
TensorFlow安装常见问题和解决办法
TensorFlow安装常见问题和解决办法
https://blog.csdn.net/qq_44725872/article/details/107558250
https://blog.csdn.net/MSJ_nb/article/details/117462928
刚好最近在看一些关于深度学习的书,然后就想着安装tensorflow跑跑代码加深一下印象,然后就遇见了很多问题,想着不能就这么算了就查找csdn的一些大佬们的博客,幸好都有解决方法,经历了几个小时终于是弄好了,下面是我遇到的一些问题和解决方法。
问题一
安装python库首选用pip,但总会出现下载超时的问题,这里我用了豆瓣镜像来下载,会快很多,命令行运行代码。
pip install -i http://pypi.douban.com/simple --trusted-host pypi.douban.com tensorflow
问题二
下载安装时会有一些问题,例如:

这个解决,我参考了“飘洋过海95”的博客,截图也来自于他的博客。
博客链接安装Tensorflow问题,ERROR: Cannot uninstall ‘wrapt’. It is a distutils installed project and thus…
问题1解决办法:
pip install -U --ignore-installed wrapt enum34 simplejson netaddr
问题2解决办法:
pip install --upgrade setuptools
完成上面两步后,需要重新下载tensorflow,参考问题一
但是我遇到的要更复杂一些。输入方案一的
pip install -U --ignore-installed wrapt enum34 simplejson netaddr
后仍然报错:
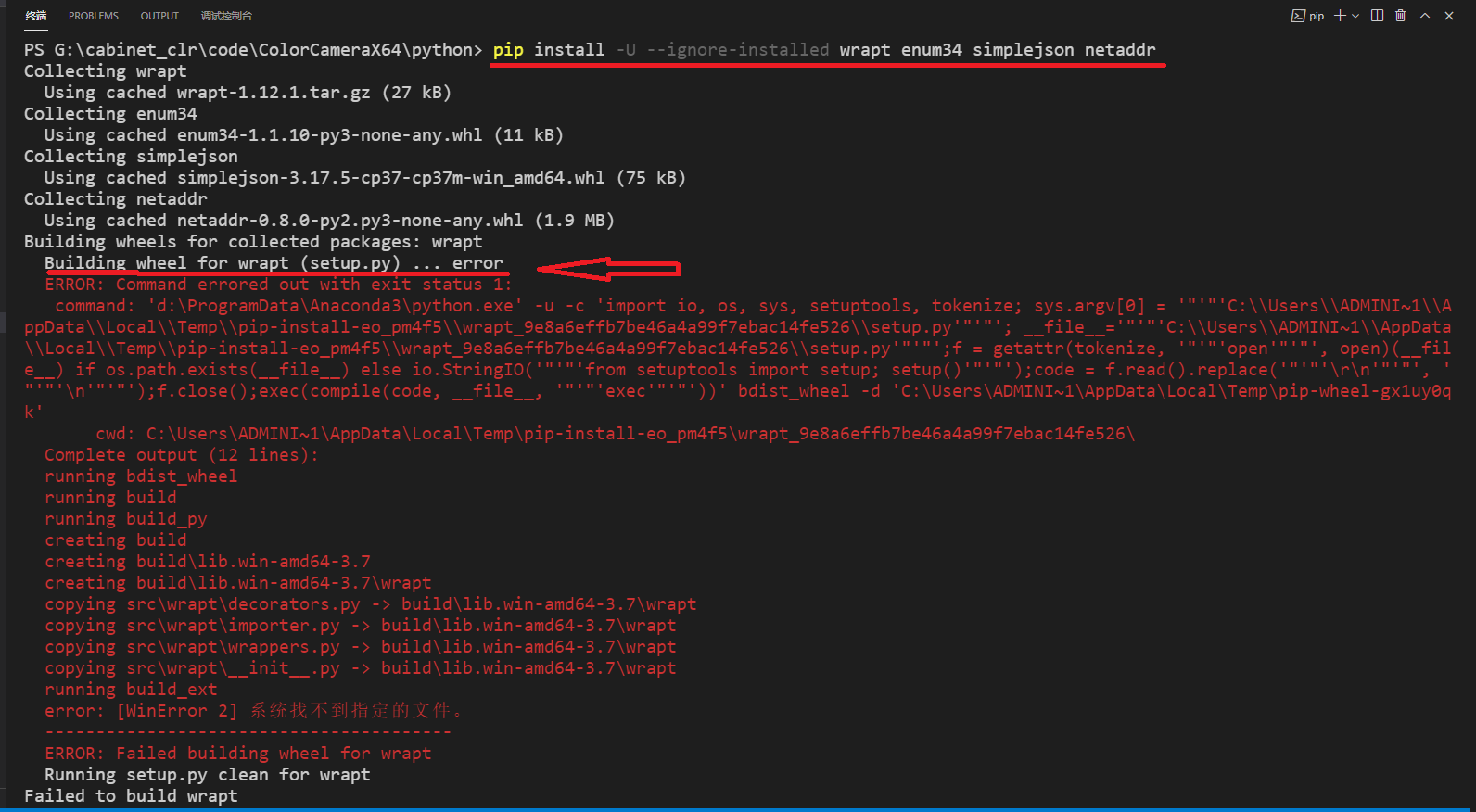
根据 Building wheel for wrapt (setup.py) ... error 报错,查找到的解决方法:
https://blog.csdn.net/weixin_43838785/article/details/103441963(此为方案二)
下载离线安装包 :wrapt-1.12.1-cp37-cp37m-win_amd64.whl
