分布式系统ID生成办法
前言
一般单机或者单数据库的项目可能规模比较小,适应的场景也比较有限,平台的访问量和业务量都较小,业务ID的生成方式比较原始但是够用,它并没有给这样的系统带来问题和瓶颈,所以这种情况下我们并没有对此给予太多的关注。但是对于大厂的那种大规模复杂业务、分布式高并发的应用场景,显然这种ID的生成方式不会像小项目一样仅仅依靠简单的数据自增序列来完成,而且在分布式环境下这种方式已经无法满足业务的需求,不仅无法完成业务能力,业务ID生成的速度或者重复问题可能给系统带来严重的故障。所以这一次,我们看看大厂都是怎么分析和解决这种ID生成问题的,同时,我也将我之前使用过的方式拿出来对比,看看有什么问题,从中能够得到什么启发。
分布式ID的生成特性
在分析之前,我们先明确一下业务ID的生成特性,在此特性的基础上,我们能够对下面的这几种生成方式有更加深刻的认识和感悟。
- 全局唯一,这是基本要求,不能出现重复。
- 数字类型,趋势递增,后面的ID必须比前面的大,这是从MySQL存储引擎来考虑的,需要保证写入数据的性能。
- 长度短,能够提高查询效率,这也是从MySQL数据库规范出发的,尤其是ID作为主键时。
- 信息安全,如果ID连续生成,势必会泄露业务信息,甚至可能被猜出,所以需要无规则不规则。
- 高可用低延时,ID生成快,能够扛住高并发,延时足够低不至于成为业务瓶颈。
分布式ID的几种生成办法
下面介绍几种我积累的分布式ID生成办法,网络上都能够找得到,我通过学习积累并后期整理加上自己的感悟分享于此。虽然平时可能因为项目规模小而用不着,但是这种提出方案的思想还是很值得学习的,尤其是像美团的Leaf方案,我感觉特别的酷。
目录:
- 基于UUID
- 基于数据库主键自增
- 基于数据库多实例主键自增
- 基于类Snowflake算法
- 基于Redis生成办法
- 基于美团的Leaf方案(ID段、双Buffer、动态调整Step)
基于UUID
这是很容易想到的方案,毕竟UUID全球唯一的特性深入人心,但是,但凡熟悉MySQL数据库特性的人,应该不会用此来作为业务ID,它不可读而且过于长,在此不是好主意,除非你的系统足够小而且不讲究这些,那就另说了。下面我们简要总结下使用UUID作为业务ID的优缺点,以及这种方式适用的业务场景。
优点
- 代码实现足够简单易用。
- 本地生成没有性能问题。
- 因为具备全球唯一的特性,所以对于数据库迁移这种情况不存在问题。
缺点
- 每次生成的ID都是无序的,而且不是全数字,且无法保证趋势递增。
- UUID生成的是字符串,字符串存储性能差,查询效率慢。
- UUID长度过长,不适用于存储,耗费数据库性能。
- ID无一定业务含义,可读性差。
适用场景
- 可以用来生成如token令牌一类的场景,足够没辨识度,而且无序可读,长度足够。
- 可以用于无纯数字要求、无序自增、无可读性要求的场景。
基于数据库主键自增
使用数据库主键自增的方式算是比较常用的了,以MySQL为例,在新建表时指定主键以auto_increment的方式自动增长生成,或者再指定个增长步长,这在小规模单机部署的业务系统里面足够使用了,使用简单而且具备一定业务性,但是在分布式高并发的系统里面,却是不适用的,分布式系统涉及到分库分表,跨机器甚至跨机房部署的环境下,数据库自增的方式满足不了业务需求,同时在高并发大量访问的情况之下,数据库的承受能力是有限的,我们简单的陈列一下这种方式的优缺点。
优点
- 实现简单,依靠数据库即可,成本小。
- ID数字化,单调自增,满足数据库存储和查询性能。
- 具有一定的业务可读性。
缺点
- 强依赖DB,存在单点问题,如果数据库宕机,则业务不可用。
- DB生成ID性能有限,单点数据库压力大,无法扛高并发场景。
适用场景
- 小规模的,数据访问量小的业务场景。
- 无高并发场景,插入记录可控的场景。
基于数据库多实例主键自增
上面我们大致讲解了数据库主键自增的方式,讨论的时单机部署的情况,如果要以此提高ID生成的效率,可以横向扩展机器,平衡单点数据库的压力,这种方案如何实现呢?那就是在auto_increment的基础之上,设置step增长步长,让DB之前生成的ID趋势递增且不重复。
