维特比算法 实现中文分词 python实现
本文转载自: https://zhuanlan.zhihu.com/p/58163299
最近我在学习自然语言处理,相信大家都知道NLP的第一步就是学分词,但分词≠自然语言处理。现如今分词工具及如何使用网上一大堆。我想和大家分享的是结巴分词核心内容,一起探究分词的本质。
(1)、基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图
什么是DAG(有向无环图)?
例如,句子“去北京大学玩”对应的DAG为{0:[0], 1:[1,2,4], 2:[2], 3:[3,4], 4:[4], 5:[5]}。DAG中{0:[0]}就表示0位置对应的是词,就是说0~0,即“去”这个词在Dict(词典库,里面记录每个词的频次)中是词条。DAG中{1:[1,2,4]},就是表示从1位置开始,在1,2,4位置都是词,就是说1~1、1~2、1~4即“北”“北京”“北京大学”这三个也是词,出现在Dict中。句子“去北京大学玩”的DAG毕竟比较短可以一眼看出来,现在来了另外一个句子“经常有意见分歧”,如何得到它的DAG呢?这时候就得通过代码来实现了。
Dict= {"经常":0.1,"经":0.05,"有":0.1, "常":0.001,"有意见":0.1, "歧":0.001,"意见":0.2,"分歧":0.2,"见":0.05,"意":0.05,"见分歧":0.05,"分":0.1}
def DAG(sentence):
DAG = {} #DAG空字典,用来构建DAG有向无环图
N = len(sentence)
for k in range(N):
tmplist = []
i = k
frag = sentence[k]
while i < N:
if frag in Dict:
tmplist.append(i)
i += 1
frag = sentence[k:i + 1]
if not tmplist:
tmplist.append(k)
DAG[k] = tmplist
return DAG
print(DAG("经常有意见分歧"))
输出:
{0: [0, 1], 1: [1], 2: [2, 4], 3: [3, 4], 4: [4, 6], 5: [5, 6], 6: [6]}
根据dict及其每个词出现的概率,可以得到所有可能出现路径(分词情况),如下图:
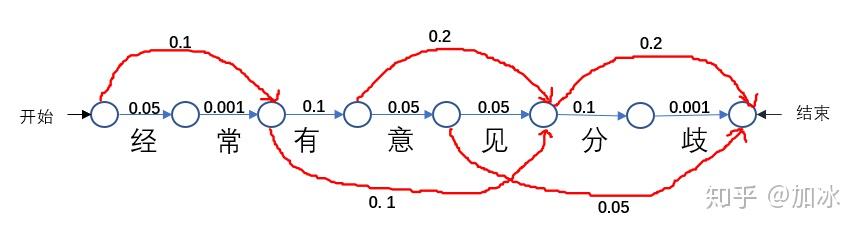
DAG的图表示
只要出现的词,就可以分,像“经常有”这个词没出现,就不能把它当做单独一个词分开了,通过运行代码,我们可以得到“经常有意见分歧”的DAG
{0: [0, 1], 1: [1], 2: [2, 4], 3: [3, 4], 4: [4, 6], 5: [5, 6], 6: [6]}
,便于直观理解DAG,我们把问题转化成寻找路径的过程,就如上图表示,从开始到结束,比如我照最上面红线的路径走,可以得到[经常|有|意见|分歧]的分词情况,如果把它们每一步的概率值加起来就是该路径的得分S=0.1+0.1+0.2+0.2=0.6,同理我走其他的路径[经|常|有意见|分歧],它的得分就是S=0.05+.0.001+0.1+0.2=0.351。这就是我们的第一步,通过代码构建出一个sentence的DAG。
(2)采用动态规划查找最大概率路径,找出基于词频的最大切分组合。
通过第一步,得到了DAG,同样也可以得到每条路径的得分S,从中找到得分最大的,也就是概率值最大的情况,就是我们要找的分词情况。如果用遍历所有路径的话,找到每个路径然后求出每个S,取出最大的S,当然可以得到我们想要的,但比较蛮力。我们可以试着用动态规划的思路,维特比算法,直接上图
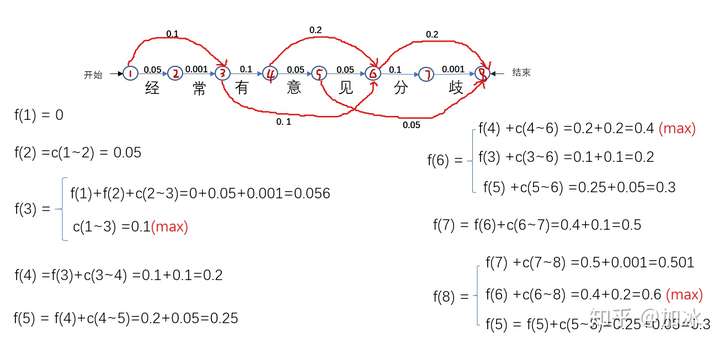 维特比算法的顺序解法
维特比算法的顺序解法
