Pandas 文本数据
Pandas针对字符串配备的一套方法,使其易于对数组的每个元素(字符串)进行操作。
1.通过str访问,且自动排除丢失/ NA值
# 通过str访问,且自动排除丢失/ NA值 s = pd.Series(['A','b','C','bbhello','123',np.nan,'hj']) df = pd.DataFrame({'key1':list('abcdef'), 'key2':['hee','fv','w','hija','123',np.nan]}) print(s) print(df) print('-----') print(s.str.count('b')) #对字符b进行计数 print(df['key2'].str.upper()) #upper全部变成大写 print('-----') # 直接通过.str调用字符串方法 # 可以对Series、Dataframe使用 # 自动过滤NaN值 df.columns = df.columns.str.upper() #把所有的列名变为大写的。 print(df) # df.columns是一个Index对象,也可使用.str
输出结果:
0 A 1 b 2 C 3 bbhello 4 123 5 NaN 6 hj dtype: object key1 key2 0 a hee 1 b fv 2 c w 3 d hija 4 e 123 5 f NaN ----- 0 0.0 1 1.0 2 0.0 3 2.0 4 0.0 5 NaN 6 0.0 dtype: float64 0 HEE 1 FV 2 W 3 HIJA 4 123 5 NaN Name: key2, dtype: object ----- KEY1 KEY2 0 a hee 1 b fv 2 c w 3 d hija 4 e 123 5 f NaN
2.字符串常用方法(1) - lower,upper,len,startswith,endswith
s = pd.Series(['A','b','bbhello','123',np.nan]) print(s.str.lower(),'→ lower小写\n') print(s.str.upper(),'→ upper大写\n') print(s.str.len(),'→ len字符长度\n') print(s.str.startswith('b'),'→ 判断起始是否为b\n') print(s.str.endswith('3'),'→ 判断结束是否为3\n')
输出结果:
0 a 1 b 2 bbhello 3 123 4 NaN dtype: object → lower小写 0 A 1 B 2 BBHELLO 3 123 4 NaN dtype: object → upper大写 0 1.0 1 1.0 2 7.0 3 3.0 4 NaN dtype: float64 → len字符长度 0 False 1 True 2 True 3 False 4 NaN dtype: object → 判断起始是否为b 0 False 1 False 2 False 3 True 4 NaN dtype: object → 判断结束是否为3
3.字符串常用方法(2) - strip
s = pd.Series([' jack', 'jill ', ' jesse ', 'frank']) df = pd.DataFrame(np.random.randn(3, 2), columns=[' Column A ', ' Column B '], index=range(3)) print(s) print(df) print('-----') print(s.str.strip()) #去除前后的空格 print(s.str.lstrip()) # 去除字符串中的左空格 print(s.str.rstrip()) # 去除字符串中的右空格 df.columns = df.columns.str.strip() print(df) # 这里去掉了columns的前后空格,但没有去掉中间空格
输出结果:
0 jack 1 jill 2 jesse 3 frank dtype: object Column A Column B 0 -1.110964 -0.607590 1 2.043887 0.713886 2 0.840672 -0.854777 ----- 0 jack 1 jill 2 jesse 3 frank dtype: object 0 jack 1 jill 2 jesse 3 frank dtype: object 0 jack 1 jill 2 jesse 3 frank dtype: object Column A Column B 0 -1.110964 -0.607590 1 2.043887 0.713886 2 0.840672 -0.854777
4.字符串常用方法(3) - replace
df = pd.DataFrame(np.random.randn(3, 2), columns=[' Column A ', ' Column B '], index=range(3)) df.columns = df.columns.str.replace(' ','-') print(df) # 替换 df.columns = df.columns.str.replace('-','hehe',n=1) print(df) # n:替换个数
输出结果:
df = pd.DataFrame(np.random.randn(3, 2), columns=[' Column A ', ' Column B '], index=range(3)) df.columns = df.columns.str.replace(' ','-') print(df) # 替换 df.columns = df.columns.str.replace('-','hehe',n=1) print(df) # n:替换个数
5.(1)字符串常用方法(4) - split、rsplit
s = pd.Series(['a,b,c','1,2,3',['a,,,c'],np.nan]) print(s,'\n') print(s.str.split(',')) print('1-----','\n') # 类似字符串的split print(s.str.split(',')[0]) print('2-----','\n') # 直接索引得到一个list print(s.str.split(',').str[0]) print('3-----','\n') print(s.str.split(',').str.get(1)) print('4-----','\n') # 可以使用get或[]符号访问拆分列表中的元素 print(s.str.split(',', expand=True)) print('5-----','\n') print(s.str.split(',', expand=True, n = 1)) print('6-----','\n') print(s.str.rsplit(',', expand=True, n = 1)) print('7-----','\n') # 可以使用expand可以轻松扩展此操作以返回DataFrame # n参数限制分割数 # rsplit类似于split,反向工作,即从字符串的末尾到字符串的开头 df = pd.DataFrame({'key1':['a,b,c','1,2,3',[':,., ']], 'key2':['a-b-c','1-2-3',[':-.- ']]}) print(df,'\n8-----\n') print(df['key2'].str.split('-')) # Dataframe使用split
输出结果:
0 a,b,c 1 1,2,3 2 [a,,,c] 3 NaN dtype: object 0 [a, b, c] 1 [1, 2, 3] 2 NaN 3 NaN dtype: object 1----- ['a', 'b', 'c'] 2----- 0 a 1 1 2 NaN 3 NaN dtype: object 3----- 0 b 1 2 2 NaN 3 NaN dtype: object 4----- 0 1 2 0 a b c 1 1 2 3 2 NaN None None 3 NaN None None 5----- 0 1 0 a b,c 1 1 2,3 2 NaN None 3 NaN None 6----- 0 1 0 a,b c 1 1,2 3 2 NaN None 3 NaN None 7----- key1 key2 0 a,b,c a-b-c 1 1,2,3 1-2-3 2 [:,., ] [:-.- ] 8----- 0 [a, b, c] 1 [1, 2, 3] 2 NaN Name: key2, dtype: object
5.(2)
df = pd.DataFrame({'key1':['a,b,c','1,2,3',[':,., ']],
'key2':['a-b-c','1-2-3',[':-.- ']]})
print(df,'\n8-----\n')
print(df['key2'].str.split('-'),'\n')
print(df['key2'].str.split('-',expand = True))
df['k201'] = df['key2'].str.split('-').str[0]
print('\n')
print(df['k201'])
df['k202'] = df['key2'].str.split('-').str[1]
df['k203'] = df['key2'].str.split('-').str[2]
df
输出结果:
key1 key2 0 a,b,c a-b-c 1 1,2,3 1-2-3 2 [:,., ] [:-.- ] 8----- 0 [a, b, c] 1 [1, 2, 3] 2 NaN Name: key2, dtype: object 0 1 2 0 a b c 1 1 2 3 2 NaN None None 0 a 1 1 2 NaN Name: k201, dtype: object