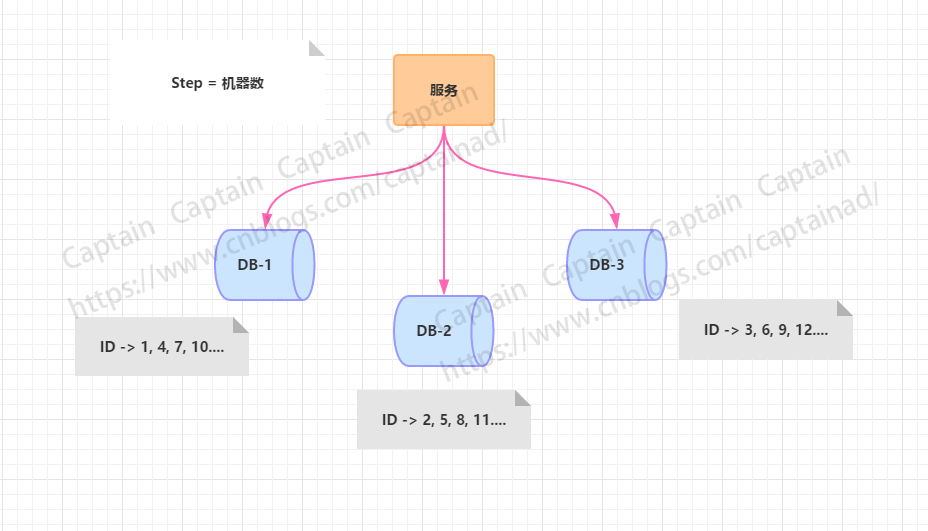
从上图可以看出,水平扩展的数据库集群,有利于解决数据库单点压力的问题,同时为了ID生成特性,将自增步长按照机器数量来设置,但是,这里有个缺点就是不能再扩容了,如果再扩容,ID就没法儿生成了,步长都用光了,那如果你要解决新增机器带来的问题,你或许可以将第三台机器的ID起始生成位置设定离现在的ID比较远的位置,同时把新的步长设置进去,同时修改旧机器上ID生成的步长,但必须在ID还没有增长到新增机器设置的开始自增ID值,否则就要出现重复了。
优点
- 解决了ID生成的单点问题,同时平衡了负载。
缺点
- 一定确定好步长,将对后续的扩容带来困难,而且单个数据库本身的压力还是大,无法满足高并发。
适用场景
- 数据量不大,数据库不需要扩容的场景。
这种方案,除了难以适应大规模分布式和高并发的场景,普通的业务规模还是能够胜任的,所以这种方案还是值得积累。
基于类Snowflake算法
我们现在的项目都不大,使用的是IdWorker——国内开源的基于snowflake算法思想实现的一款分布式ID生成器,snowflake雪花算法是twitter公司内部分布式项目采用的ID生成算法,现在开源并流行了起来,下面是Snowflake算法的ID构成图。
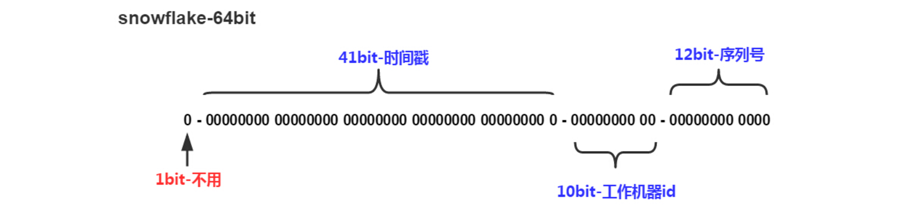
这种方案巧妙地把64位分别划分成多段,分开表示时间戳差值、机器标识和随机序列,先以此生成一个64位地二进制正整数,然后再转换成十进制进行存储。
其中,1位标识符,不使用且标记为0;41位时间戳,用来存储时间戳的差值;10位机器码,可以标识1024个机器节点,如果机器分机房部署(IDC),这10位还可以拆分,比如5位表示机房ID,5位表示机器ID,这样就有32*32种组合,一般来说是足够了;最后的12位随即序列,用来记录毫秒内的计数,一个节点就能够生成4096个ID序号。所以综上所述,综合计算下来,理论上Snowflake算法方案的QPS大约为409.6w/s,性能足够强悍了,而且这种方式,能够确保集群中每个节点生成的ID都是不同的,且区间内递增。
优点
- 每秒能够生成百万个不同的ID,性能佳。
- 时间戳值在高位,中间是固定的机器码,自增的序列在地位,整个ID是趋势递增的。
- 能够根据业务场景数据库节点布置灵活挑战bit位划分,灵活度高。
缺点
- 强依赖于机器时钟,如果时钟回拨,会导致重复的ID生成,所以一般基于此的算法发现时钟回拨,都会抛异常处理,阻止ID生成,这可能导致服务不可用。
适用场景
- 雪花算法有很明显的缺点就是时钟依赖,如果确保机器不存在时钟回拨情况的话,那使用这种方式生成分布式ID是可行的,当然小规模系统完全是能够使用的。
基于Redis生成办法
Redis的INCR命令能够将key中存储的数字值增一,得益于此操作的原子特性,我们能够巧妙地使用此来做分布式ID地生成方案,还可以配合其他如时间戳值、机器标识等联合使用。
优点
- 有序递增,可读性强。
- 能够满足一定性能。
缺点
- 强依赖于Redis,可能存在单点问题。
- 占用宽带,而且需要考虑网络延时等问题带来地性能冲击。
适用场景
- 对性能要求不是太高,而且规模较小业务较轻的场景,而且Redis的运行情况有一定要求,注意网络问题和单点压力问题,如果是分布式情况,那考虑的问题就更多了,所以一帮情况下这种方式用的比较少。
Redis的方案其实可靠性有待考究,毕竟依赖于网络,延时故障或者宕机都可能导致服务不可用,这种风险是不得不考虑在系统设计内的。
基于美团的Leaf方案
从上面的几种分布式ID方案可以看出,能够解决一定问题,但是都有明显缺陷,为此,美团在数据库的方案基础上做了一个优化,提出了一个叫做Leaf-segment的数据库方案。
原方案我们每次获取ID都需要去读取一次数据库,这在高并发和大数据量的情况下很容易造成数据库的压力,那能不能一次性获取一批ID呢,这样就无需频繁的造访数据库了。
