

多线程三-线程安全之可见性与有序性
volatile关键字来确保线程间的可见性,可以利用线程可见性在某些场景进行无锁化编程。
下载Hotspot源码:
- 官网:https://openjdk.org/
- 左侧菜单,Source Code 下面的Mecurial
- 点击jdk8
- 点击hotspot
- 点击zip
volatile关键字来确保线程间的可见性,可以利用线程可见性在某些场景进行无锁化编程。
线程可见性问题
问题描述及原因
类似于数据库事务的脏读。
package com.caozz.demo2.thread.concurrent;
/**
* caozz
*/
public class VolatileExample {
// public volatile static boolean stop=false;
public static boolean stop=false;
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
int i=0;
while(!stop){ //load
i++;
// System.out.println("i:" + i);
// try {
// Thread.sleep(0);
// } catch (InterruptedException e) {
// throw new RuntimeException(e);
// }
}
});
t1.start();
System.out.println("begin start thread");
Thread.sleep(1000);
stop=true;
}
}
如果就当前代码,程序不会停止。造成这个问题的原因是stop这个变量没有通过volatile关键字修饰,而主线程睡眠的1000ms中,while中的stop一直处于false状态,循环到一定次数,会触发jvm的即时编译功能,导致循环表达式外提使得程序死循环。如果加了volatile,会保证stop这个变量的可见性,从而避免JIT的优化。
优化后等价于下面的代码
if (!stop) {
while (true) {
i++;
}
}
这个深度优化是即时编译器帮我们做的,我们可以通过增加jvm参数来禁止
-Djava.compile=NONE
增加println可以解决的原因
