【文献阅读】DANN:Domain-Adversarial Training of Neural Networks
DANN
参考:https://www.jianshu.com/p/73cfb4b31c8b
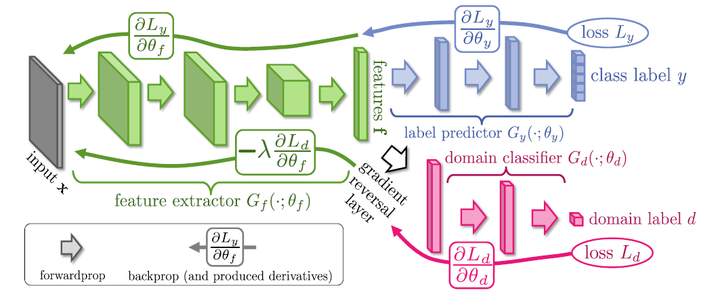
DANN的目的
通过对抗的方式可以提取domian无关的特征,从而实现domain adaption。这就是DANN(Domain-Adversarial Neural Networks)。
输入分为Source Domain和Target Domain
-
Source Domain:是原始训练数据,有标签
-
Target Domain: 是测试数据,没有标签
希望在提取特征后,source和target分不出差异。
DANN模型框架
这个模型有三部分:
label predictor(蓝色):对Source Domain进行训练,原论文是处理分类任务,所以就是让Source Domain的图片分类越正确越好
domain classifier(红色):二分类器,要让Domain的分类越正确越好,分类出是Source还是Target。
feature extractor(绿色):特征提取,站在label predictor这边,捅domain classifier一刀,做和domain classifier相反的事情。
-
将源域样本和目标域样本进行映射和混合,使域判别器无法区分数据来自哪个域;
-
提取后续网络完成任务所需要的特征,使标签预测器能够分辨出来自源域数据的类别。