Leaf-segment的方案就是采用每次获取一个ID区间段的方式来解决,区间段用完之后再去数据库获取新的号段,这样一来可以大大减轻数据库的压力,那怎么做呢?
很简单,我们设计一张表如下:
+-------------+--------------+------+-----+-------------------+-----------------------------+ | Field | Type | Null | Key | Default | Extra | +-------------+--------------+------+-----+-------------------+-----------------------------+ | biz_tag | varchar(128) | NO | PRI | | | | max_id | bigint(20) | NO | | 1 | | | step | int(11) | NO | | NULL | | | desc | varchar(256) | YES | | NULL | | | update_time | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP | +-------------+--------------+------+-----+-------------------+-----------------------------+
其中biz_tag用来区分业务,max_id表示该biz_tag目前所被分配的ID号段的最大值,step表示每次分配的号段长度,后面的desc和update_time分别表示业务描述和上一次更新号段的时间。原来每次获取ID都要访问数据库,现在只需要把Step设置的足够合理如1000,那么现在可以在1000个ID用完之后再去访问数据库了,看起来真的很酷。
我们现在可以这样设计整个获取分布式ID的流程了:
- 用户服务在注册一个用户时,需要一个用户ID;会请求生成ID服务(是独立的应用)的接口
- 生成ID的服务会去查询数据库,找到user_tag的id,现在的max_id为0,step=1000
- 生成ID的服务把max_id和step返回给用户服务,并且把max_id更新为max_id = max_id + step,即更新为1000
- 用户服务获得max_id=0,step=1000;
- 这个用户服务可以用[max_id + 1,max_id+step]区间的ID,即为[1,1000]
- 用户服务把这个区间保存到jvm中
- 用户服务需要用到ID的时候,在区间[1,1000]中依次获取id,可采用AtomicLong中的getAndIncrement方法。
- 如果把区间的值用完了,再去请求生产ID的服务的接口,获取到max_id为1000,即可以用[max_id + 1,max_id+step]区间的ID,即为[1001,2000]
显而易见,这种方式很好的解决了数据库自增的问题,而且可以自定义max_id的起点,可以自定义步长,非常灵活易于扩容,于此同时,这种方式也很好的解决了数据库压力问题,而且ID号段是存储在JVM中的,性能获得极大的保障,可用性也过得去,即时数据库宕机了,因为JVM缓存的号段,系统也能够因此撑住一段时间。
优点
- 扩张灵活,性能强能够撑起大部分业务场景。
- ID号码是趋势递增的,满足数据库存储和查询性能要求。
- 可用性高,即使ID生成服务器不可用,也能够使得业务在短时间内可用,为排查问题争取时间。
- 可以自定义max_id的大小,方便业务迁移,方便机器横向扩张。
缺点
- ID号码不够随机,完整的顺序递增可能带来安全问题。
- DB宕机可能导致整个系统不可用,仍然存在这种风险,因为号段只能撑一段时间。
- 可能存在分布式环境各节点同一时间争抢分配ID号段的情况,这可能导致并发问题而出现ID重复生成。
上面的缺点同样需要引起足够的重视,美团技术团队同样想出了一个妙招——双Buffer。
