
javaWeb中URLEncoder.encode编码需要调用两次
今天碰到一个问题,在Controller类中一个方法跳转到该类中的另一个方法,带着中文参数,在跳转之前对该参数进行编码:
msg = java.net.URLEncoder.encode(msg,"UTF-8");
ResponseData response = new ResponseData("redirect:/service/mxgl/"+typeid+"/"+cube.getDstype()+"/mxs?msg="+msg);
在另一个方法里接收该参数:
String msg = request.getParameter("msg");
if( msg != null){
msg = java.net.URLDecoder.decode(msg,"UTF-8");
view.addObject("msg",msg);
}
结果在前台显示乱码,百思不得其解,遂百度,终于知道原因:原来在服务器端用request.getParameter("msg")获取参数之前会自动做一次解码的工作,而且是默认的ISO-8859-1,相当于调用了一次java.net.URLDecoder.decode(msg, "ISO-8859-1"),难怪有乱码,这就相当于:
public static void main(String[] args) throws UnsupportedEncodingException {
String name="测试";
//UTF-8编码
name=java.net.URLEncoder.encode(name,"UTF-8");
System.out.println(name);
//ISO-8859-1解码
name=java.net.URLDecoder.decode(name, "ISO-8859-1");
System.out.println(name);
//UTF-8解码
System.out.println(java.net.URLDecoder.decode(name, "UTF-8"));
}
结果:
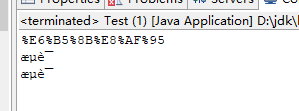
解决方案是对要传的中文参数进行两次编码,这就相当于:
public static void main(String[] args) throws UnsupportedEncodingException {
String name="测试";
//UTF-8编码
name=java.net.URLEncoder.encode(name,"UTF-8");
System.out.println(name);
//UTF-8编码
name=java.net.URLEncoder.encode(name,"UTF-8");
System.out.println(name);
//ISO-8859-1解码
name=java.net.URLDecoder.decode(name, "ISO-8859-1");
System.out.println(name);
//UTF-8解码
System.out.println(java.net.URLDecoder.decode(name, "UTF-8"));
}
结果:
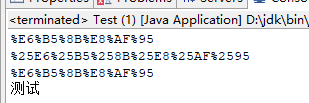
这样就解决了乱码问题。另外你可能有个疑问,为什么用UTF-8编码两次,然后分别用ISO-8859-1和UTF-8解码没问题呢?不应该是UTF-8解码两次无乱码问题吗?那是因为第一次编码后将汉字编码为%和字母数字的格式,而第二次编码的时候是对%和字母数字进行编码,虽然解码的时候使用的是ISO-8859-1,但是对于%和字母数字而言用ISO-8859-1和UTF-8解码出来的是一样的,此时就回到了汉字被编码过一次的字符串了,当再次进行解码的时候使用UTF-8就回将它转会汉字。
身体是革命的本钱,爱跑步,爱生活!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号