给每个节点编号1~8,开始到结束,f(a)代表该节点的所有得分值,每一步单个的箭头都有其对应的概率值,c(a~b)代表的是a节点到b节点的值,如c(1~3)是“经常”的概率值,为什么有的节点如f(6)有三个值?那是因为6这个节点有三个箭头指向它,也就是说有多少个箭头指向该节点,该节点就有多少个得分值,如分f(3)有2个值、f(4)有一个值......。按1~8的顺序,计算出每个节点的所有得分值,计算后面节点的时候要用到前面节点得分值都取(max)最大的,以保证最后计算到f(8)时是全局的最大值,例如计算f(4)中f(3)取的就是0.1。算到最后,我们知道f(8)=f(6) +c(6~8) =0.4+0.2=0.6 (max),接着把f(6)展开,f(8)=f(4) +c(4~6) +c(6~8) ,同理,把所有的f()换成c(),f(8)=c(1~3) +c(3~4) +c(4~6) +c(6~8) 。直到等式右边没有f(),c(1~3)、c(3~4)、c(4~6)、c(6~8)分别代表啥各位看图去吧。
回到开始,假如用蛮力一个一个列出所有路径,不累死也得列的头晕,用动态规划的思想可以把一个大问题拆分到每一步的小问题,下一步的小问题只需要在之前的小问题上再进一步,动态规划的思想就像是小问题站巨人肩膀上,然后大问题莫名其妙就解决了。刚说的是从开始到结束的顺序解法,要是从8节点到1节点逆序解法怎么解?
 维特比算法的逆序解法
维特比算法的逆序解法
发现没,最后最大都是0.6=f(1)=c(1~3) +c(3~4) +c(4~6) +c(6~8),而且直接都是看出来了,再一次说明了最大的路径就是这条路径。说了这么多,上代码
sentence ="经常有意见分歧"
N=len(sentence)
route={}
route[N] = (0, 0)
DAG={0: [0, 1], 1: [1], 2: [2, 4], 3: [3, 4], 4: [4, 6], 5: [5, 6], 6: [6]}
for idx in range(N - 1, -1, -1):
distance = (((Dict.get(sentence[idx:x + 1]) or 0) + route[x + 1][0], x) for x in DAG[idx])
route[idx] = max(distance)
# 列表推倒求最大概率对数路径
# route[idx] = max([ (概率值,词语末字位置) for x in DAG[idx] ])
# 以idx:(概率最大值,词语末字位置)键值对形式保存在route中)
# route[x+1][0] 表示 词路径[x+1,N-1]的最大概率值,
# [x+1][0]即表示取句子x+1位置对应元组(概率对数,词语末字位置)的概率对数
print(route)
输出结果:
{7: (0, 0), 6: (0.001, 6), 5: (0.2, 6), 4: (0.25, 4), 3: (0.4, 4), 2: (0.5, 2), 1: (0.501, 1), 0: (0.6, 1)}
这是一个自底向上的动态规划(逆序的解法),从sentence的最后一个字开始倒序遍历每个分词方式的得分。然后将得分最高的情况以(概率得分值,词语最后一个字的位置)这样的tuple保存在route中。看route的0: (0.6, 1)中的0.6,不就是我们求到的f(1)的max, 1: (0.501, 1)中的0.501不就是f(2)......后面大家对着看图找规律吧。最后小操作一波,就可以把我们要的分词结果打印出来了,结果和手推的是一样的c(1~3) +c(3~4) +c(4~6) +c(6~8)。
x = 0
segs = []
while x < N:
y = route[x][1] + 1
word = sentence[x:y]
segs.append(word)
x = y
print(segs)
#输出结果:['经常', '有', '意见', '分歧']
上面只是一些核心的思路,好多地方可以继续优化的,比如把概率值转换成-log(概率值),目的是为了防止下溢问题,只是我举例的概率值比较大,如果是一个超大的Dict,为了保证所有词的概率之和约等于1,那每个词对应的概率值会特别小。
(3)中文分词以后得攻克的难点
1、分词的规范,词的定义还不明确,没有一个公认的、权威的标准。
2、歧义词的切分。这也从侧面证实了中华文化博大精深。
3、未登录的新词。就是咱们的Dict里没有的词,对于3这个比2对分词的影响大多了,目前结巴分词对此采取的方法是:基于汉字成词能力的HMM模型,使用维特比算法。
参考:
1、贪心学院nlp
2、自然语言处理理论与实战 唐聃

 浙公网安备 33010602011771号
浙公网安备 33010602011771号