正如上所述,既然可能存在多个节点同时请求ID区间的情况,那么避免这种情况就好了,Leaf-segment对此做了优化,将获取一个号段的方式优化成获取两个号段,在一个号段用完之后不用立马去更新号段,还有一个缓存号段备用,这样能够有效解决这种冲突问题,而且采用双buffer的方式,在当前号段消耗了10%的时候就去检查下一个号段有没有准备好,如果没有准备好就去更新下一个号段,当当前号段用完了就切换到下一个已经缓存好的号段去使用,同时在下一个号段消耗到10%的时候,又去检测下一个号段有没有准备好,如此往复。
下面简要梳理下流程:
- 当前获取ID在buffer1中,每次获取ID在buffer1中获取
- 当buffer1中的Id已经使用到了100,也就是达到区间的10%
- 达到了10%,先判断buffer2中有没有去获取过,如果没有就立即发起请求获取ID线程,此线程把获取到的ID,设置到buffer2中。
- 如果buffer1用完了,会自动切换到buffer2
- buffer2用到10%了,也会启动线程再次获取,设置到buffer1中
- 依次往返
双buffer的方案考虑的很完善,有单独的线程去观察下一个buffer何时去更新,两个buffer之间的切换使用也解决了临时去数据库更新号段可能引起的并发问题。这样的方式能够增加JVM中业务ID的可用性,而且建议segment的长度为业务高峰期QPS的100倍(经验值,具体可根据自己业务来设定),这样即使DB宕机了,业务ID的生成也能够维持相当长的时间,而且可以有效的兼容偶尔的网络抖动等问题。
优点
- 基本的数据库问题都解决了,而且行之有效。
- 基于JVM存储双buffer的号段,减少了数据库查询,减少了网络依赖,效率更高。
缺点
- segment号段长度是固定的,业务量大时可能会频繁更新号段,因为原本分配的号段会一下子用完。
- 如果号段长度设置的过长,但凡缓存中有号段没有消耗完,其他节点重新获取的号段与之前相比可能跨度会很大。
针对上面的缺点,美团有重新提出动态调整号段长度的方案。
动态调整Step
一般情况下,如果你的业务不会有明显的波峰波谷,可以不用太在意调整Step,因为平稳的业务量长期运行下来都基本上固定在一个步长之间,但是如果是像美团这样有明显的活动期,那么Step是要具备足够的弹性来适应业务量不同时间段内的暴增或者暴跌。
假设服务QPS为Q,号段长度为L,号段更新周期为T,那么Q * T = L。最开始L长度是固定的,导致随着Q的增长,T会越来越小。但是本方案本质的需求是希望T是固定的。那么如果L可以和Q正相关的话,T就可以趋近一个定值了。所以本方案每次更新号段的时候,会根据上一次更新号段的周期T和号段长度step,来决定下一次的号段长度nextStep,下面是一个简单的算法,意在说明动态更新的意思:
T < 15min,nextStep = step * 2 15min < T < 30min,nextStep = step T > 30min,nextStep = step / 2
至此,满足了号段消耗稳定趋于某个时间区间的需求。当然,面对瞬时流量几十、几百倍的暴增,该种方案仍不能满足可以容忍数据库在一段时间不可用、系统仍能稳定运行的需求。因为本质上来讲,此方案虽然在DB层做了些容错方案,但是ID号段下发的方式,最终还是需要强依赖DB,最后,还是需要在数据库高可用上下足工夫。
参考资料
1、https://www.toutiao.com/i6682195317716156942/?group_id=6682195317716156942
2、https://www.toutiao.com/i6682672464708764174
3、https://tech.meituan.com/2017/04/21/mt-leaf.html
4、https://tech.meituan.com/2019/03/07/open-source-project-leaf.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号