再执行命令
H:\tmp>pip install wrapt-1.12.1-cp37-cp37m-win_amd64.whl
又返回报错:

这样就陷入了两个方案的死循环
方案1:
使用--ignore-installed,
解决了方案2的
--install ,报错“error cannot uninstall 'wrapt' ” 的问题
但报错:Building wheel for wrapt (setup.py) ... error——
方案2:使用离线安装包,
解决了方案1的
“Building wheel for wrapt (setup.py) ... error”的问题
但报错:error cannot uninstall 'wrapt' ,
所以改进为
(base) H:\tmp>pip install -U --ignore-installed wrapt-1.12.1-cp37-cp37m-win_amd64.whl
即可!!再安装
tensorflow-gpu
,成功
pip install --upgrade tensorflow-gpu
问题B2:module ‘keras.utils‘ has no attribute ‘to_categorical‘ 解决办法
https://blog.csdn.net/MSJ_nb/article/details/117462928
改为
from keras.utils import np_utils
y_train = np_utils.to_categorical(y_train, num_classes)版本:keras 2.4.3 tensorflow 2.5.0
问题B3:【TensorFlow2.0】This is probably because cuDNN failed to initialize.错误修正和cuDNN版本更新
https://blog.csdn.net/licui8068/article/details/104008618
今天在环境Ubuntu16.04+TensorFlow2.0+CUDA10.1+cuDNN7.5.0中训练模型,本来是使用CPU计算的,但是后来数据量扩大后CPU已经不能满足需求了,于是便安装了TensorFlow2.0-gpu进行训练。
错误
