MySQL数据库优化
思想:一切优化从业务为出发点
思路:
建议:根据OSI7层模型,从下往上进行优化。
一:物理层面
1、cpu 2-16个 2*4双四核,L1L2越大越好
2、内存 越大越好
3、磁盘 SAS或者固态 300G*12磁盘越多IO越高
raid 0>10>5>1
4、网卡 千兆
5、slave的配置最好大于等于master
二:系统层面
net.ipv4.tcp_fin_timeout = 2 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_keepalive_time =600 net.ipv4.ip_local_port_range = 4000 65000 net.ipv4.tcp_max_syn_backlog = 16384 net.ipv4.tcp_max_tw_buckets = 36000 net.ipv4.route.gc_timeout = 100 net.ipv4.tcp_syn_retries = 1 net.ipv4.tcp_synack_retries = 1 net.core.somaxconn = 16384 net.core.netdev_max_backlog = 16384 net.ipv4.tcp_max_orphans = 16384 vm.swappiness=0 尽量不使用swap vm.dirty_backgroud_ratio 5-10 vm.dirty_ratio 上面的值的两倍 将操作系统的脏数据刷到磁盘 |
三:mysql的安装
MySQL数据库的线上环境安装,我建议采取编译安装的方式,这样性能会有较大的提升。服务器系统则建议CentOS6.7 X86_64,源码包的编译参数会默认以Debug模式生成二进制代码,而Debug模式给MySQL带来的性能损失是比较大的,所以当我们编译准备安装的产品代码时,一定不要忘记使用--without-debug参数禁止Debug模式。如果把--with-mysqld-ldflags和--with-client-ld-flags两个编译参数设置为--all-static的话,可以告诉编译器以静态的方式编译,编译结果将得到最高的性能。使用静态编译和使用动态编译的代码相比,性能差距可能会达到5%至10%之多。在后面我会跟大家分享我们线上MySQL数据库的编译参数,大家可以参考下,然后根据自己的线上环境自行修改内容。
[client]port = 3306# 客户端端口号为3306socket = /data/3306/mysql.sockdefault-character-set = utf8# 客户端字符集,(控制character_set_client、character_set_connection、character_set_results)[mysql]no-auto-rehash# 仅仅允许使用键值的updates和deletes[mysqld]# 组包括了mysqld服务启动的参数,它涉及的方面很多,其中有MySQL的目录和文件,通信、网络、信息安全,内存管理、优化、查询缓存区,还有MySQL日志设置等。user = mysql# mysql_safe脚本使用MySQL运行用户(编译时--user=mysql指定),推荐使用mysql用户。port = 3306# MySQL服务运行时的端口号。建议更改默认端口,默认容易遭受攻击。socket = /data/3306/mysql.sock# socket文件是在Linux/Unix环境下特有的,用户在Linux/Unix环境下客户端连接可以不通过TCP/IP网络而直接使用unix socket连接MySQL。basedir = /application/mysql# mysql程序所存放路径,常用于存放mysql启动、配置文件、日志等datadir = /data/3306/data# MySQL数据存放文件(极其重要)character-set-server = utf8# 数据库和数据库表的默认字符集。(推荐utf8,以免导致乱码)log-error=/data/3306/mysql.err# mysql错误日志存放路径及名称(启动出现错误一定要看错误日志,百分之百都能通过错误日志排插解决。)pid-file=/data/3306/mysql.pid# MySQL_pid文件记录的是当前mysqld进程的pid,pid亦即ProcessID。skip-locking# 避免MySQL的外部锁定,减少出错几率,增强稳定性。skip-name-resolv# 禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析的时候。但是需要注意的是,如果开启该选项,则所有远程主机连接授权都要使用IP地址方式了,否则MySQL将无法正常处理连接请求!skip-networking# 开启该选项可以彻底关闭MySQL的TCP/IP连接方式,如果Web服务器是以远程连接的方式访问MySQL数据库服务器的,则不要开启该选项,否则无法正常连接!open_files_limit = 1024# MySQLd能打开文件的最大个数,如果出现too mant open files之类的就需要调整该值了。back_log = 384# back_log参数是值指出在MySQL暂时停止响应新请求之前,短时间内的多少个请求可以被存在堆栈中。如果系统在短时间内有很多连接,则需要增加该参数的值,该参数值指定到来的TCP/IP连接的监听队列的大小。不同的操作系统在这个队列的大小上有自己的限制。