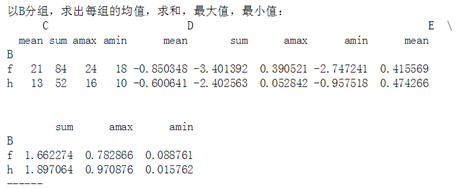
import numpy as np import pandas as pd import warnings warnings.filterwarnings('ignore') df = pd.DataFrame({'A':['one','two','three','one','two','three','one','two'], 'B':list('hhhhffff'), 'C':list(range(10,25,2)), 'D':np.random.rand(8), 'E':np.random.rand(8)}) #(1) print(df.groupby(by = 'A')[['D','E']].mean()) #(2) print(df.groupby(by = ['A','B'])[['D','E']].sum()) #(3) g = df.groupby(by = 'A') for n,i in g: print(n) print(i) #(4) print(df.groupby(df.dtypes,axis = 1).sum()) #(5) df2 = df[['C','D']] print(df2) df2['sum'] = df2.sum(axis = 1) print(df2) #(6) print(df.groupby('B').agg(['mean','sum','max',np.min]))
输出结果:
D E A one 0.371521 0.524208 three 0.549758 0.513263 two 0.407525 0.511265 D E A B one f 0.505448 0.961745 h 0.609115 0.610880 three f 0.856872 0.495862 h 0.242644 0.530664 two f 0.679124 1.358688 h 0.543450 0.175106 one A B C D E 0 one h 10 0.258020 0.411822 3 one h 16 0.351095 0.199058 6 one f 22 0.505448 0.961745 three A B C D E 2 three h 14 0.242644 0.530664 5 three f 20 0.856872 0.495862 two A B C D E 1 two h 12 0.543450 0.175106 4 two f 18 0.010620 0.919586 7 two f 24 0.668504 0.439102 int64 float64 object 0 10 0.669841 oneh 1 12 0.718555 twoh 2 14 0.773309 threeh 3 16 0.550153 oneh 4 18 0.930206 twof 5 20 1.352733 threef 6 22 1.467194 onef 7 24 1.107606 twof C D 0 10 0.258020 1 12 0.543450 2 14 0.242644 3 16 0.351095 4 18 0.010620 5 20 0.856872 6 22 0.505448 7 24 0.668504 C D sum 0 10 0.258020 10.258020 1 12 0.543450 12.543450 2 14 0.242644 14.242644 3 16 0.351095 16.351095 4 18 0.010620 18.010620 5 20 0.856872 20.856872 6 22 0.505448 22.505448 7 24 0.668504 24.668504 C D E \ mean sum max amin mean sum max amin mean B f 21 84 24 18 0.510361 2.041444 0.856872 0.010620 0.704074 h 13 52 16 10 0.348802 1.395209 0.543450 0.242644 0.329162 sum max amin B f 2.816295 0.961745 0.439102 h 1.316650 0.530664 0.175106

 浙公网安备 33010602011771号
浙公网安备 33010602011771号