- println底层用了syncronized关键字,这个同步会防止循环期间对stop值得缓存
- 加锁和释放锁:释放锁会强制把工作内存中涉及到得写操作同步到主内存
- IO操作:因为IO操作效率慢,所以CPU有时间做内存刷新得事情,在这里定义一个new File()有同样的效果
了解可见性本质
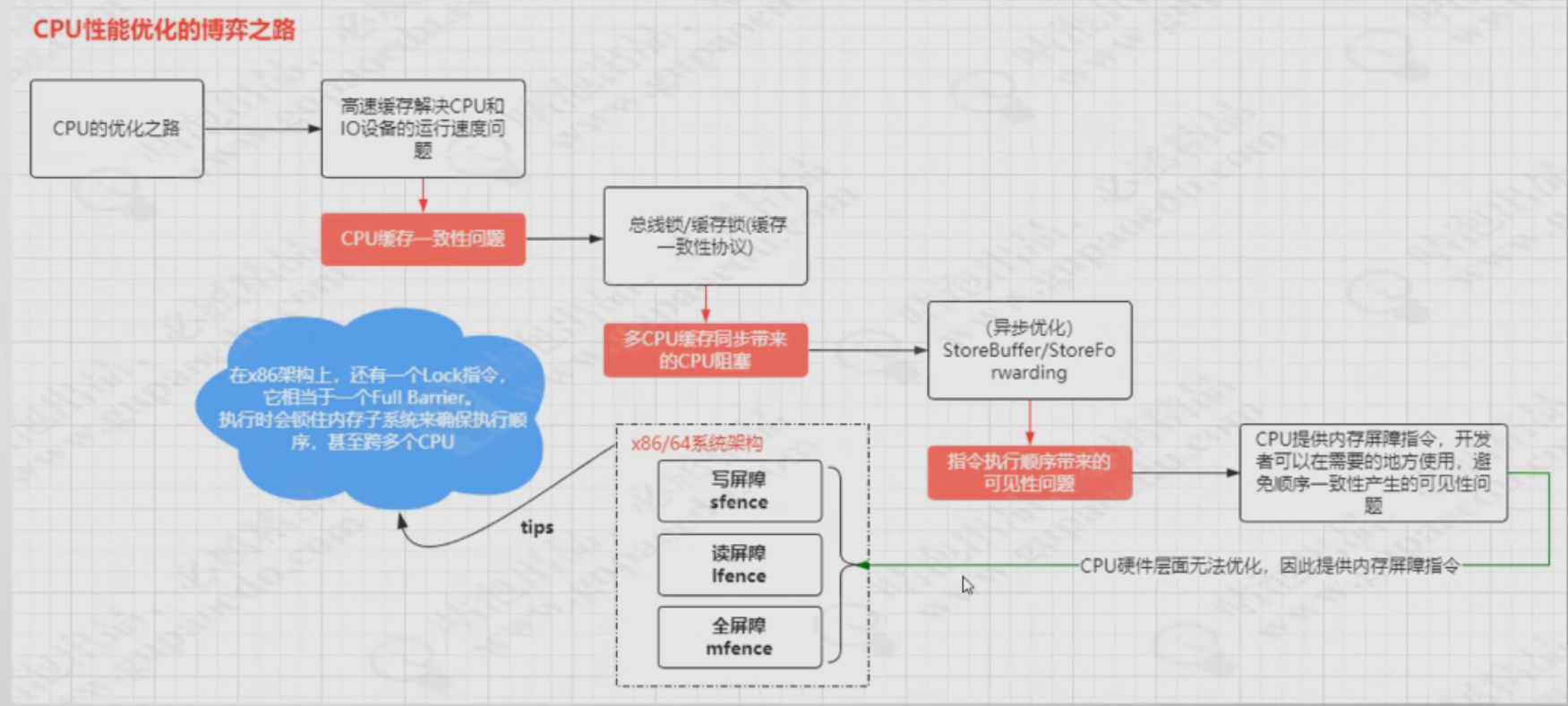
要了解可见性本质,需要了解软硬件为了提升性能所做的优化
我们知道,计算机是运用CPU进行数据运算的,但是CPU只能对内存中数据进行运算,磁盘中得数据,需要先读到内存中。
但是CPU得运算速度远高于内存得IO速度。虽然CPU从单核升级到多核,甚至到超线程技术,在最大化的提高CPU得处理性能,但是仅仅提高CPU性能是不够得,如果内存和磁盘得处理性能没有跟上,就意味着整体得计算效率取决于最慢得设备。为了平衡三者的速度差异,所以在硬件层面,操作系统层面,编译器层面做出了很多的优化:
- CPU增加了高速缓存
- 操作系统增加了进程、线程,通过CPU的时间片切换最大化提升CPU使用率
- 编译器的指令优化,更合理的利用好CPU的高速缓存
上面的 每一种优化,都会带来相应的问题,而这些问题,是导致线程安全问题的根源
CPU层面的缓存
CPU在做计算时,和内存的IO操作是无法避免的,而这个IO过程相对于CPU的计算速度是非常耗时的,所以在CPU层面设计了高速缓存。这个缓存,可以缓存存储在内存中的数据,CPU每次先从缓存行 中 读取运算需要的数据,如果不存在才从内存中加载。通过这样一个机制,减少内存和CPU交互的开销,从而提升CPU使用率。对于主流的X86平台,CPU缓存行cache分为L1,L2,L3三级,模型如下图:

缓存一致性问题
缓存一致性问题
多个线程并发访问同一个共享变植的时候,这些线程的执行处理器上的高速缓存各自都会保留一份该共享变撒的副本,这就带来一个新问题一个处理器对其副本数据进行更新之后, 其他处理器如何 “察觉” 到该更新并做出适当反应, 以确保这些处理器后续读取该共享变扯时能够读取到这个更新。这就是缓存一致性问题。
例如:
CPU-0读取主存的数据,缓存到CPU-0的高速缓存中,CPU-1也做了同样的事情,而CPU-1把count的值修改成了2,并且同步到CPU-1的高速缓存,但是这个修改以后的值并没有写入到主存中,CPU-0访问该字节,由于缓存没有更新,所以仍然是之前的值,就会导致数据不一致的问题.
