
LinkedHashMap做缓存
项目上需要写一个缓存,这样就不需要频繁地访问数据库,我使用的是

//缓存
private final Map<String, JSONArray> schemaCache = new LinkedHashMap<String, JSONArray>(134,0.75f,true) {
private static final long serialVersionUID = 1L;
@Override
protected boolean removeEldestEntry(
Entry<String, JSONArray> eldest) {
return size() > 100;
}
};
基本思想是LRU(last recently used)算法,即最近最少使用的。LinkedHashMap类简直是为其量身打造的。
先介绍何为LRU,LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:
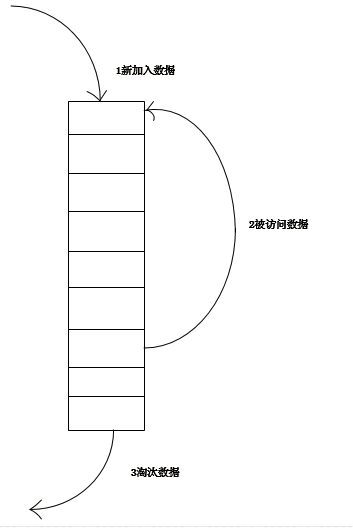
1. 新数据插入到链表头部;
2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3. 当链表满的时候,将链表尾部的数据丢弃。
LinkedHashMap是如何实现LRU的呢?,核心是访问排序。
首先讲下什么是访问排序? 什么是插入排序?
插入排序就是你put的时候的顺序是什么,取出来的时候就是什么样子。
package test;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Map.Entry;
public class Test
{
public static void main(String[] args) {
//构造函数的第三个参数,false为插入排序,true则为访问排序
LinkedHashMap<String, String> map = new LinkedHashMap<String, String>(15,0.8f,false){
@Override
protected boolean removeEldestEntry(Entry<String, String> eldest) {
return this.size() > 10;
}
private static final long serialVersionUID = 1L;;
};
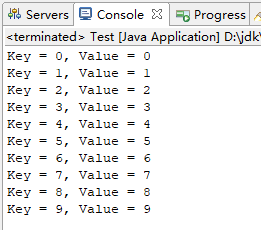
for(int i=0; i < 10; i++) {
map.put("" + i, i+"");
}
String s = map.get("2");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue());
}
}
}
结果:
访问排序就是你get的时候,会改变元素的顺序,会把该元素移到数据的末尾。(超过最大容量是删掉的是数据头部的元素)(将上面构造函数的第三个参数改成true)
结果: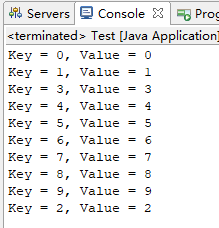
身体是革命的本钱,爱跑步,爱生活!

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步