
HTTP协议
一、简介
浏览器与Web服务器之间的一问一答的交互过程遵循一定的规则,这个规则就是HTTP协议。HTTP是HyperText Transfer Protocol(超文本传输协议)的英文缩写,它是TCP/IP协议集中地一个应用层协议,用于定义浏览器与Web服务器之间交互数据的过程以及数据本身的格式,现在被广泛使用的是HTTP1.1,相对于HTTP1.0而言,HTTP1.1的最大特点是支持持续连接。
二、HTTP1.0的会话方式
基于HTTP 1.0协议的客户机与服务器的信息交换过程包括四个步骤:建立连接;发送请求信息;回送响应信息;关闭连接。每次连接只处理一个请求和响应,即使对同一个网站的每一个页面的访问,浏览器与Web服务器都要建立一次单独的连接。当浏览器获得一个页面访问的结果后,浏览器断开与服务器的连接,当浏览器要访问服务器上的另一个网页时,又会重新建立与服务器的连接。所以HTTP协议是无状态的,上一次的响应结果并不会影响下一次请求的响应过程,不管在什么样的情况下,只要浏览器发出的请求信息完全一样,Web服务器的处理过程也就完全一样。
在浏览器与Web服务器之间还可以加入一个或多个的中间代理服务器,Web浏览器、代理服务器、Web服务器三者之间的拓扑关系如下:
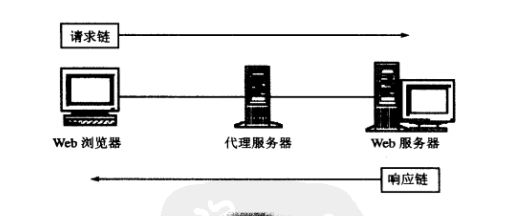
代理服务器接收到浏览器的请求后,如果其本地缓存中没有浏览器请求的资源,代理服务器随即向Web服务器请求此资源后返回给浏览器,并将资源内容保存到本地缓存中,以后再有浏览器访问该资源时,代理服务器将直接从本地缓存中取出保存的副本进行响应。相对于浏览器而言,代理服务器充当了服务器的角色,相对于Web服务器而言,代理服务器就像浏览器一样充当了客户机的角色。在Web服务器前端使用多个代理服务器与浏览器进行通信,可以有效地减少Web服务器的访问负载,但应充分考虑网页的有效性,即代理服务器中缓存的页面在Web服务器端是最新的、没有再被更改的。HTTP协议也定义了一些与代理服务器有关的内容,譬如,浏览器可以要求代理服务器必须重新到Web服务器上获取请求的资源,而不是使用代理服务器本地缓存中的副本进行响应。
三、HTTP 1.1与HTTP 1.0的比较
HTTP 1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务期完成请求处理后立即断开TCP连接,服务器不跟踪每个客户机,也不记录过去的请求。这就造成了性能上的缺陷。比如,一个包含很多图片(只指明了URL地址),引入外部js或css的网页,需要多次请求连接和关闭。耗时并且影响性能。
- 为了克服上面的缺陷,HTTP 1.1支持持久连接。在同个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗的延迟。
- HTTP 1.1还允许客户端不用等待上次的请求结果返回,就可以发送下一次请求,但服务器端必须按照接收到客户端请求的先后顺序依次返回响应结果,以便保证客户端能够区分出每次请求的响应内容,这样也显著地减少了整个下载过程所需要的时间,这个功能称之为Pipeline(管道线)。
- HTTP 1.1还通过增加更多的请求头和响应头来改进和扩充HTTP 1.0的功能。例如:由于HTTP 1.0不支持Host请求头字段,浏览器无法使用主机名来明确表示要访问服务器上的哪个Web站点,在HTTP 1.1中增加Host请求头字段后,浏览器可以使用主机名来明确表示要访问服务器上的哪个Web站点,这才实现了在一台Web服务器上可以在同一个IP地址和端口号上使用不同的主机名来创建多个虚拟Web站点。HTTP 1.1的持续连接,也需要增加新的请求头来帮助实现,例如,Connection请求头的值为Keep-Alive时,客户端通知服务器返回本次请求结果后保持连接;Connection请求头的值为close时,客户端通知服务器返回本次请求结果后关闭连接。HTTP 1.1还提供了与身份认证、状态管理和Cache缓存等机制相关的请求头和响应头。
参考书籍:《深入体验Java_Web开发内幕-核心基础》

