每天一点点之数据结构与算法 - 链表
常见的策略有三种:
- 先进先出策略 FIFO(First In,First Out)
- 最少使用策略 LFU(Least Frequently Used)
- 最近最少使用策略 LRU(Least Recently Used)
对比数组和链表:
- 数组:是一块连续的存储单元
- 链表:是通过“指针”将一组零散的内存块串联起来进行存储
三种常见的链表:
- 单链表
- 双向链表
- 循环链表
下面说一下概念:
- 节点:内存块
- 后继指针 next:记录下个结点地址的指针
说了这多,下面就开始说一下常见的三种链表
一、单链表
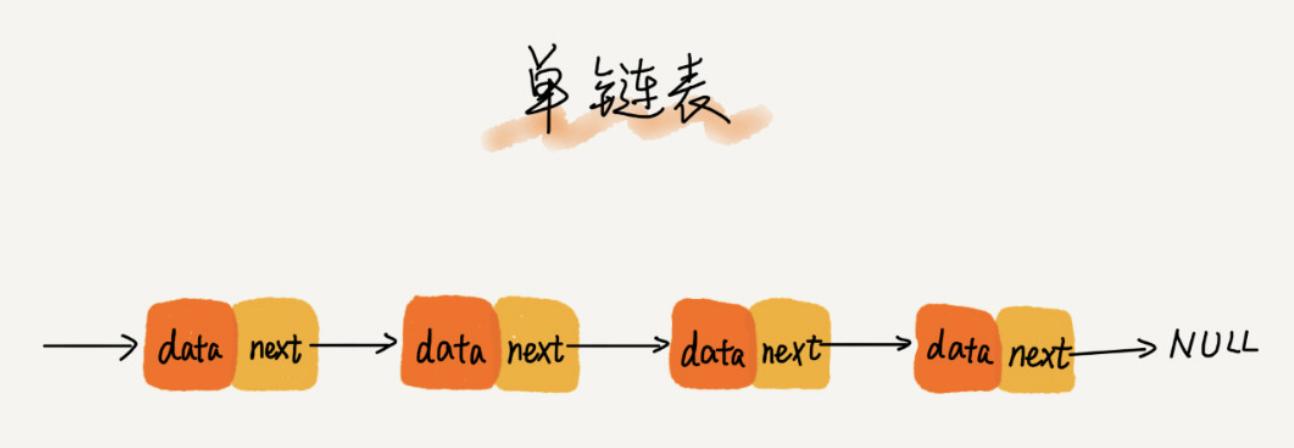
我们习惯性地把第一个结点叫作头结点,把最后一个结点叫作尾结点。头节点用来记录链表的基地址,尾节点指向NULL,表示这是链表上的最后一个节点。
与数组一样,链表也支持数据的查找、插入、删除操作。
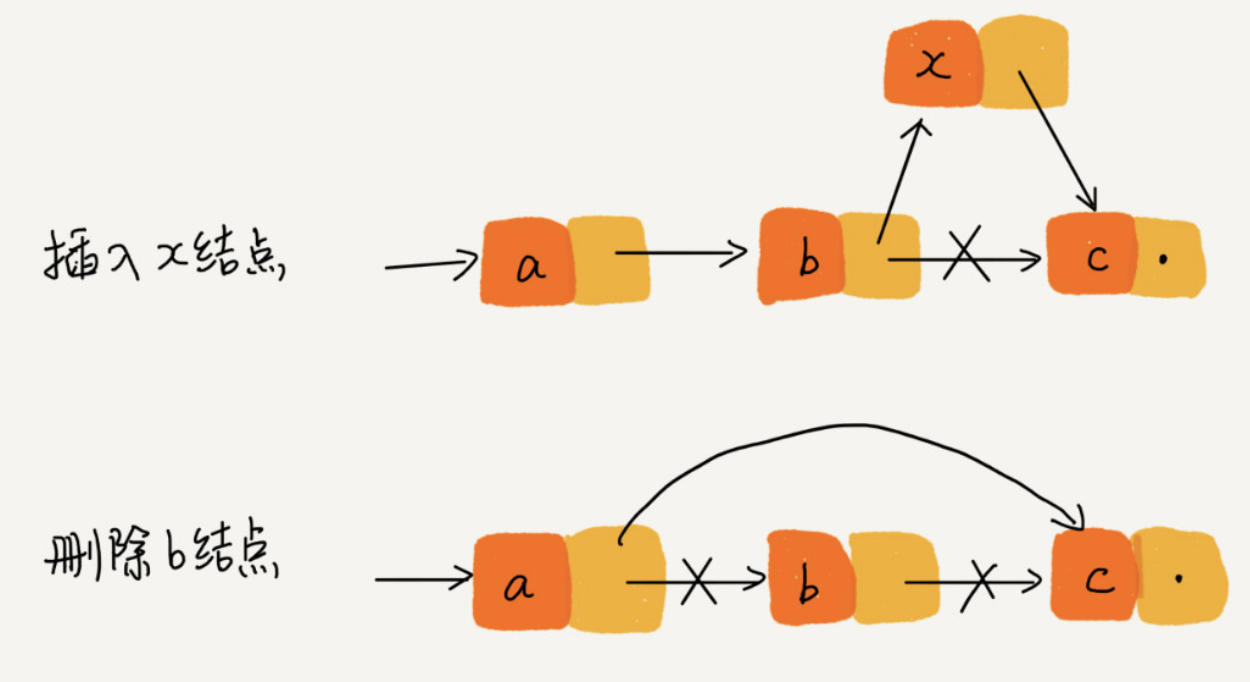
在进行数组的插入、删除操作时,为了保持内存数据的连续性,需要做大量的数据搬移,所以时间复杂度是 O(n)。而在链表中插入或者删除一个数据,我们并不需要为了保持内存的连续性而搬移结点,因为链表的存储空间本身就不是连续的。所以,在链表中插入和删除一个数据是非常快速的。