6.(1)字符串索引
# 字符串索引 s = pd.Series(['A','b','C','bbhello','123',np.nan,'hj']) df = pd.DataFrame({'key1':list('abcdef'), 'key2':['hee','fv','w','hija','123',np.nan]}) print(s,'\n') print(s.str[0],'\n') # 取第一个字符串 print(s.str[:2],'\n') # 取前两个字符串 print(df,'\n') print(df['key2'].str[0]) # str之后和字符串本身索引方式相同
输出结果:
0 A 1 b 2 C 3 bbhello 4 123 5 NaN 6 hj dtype: object 0 A 1 b 2 C 3 b 4 1 5 NaN 6 h dtype: object 0 A 1 b 2 C 3 bb 4 12 5 NaN 6 hj dtype: object key1 key2 0 a hee 1 b fv 2 c w 3 d hija 4 e 123 5 f NaN 0 h 1 f 2 w 3 h 4 1 5 NaN Name: key2, dtype: object
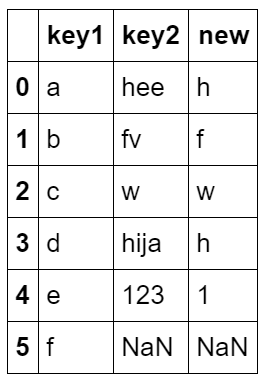
6.(2)
df = pd.DataFrame({'key1':list('abcdef'),
'key2':['hee','fv','w','hija','123',np.nan]})
df['new'] = df['key2'].str[0]
df
输出结果:
练习题:
作业1:如图创建一个Dataframe,并分别通过字符串常用方法得到3个Series或得到新的Dataframe:
① name字段首字母全部大写
② gender字段去除所有空格
③ score字段按照-拆分,分别是math,english,art三个学分

import numpy as np import pandas as pd df = pd.DataFrame({'gender':['M ',' M',' F ',' M ',' F'], 'Name':['jack','tom','marry','zack','heheda'], 'score':['90-90-90','89-89-89','90-90-90','78-78-78','60-60-60']}) print(df,'\n') df['Name'] = df['Name'].str.capitalize() #首字母大写 print(df,'\n') df['Name'] = df['Name'].str.upper() #全部大写 print(df,'\n') df['gender'] = df['gender'].str.strip() #去掉所有空格 print(df,'\n') df['Math'] = df['score'].str.split('-').str[0] df['English'] = df['score'].str.split('-').str[1] df['Art'] = df['score'].str.split('-').str[2] print(df,'\n') print(df['Math'].dtype) #字符串类型 #改为整型 df['Math'] = df['Math'].astype(np.int) print(df['Math'].dtype) #整型
输出结果:
Name gender score 0 jack M 90-90-90 1 tom M 89-89-89 2 marry F 90-90-90 3 zack M 78-78-78 4 heheda F 60-60-60 Name gender score 0 Jack M 90-90-90 1 Tom M 89-89-89 2 Marry F 90-90-90 3 Zack M 78-78-78 4 Heheda F 60-60-60 Name gender score 0 JACK M 90-90-90 1 TOM M 89-89-89 2 MARRY F 90-90-90 3 ZACK M 78-78-78 4 HEHEDA F 60-60-60 Name gender score 0 JACK M 90-90-90 1 TOM M 89-89-89 2 MARRY F 90-90-90 3 ZACK M 78-78-78 4 HEHEDA F 60-60-60 Name gender score Math English Art 0 JACK M 90-90-90 90 90 90 1 TOM M 89-89-89 89 89 89 2 MARRY F 90-90-90 90 90 90 3 ZACK M 78-78-78 78 78 78 4 HEHEDA F 60-60-60 60 60 60 object int32

 浙公网安备 33010602011771号
浙公网安备 33010602011771号