0. Scala+Spark+HBase的IDEA环境配置
需要下载的内容:Scala、Java,注意两者之间版本是否匹配。
环境:Win10,Scala2.10.6,JDK1.7,IDEA2022.3.1
创建maven工程。
下载Scala插件。
右键项目,添加Scala框架支持。
项目结果如图所示:
scala添加为源目录,下存scala代码
添加依赖包。将property的版本号换成对应版本。依赖和插件作用在注释中。如果下载很慢记得换源。换源教程
pom.xml


<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>untitled1</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>7</maven.compiler.source> <maven.compiler.target>7</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <scala.version>2.10</scala.version> <spark.version>1.6.3</spark.version> <hbase.version>1.2.6</hbase.version> </properties> <dependencies> <!-- 导入scala的依赖 --> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>2.10.6</version> </dependency> <!-- 读取csv的依赖,非必须 --> <dependency> <groupId>au.com.bytecode</groupId> <artifactId>opencsv</artifactId> <version>2.4</version> </dependency> <!-- spark相关依赖 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <!-- sql驱动 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.43</version> </dependency > <!-- hbase相关依赖 --> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-common</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>${hbase.version}</version> </dependency> </dependencies> <build> <plugins> <!-- scala插件需要 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <executions> <execution> <id>scala-compile-first</id> <phase>process-resources</phase> <goals> <goal>add-source</goal> <goal>compile</goal> </goals> </execution> <execution> <id>scala-test-compile</id> <phase>process-test-resources</phase> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
scala文件夹下添加测试代码:
import org.apache.spark.{SparkConf, SparkContext} import au.com.bytecode.opencsv.CSVReader import org.apache.spark.rdd.RDD import java.io.StringReader object WordCount { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[*]").setAppName("sparkDemo") val sc = SparkContext.getOrCreate(conf) val input = sc.textFile("file:///home/hadoop/dream.txt"); val wordCount = input.flatMap( line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) wordCount.foreach(println) } }
maven clean,maven package,打包放到集群上跑一跑: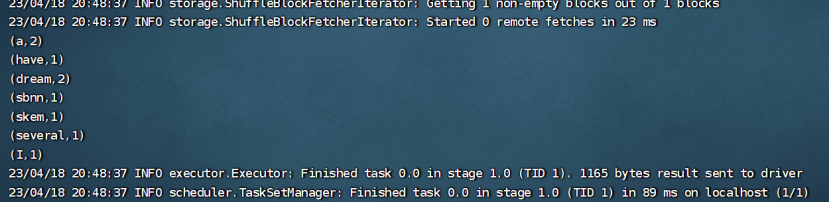
如果跑不通建议从scala输出helloworld开始调,一点一点添加依赖。
1. 了解Spark的数据读取与保存操作,尝试完成csv文件的读取和保存;
直接用sc.textFile打开会乱码,当前spark版本也不支持sparkSession,于是选择引入opencsv的依赖包
代码:
import org.apache.spark.{SparkConf, SparkContext} import au.com.bytecode.opencsv.CSVReader import java.io.StringReader object WordCount { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[*]").setAppName("sparkDemo") val sc = SparkContext.getOrCreate(conf) val input = sc.textFile("file:///home/hadoop/test.csv"); input.collect().foreach(println) val result = input.map { line => val reader = new CSVReader(new StringReader(line)); reader.readNext() } println(result.getClass) result.collect().foreach(x => { x.foreach(println); println("======") }) } }
可以发现spark的info很多,很吵,输出结果被淹没了,修改下配置:[转]Spark如何设置不打印INFO日志
2. 请使用Spark编程实现对每个学生所有课程总成绩与平均成绩的统计聚合,并将聚合结果存储到HBase表。
HBase表结构:
|
行键(number) |
列簇1(information) |
列簇2(score) |
列簇3(stat_score) |
|||||
|
列名 (name) |
列名 (sex) |
列名 (age) |
列名 (123001) |
列名 (123002) |
列名 (123003) |
列名 (sum) |
列名 (avg) |
|
|
学号 |
姓名 |
性别 |
年龄 |
成绩 |
成绩 |
成绩 |
总成绩 |
平均成绩 |
首先修改一下集群上的配置,不然会出现java.lang.NoClassDefFoundError
java.lang.NoClassDefFoundError: org/apache/hadoop/hbase/HBaseConfiguration
读写HBase有两种方式,RDD和DataFrame,其中DataFrame扩展出DataSet。
读时使用HBase,写时使用DataSet。
import org.apache.spark.{SparkConf, SparkContext} import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.client.{Put, Result} import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableOutputFormat} import org.apache.hadoop.hbase.util.Bytes import org.apache.hadoop.mapred.JobConf import org.apache.hadoop.mapreduce.Job import scala.collection.mutable.ArrayBuffer object WordCount { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[*]").setAppName("sparkDemo") val sc = SparkContext.getOrCreate(conf) val tablename = "student" val hbaseConf = HBaseConfiguration.create() hbaseConf.set("hbase.zookeeper.quorum", "192.168.56.121") hbaseConf.set("hbase.zookeeper.property.clientPort", "2181") hbaseConf.set(TableInputFormat.INPUT_TABLE, tablename) val hBaseRDD = sc.newAPIHadoopRDD(hbaseConf, classOf[TableInputFormat], classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable], classOf[org.apache.hadoop.hbase.client.Result]) val count = hBaseRDD.count() println(count) val res=hBaseRDD.map { case (_, result) => val key = Bytes.toString(result.getRow) val s1 = Bytes.toString(result.getValue("score".getBytes, "123001".getBytes)) val s2 = Bytes.toString(result.getValue("score".getBytes, "123002".getBytes)) val s3 = Bytes.toString(result.getValue("score".getBytes, "123003".getBytes)) println(key,s1,s2,s3) val total=Integer.parseInt(s1)+Integer.parseInt(s2)+Integer.parseInt(s3); val aver=total/3; key+","+total+","+aver } println(res) val hbaseConf2 = HBaseConfiguration.create() hbaseConf2.set("hbase.zookeeper.quorum", "192.168.56.121") hbaseConf2.set("hbase.zookeeper.property.clientPort", "2181") hbaseConf2.set(TableOutputFormat.OUTPUT_TABLE, tablename) val job = new Job(hbaseConf2) job.setOutputKeyClass(classOf[ImmutableBytesWritable]) job.setOutputValueClass(classOf[Result]) job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]]) val rdd=res.map(_.split(",")).map{arr=> println(arr(0),arr(1),arr(2)) val put = new Put(Bytes.toBytes(arr(0))) put.addColumn(Bytes.toBytes("stat_score"), Bytes.toBytes("sum"), Bytes.toBytes(arr(1))) put.addColumn(Bytes.toBytes("stat_score"), Bytes.toBytes("avg"), Bytes.toBytes(arr(2))) (new ImmutableBytesWritable, put) } rdd.saveAsNewAPIHadoopDataset(job.getConfiguration) sc.stop() } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号