缓存一致性协议
MESI (Modified-Exclusive-Shared-Invalid)协议是一种广为使用的缓存一致性协议, x86处理器所使用的缓存一致性协议就是基于MESI协议的。
MESI协议对内存数据访问的控制类似读写锁,它使得针对同一地址的读内存操作是并发的,而针对同一地址的写内存操作是独占的,即针对同一内存地址进行的写操作在任意一个时刻只能够由一个处理器执行。 在MESI协议中, 一个处理器往内存中写数据时必须持有该数据的所有权。
为了保障数据的一致性. MESI将缓存条目的状态划分为Modified(更新的)、Exclusive(排外的)、Shared(共享的)和Invalid(无效的)这4种, 并在此基础上定义了一组消息(Message)用于协调各个处理器的读、 写内存操作。
MESI协议中一个缓存条目的Flag值有以下4种可能:
•Invalid (无效的.记为I)。 该状态表示相应缓存行中不包含任何内存地址对应的有效副本数据。 该状态是缓存条目的初始状态。
•Shared (共享的,记为s)。 该状态表示相应缓存行包含相应内存地址所对应的 副本数据。 并且, 其他处理器上的高速缓存中也可能包含相同内存地址对应的副本数据。因此,一个缓存条目的状态如果为 Shared, 并且其他处理器上也存在 Tag 值与该缓存条目的 Tag 值相同的缓存条目,那么这些缓存条目的状态也为 Shared。 处于该状态的缓存条目, 其缓存行中包含的数据与主内存中包含的数据一致。
•Exclusive (独占的,记为 E) 。该状态表示相应缓存行包含相应内存地址所对应 的副本数据。 并且, 该缓存行以独占的方式保留了相应内存地址的副本数据, 即 其他所有处理器上的高速缓存当前都不保留该数据的有效副本。 处千该状态的缓 存条目, 其缓存行中包含的数据与主内存中包含的数据一致。
•Modified (更改过的,记为 M) 。该状态表示相应缓存行包含对相应内存地址所做的更新结果数据。 由于 MESI 协议中的任意一个时刻只能够有一个处理器对同一内存地址对应的数据进行更新, 因此在多个处理器上的高速缓存中 Tag 值相同 的缓存条目中, 任意一个时刻只能够有一个缓存条目处于该状态。 处于该状态的 缓存条目, 其缓存行中包含的数据与主内存中包含的数据不一致。