本来已经挺简单的,因为之前在TensorFlow-gpu1.14+CUDA10.1+cuDNN7.5.0的环境下进行过训练,但是没想到会出现错误
Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
看错误提示和查询,发现这个错误有可能是我代码的问题,也有可能是因为我的cuDNN版本不适配。一开始我以为是第一点,看了其他人的博客在代码前面加上一些配置但不管用,于是只能采用第二个方法。
更新cuDNN过程
首先先使用命令 nvcc -V (注意V是大写)确定自己的CUDA版本,然后进入cuDNN下载页面。
没有账号的话应注册NVIDIA账号,登录后会看到以下页面
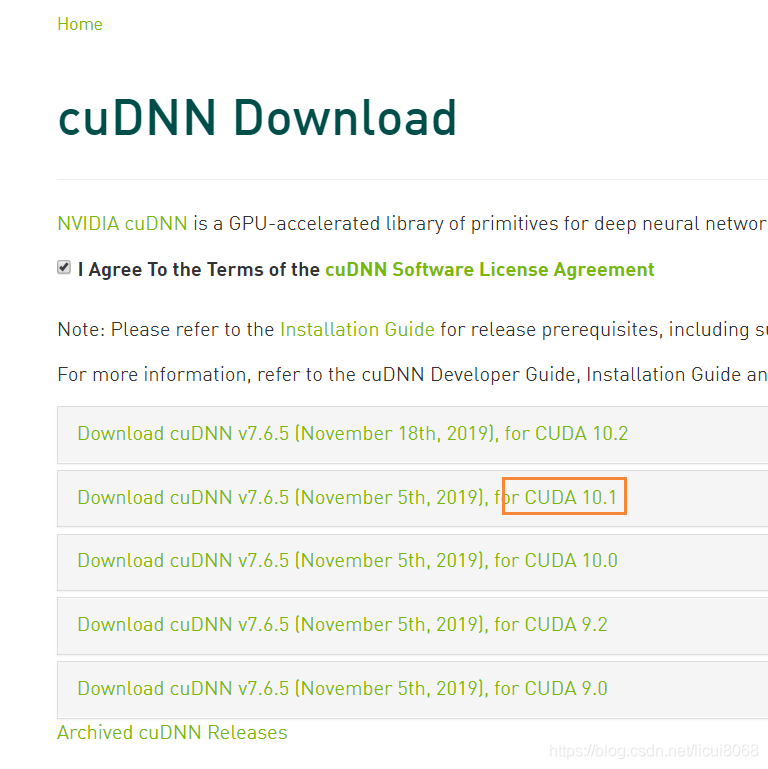
根据自己的CUDA版本下载对应的cuDNN,有两种安装方式
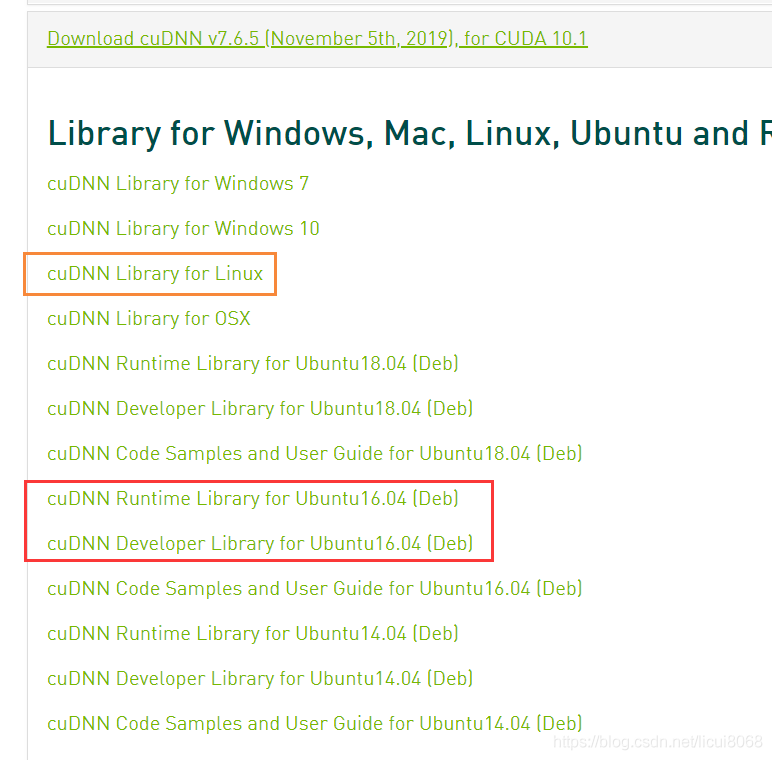
上面橙色框线相当于下载一个装载所有文件的压缩包,具体需要你自己拷贝,而红色框线则是可以直接安装的Deb文件,对于ubuntu来说非常方便,推荐下面一种。
更新cuDNN分两步,首先需要先卸载之前的版本通过dpkg卸载之前的libcudnn,卸载顺序随意
sudo dpkg -r libcudnn7-dev
sudo dpkg -r libcudnn7
第二步,安装
sudo dpkg -i libcudnn7_7.6.5.32-1+cuda10.1_amd64.deb
sudo dpkg -i libcudnn7-dev_7.6.5.32-1+cuda10.1_amd64.deb
注意上面两步的安装顺序不能更改,因为libcudnn7-dev_7.6.5.32-1+cuda10.1_amd64.deb的安装依赖于libcudnn7_7.6.5.32-1+cuda10.1_amd64.deb
第三步,完成
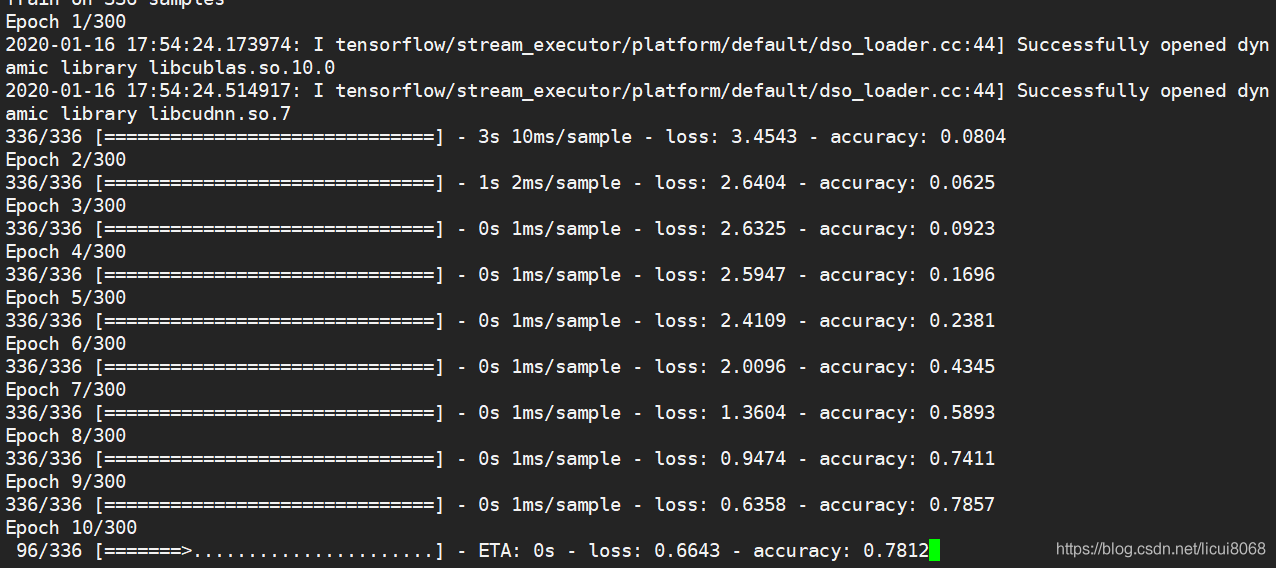
接下来就可以开始愉快地训练了~
————————————————
版权声明:本文为CSDN博主「きりり」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/licui8068/article/details/104008618

 浙公网安备 33010602011771号
浙公网安备 33010602011771号