为什么要GRL?
其中域分类器和特征提取器中间有一个梯度反转层(Gradient reversal layer)。梯度反转层顾名思义将梯度乘一个负数,然后进行反向传播。加入GRL的目的是为了让域判别器和特征提取器之间形成一种对抗。
feature extractor,它要提取一个供B和P共享的feature,这个feature有两个目标:
- 最小化目标loss \(L_y\),即label predictor分类越准确;
- 最大化loss \(L_d\),这样就可以尽可能的让两个domain分不开,feature自己就渐渐趋于域自适应了。
其中第二个目标就是用GRL实现的。loss \(L_d\)在domain classifier中是很小的,但通过GRL后,就实现在feature extractor中不能正确的判断出信息来自哪一个域。
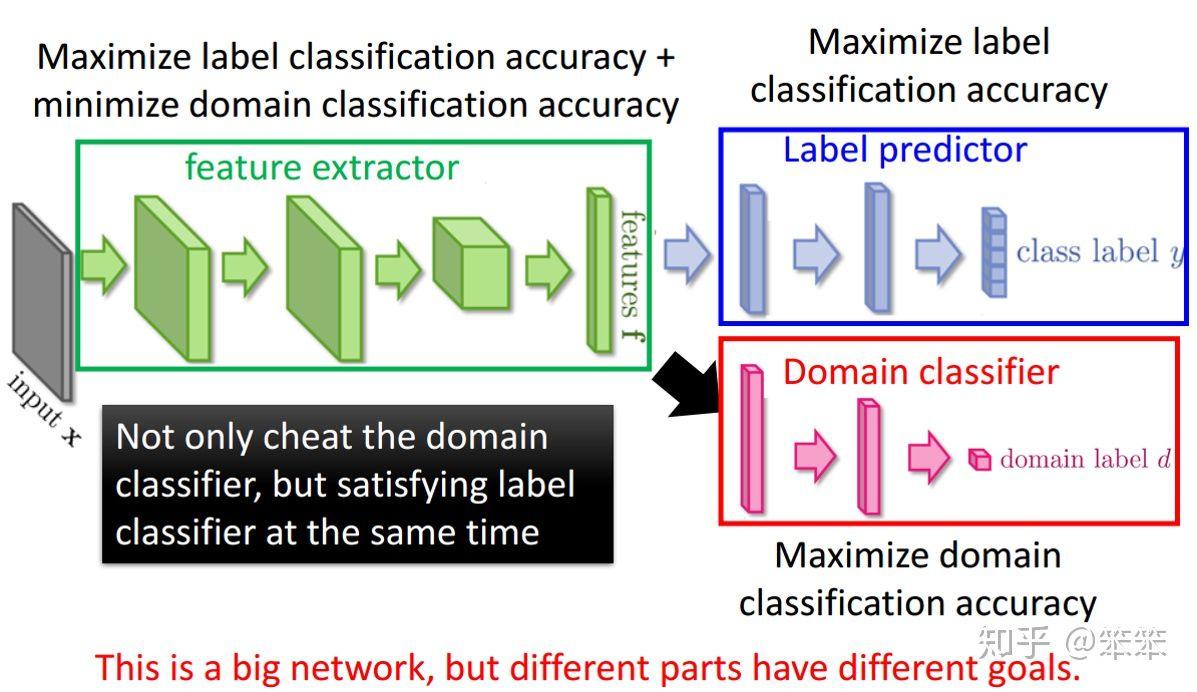
总结
特征提取器的目标是最大化标签分类的精确度,最小化域分类器的精确度。域分类器的目标是最大化域分类的精确度,所以特征提取器和域判别器在进行对抗。最后特征提取器获得的是域无关的信息。
Outlook
问题1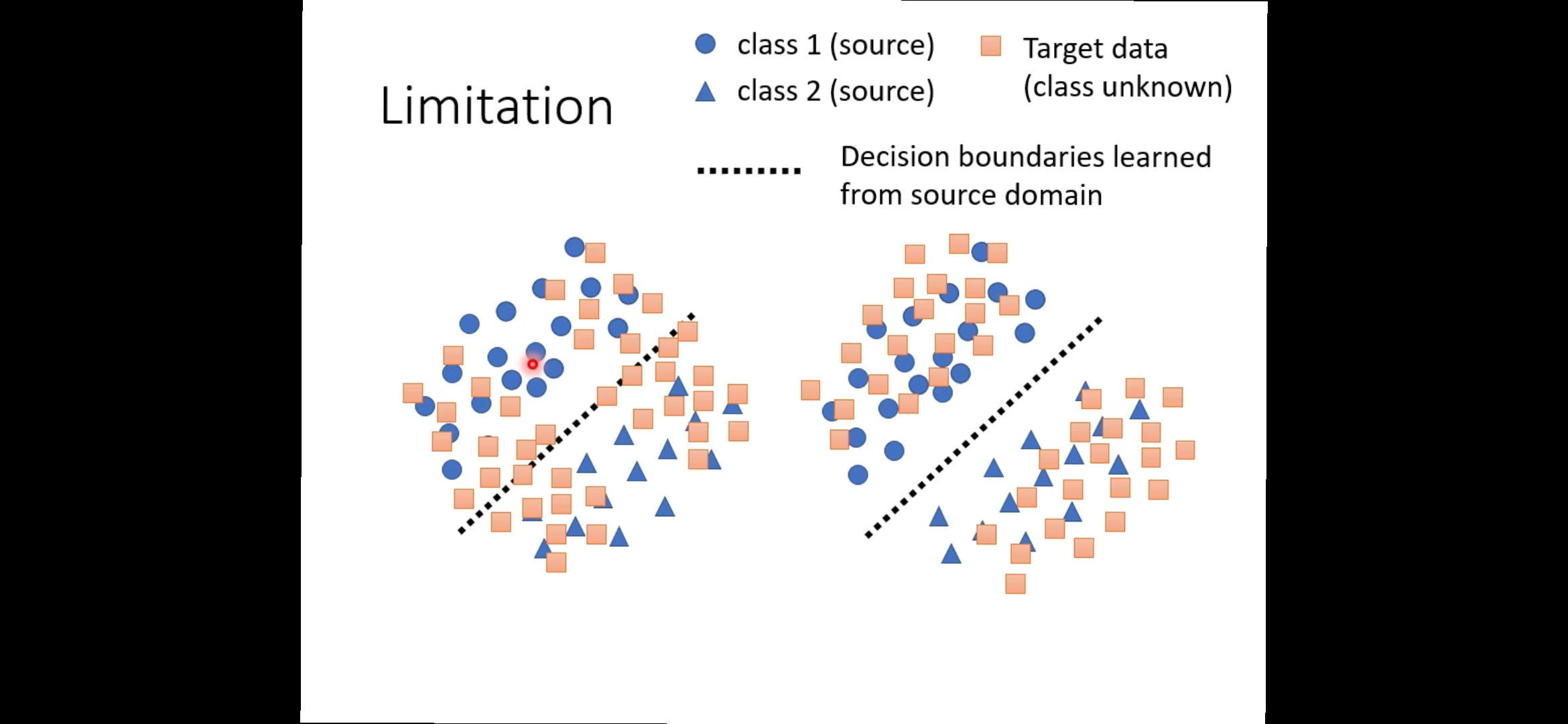
怎么使Target Domain和Source Domain越接近越好的同时,让Target Domain的分类也明确?
其中的一种做法:dirt-t

 浙公网安备 33010602011771号
浙公网安备 33010602011771号