MESI 协议定义了一组消息 (Message) 用于协调各个处理器的读、 写内存操作。
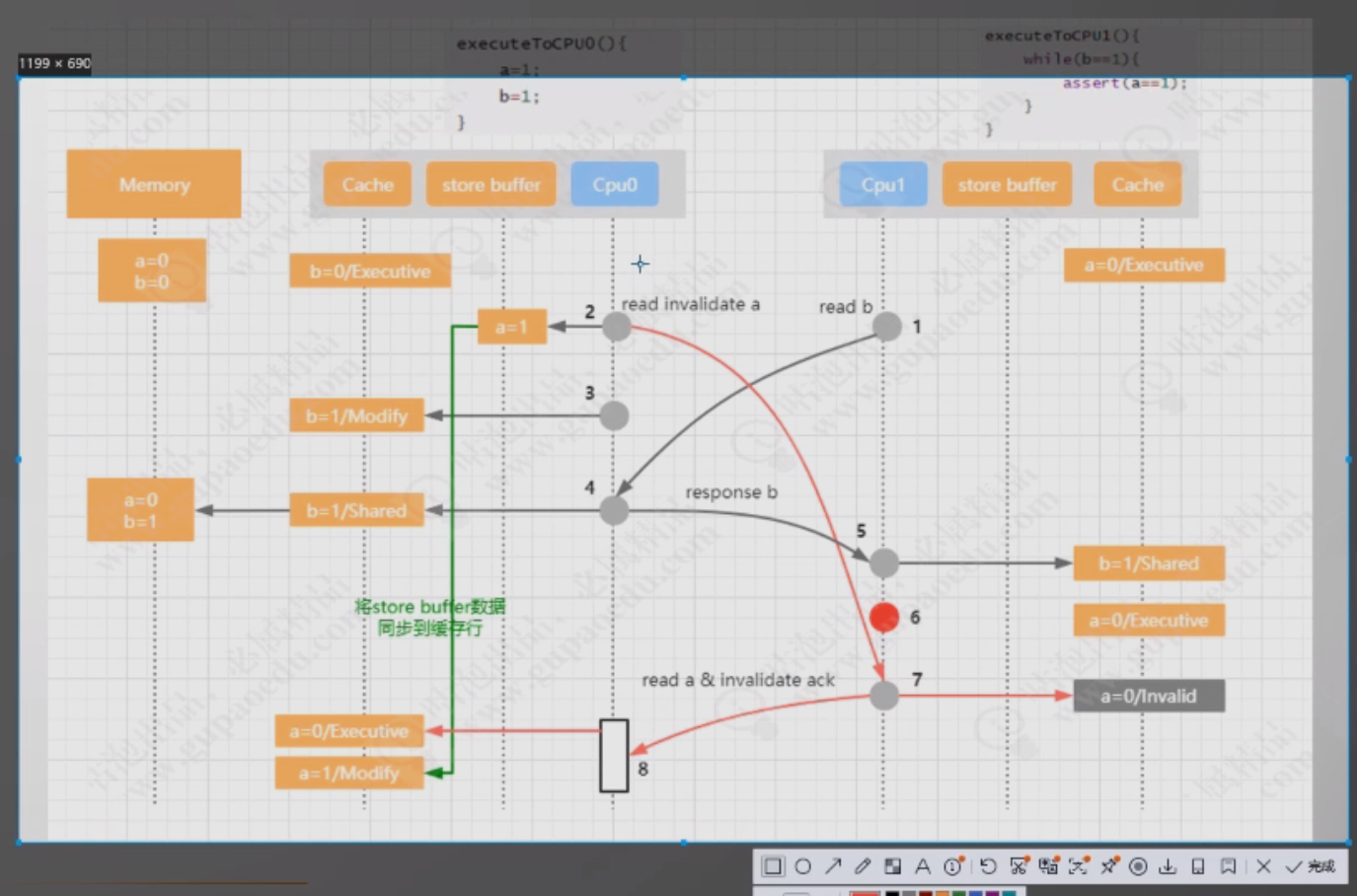
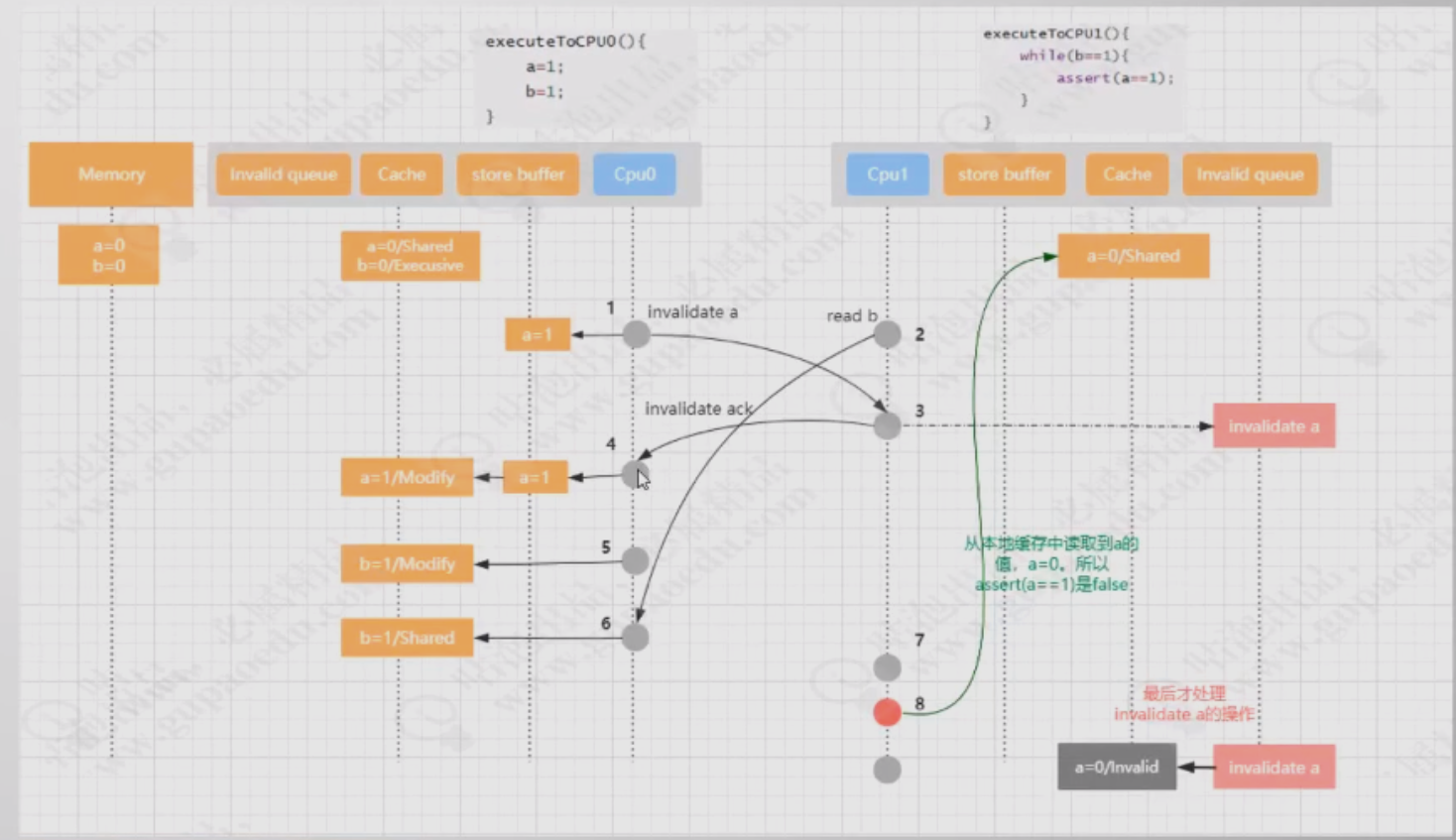
指令重排代码
由于缓存一致性问题,CPU层面做了优化,引入了缓存一致性协议。但是同时也导致了阻塞,因为缓存一致性协议的部分操作会阻塞。为了优化阻塞导致的性能问题,引入了Store Buffer异步机制,这就引来了指令重排。
缓存行
缓存是由缓存行组成的,通常是 64 字节(常用处理器的缓存行是 64 字节的,比较旧的处理器缓存行是 32 字节),并且它有效地引用主内存中的一块地址。
一个 Java 的 long 类型是 8 字节,因此在一个缓存行中可以存 8 个 long 类型的变量。
在程序运行的过程中,缓存每次更新都从主内存中加载连续的 64 个字节。
伪共享代码
如果访问一个 long 类型的数组时,当数组中的一个值被加载到缓存中时,另外 7 个元素也会被加载到缓存中。
但是,如果使用的数据结构中的项在内存中不是彼此相邻的,比如链表,那么将得不到免费缓存加载带来的好处。
不过,这种免费加载也有一个坏处。设想如果我们有个 long 类型的变量 a,它不是数组的一部分,而是一个单独的变量,并且还有另外一个 long 类型的变量 b 紧挨着它,那么当加载 a 的时候将免费加载 b。
看起来似乎没有什么毛病,但是如果一个 CPU 核心的线程在对 a 进行修改,另一个 CPU 核心的线程却在对 b 进行读取。
当前者修改 a 时,会把 a 和 b 同时加载到前者核心的缓存行中,更新完 a 后其它所有包含 a 的缓存行都将失效,因为其它缓存中的 a 不是最新值了。
而当后者读取 b 时,发现这个缓存行已经失效了,需要从主内存中重新加载。
请记住,我们的缓存都是以缓存行作为一个单位来处理的,所以失效 a 的缓存的同时,也会把 b 失效,反之亦然。
这样就出现了一个问题,b 和 a 完全不相干,每次却要因为 a 的更新需要从主内存重新读取,它被缓存未命中给拖慢了。
这就是传说中的伪共享。
当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