下图为链表的插入、删除操作,只需要考虑相邻结点的指针改变,所以对应的时间复杂度是 O(1):
而相对插入删除,链表的查找就没有数组方便了,因为链表的数据不是连续存储的,因此在查找的时候就不会想数组那样通过下标来直接访问,链表需要通过遍历来查找,因此,链表的查找时间复杂度为O(n)。
二、循环链表
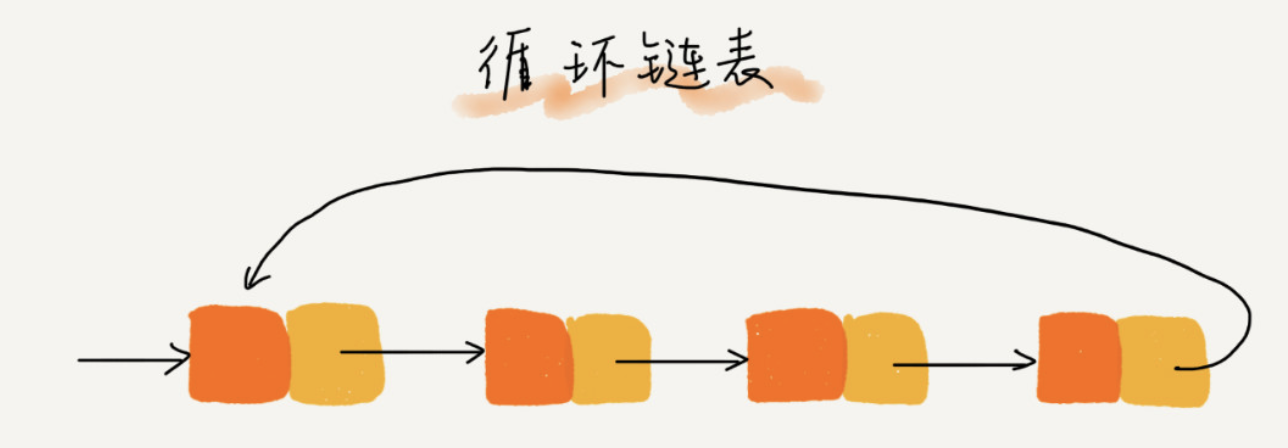
循环链表是特殊的单链表
跟单链表唯一的区别就在尾结点。单链表的尾结点指针指向空地址。循环链表的尾结点指针是指向链表的头结点。像一个环一样首尾相连,所以叫作“循环”链表。
当要处理的数据具有环型结构特点时,就特别适合采用循环链表。比如著名的约瑟夫问题。
三、循环链表
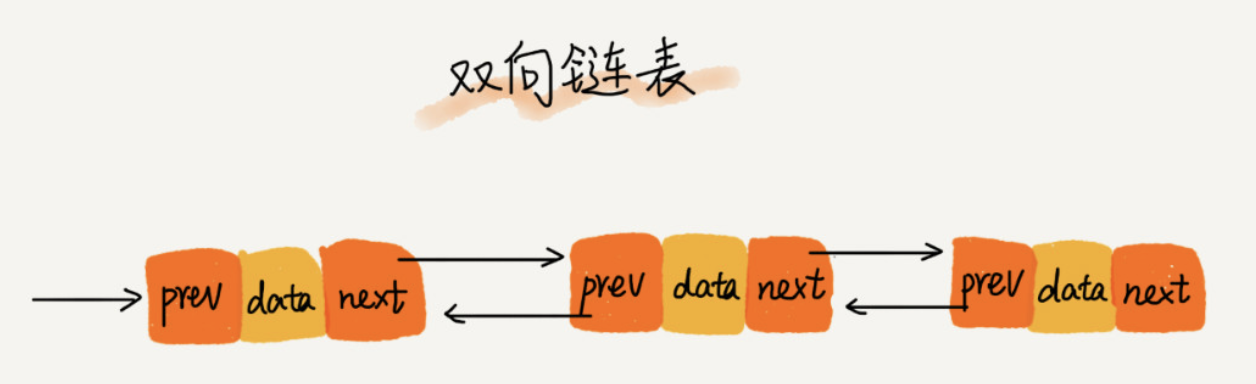
从图中可以看出,双向链表就是链表不止有后继指针,还有一个前驱指针
从结构上来看,双向链表可以支持 O(1) 时间复杂度的情况下找到前驱结点,正是这样的特点,也使双向链表在某些情况下的插入、删除等操作都要比单链表简单、高效。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号