内存屏障
CPU在性能优化的过程中导致的顺序一致性问题,在CPU层面无法被解决,因为CPU只是一个运算工具,它只是接收命令和执行命令,并不清楚当前的逻辑是否需要优化,也就是说硬件层面无法优化这种顺序一致性带来的可见性问题。
在CPU层面提供了写屏障,读屏障,全屏障这样的指令来解决可见性问题。在X86架构中,这三种指令分别是SFENCE,LFENCE,MFENCE,即save fence,load fence, mix fence
在Linux系统中,这三个指令被封装成了三个方法smp_wmb,smp_rmb,smp_mb
JMM模型
JMM(java内存模型Java Memory Model)本身是一种抽象的概念,描述的是一组规则或规范。通过这组规范定义了程序中各个变量的访问方式。Java本身的运行是基于虚拟机的,在虚拟机的规范中,Java定义了一种内存模型,来屏蔽掉硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的内存访问效果。Java 线程之间的通信由 Java 内存模型(本文简称为 JMM)控制的。
Happens-before模型
告诉我们哪些场景不会存在可见性问题
-
规则一:程序顺序性规则(as-if-serial)
不管程序如何重排序,单线程的执行结果一定不会发生变化 -
规则二:传递性规则
如果 A Happens before B ,B Happens before C, 那么 A Happens Before C -
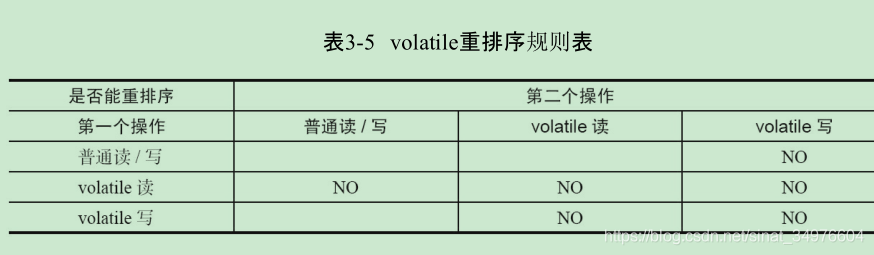
规则三:volatile重排序规则
![volatile重排序规则]()
-
规则四:监视器锁规则
简单来说就是在一段加锁的代码中修改了变量,释放锁后下一个线程进来则一定能获取到该变量最新值。 -
规则五:start规则
线程A在调用线程B的start之前做的修改,线程B搜可以获取到对应修改 -
join规则
欢迎大家留言,以便于后面的人更快解决问题!另外亦欢迎大家可以关注我的微信公众号,方便利用零碎时间互相交流。共勉!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号