如果试图将back_log设置得高于操作系统的限制将是无效的,其默认值为50.对于Linux系统而言,推荐设置为小于512的整数。max_connections = 800# 指定MySQL允许的最大连接进程数。如果在访问博客时经常出现 Too Many Connections的错误提示,则需要增大该参数值。max_connect_errors = 6000# 设置每个主机的连接请求异常中断的最大次数,当超过该次数,MySQL服务器将禁止host的连接请求,直到MySQL服务器重启或通过flush hosts命令清空此host的相关信息。wait_timeout = 120# 指定一个请求的最大连接时间,对于4GB左右内存的服务器来说,可以将其设置为5~10。table_cache = 614K# table_cache指示表高速缓冲区的大小。当MySQL访问一个表时,如果在MySQL缓冲区还有空间,那么这个表就被打开并放入表缓冲区,这样做的好处是可以更快速地访问表中的内容。一般来说,可以查看数据库运行峰值时间的状态值Open_tables和Open_tables,用以判断是否需要增加table_cache的值,即如果Open_tables接近table_cache的时候,并且Opened_tables这个值在逐步增加,那就要考虑增加这个值的大小了。external-locking = FALSE# MySQL选项可以避免外部锁定。True为开启。max_allowed_packet =16M# 服务器一次能处理最大的查询包的值,也是服务器程序能够处理的最大查询sort_buffer_size = 1M# 设置查询排序时所能使用的缓冲区大小,系统默认大小为2MB。# 注意:该参数对应的分配内存是每个连接独占的,如果有100个连接,那么实际分配的总排序缓冲区大小为100 x6=600MB。所以,对于内存在4GB左右的服务器来说,推荐将其设置为6MB~8MBjoin_buffer_size = 8M# 联合查询操作所能使用的缓冲区大小,和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享。thread_cache_size = 64# 设置Thread Cache池中可以缓存的连接线程最大数量,可设置为0~16384,默认为0.这个值表示可以重新利用保存在缓存中线程的数量,当断开连接时如果缓存中还有空间,那么客户端的线程将被放到缓存中;如果线程重新被请求,那么请求将从缓存中读取,如果缓存中是空的或者是新的请求,那么这个线程将被重新创建,如果有很多线程,增加这个值可以改善系统性能。通过比较Connections和Threads_created状态的变量,可以看到这个变量的作用。我们可以根据物理内存设置规则如下:1GB内存我们配置为8,2GB内存我们配置为16,3GB我们配置为32,4GB或4GB以上我们给此值为64或更大的值。thread_concurrency = 8# 该参数取值为服务器逻辑CPU数量x 2,在本例中,服务器有两个物理CPU,而每个物理CPU又支持H.T超线程,所以实际取值为4 x 2 = 8。这也是双四核主流服务器的配置。query_cache_size = 64M# 指定MySQL查询缓冲区的大小。可以通过在MySQL控制台观察,如果Qcache_lowmem_prunes的值非常大,则表明经常出现缓冲不够的情况;如果Qcache_hits的值非常大,则表明查询缓冲使用得非常频繁。另外如果改值较小反而会影响效率,那么可以考虑不用查询缓冲。对于Qcache_free_blocks,如果该值非常大,则表明缓冲区中碎片很多。query_cache_limit = 2M# 只有小于此设置值的结果才会被缓存query_cache_min_res_unit = 2k# 设置查询缓存分配内存的最小单位,要适当第设置此参数,可以做到为减少内存快的申请和分配次数,但是设置过大可能导致内存碎片数值上升。默认值为4K,建议设置为1K~16K。default_table_type = InnoDB# 默认表的类型为InnoDBthread_stack = 256K# 设置MySQL每个线程的堆栈大小,默认值足够大,可满足普通操作。可设置范围为128KB至4GB,默认为192KB#transaction_isolation = Level# 数据库隔离级别 (READ UNCOMMITTED(读取未提交内容) READ COMMITTED(读取提交内容) REPEATABLEREAD(可重读) SERIALIZABLE(可串行化))tmp_table_size = 64M# 设置内存临时表最大值。如果超过该值,则会将临时表写入磁盘,其范围1KB到4GB。max_heap_table_size = 64M# 独立的内存表所允许的最大容量。table_cache = 614# 给经常访问的表分配的内存,物理内存越大,设置就越大。调大这个值,一般情况下可以降低磁盘IO,但相应的会占用更多的内存,这里设置为614。table_open_cache = 512# 设置表高速缓存的数目。每个连接进来,都会至少打开一个表缓存。因此, table_cache 的大小应与 max_connections 的设置有关。例如,对于 200 个并行运行的连接,应该让表的缓存至少有 200 × N ,这里 N 是应用可以执行的查询的一个联接中表的最大数量。此外,还需要为临时表和文件保留一些额外的文件描述符。long_query_time = 1# 慢查询的执行用时上限,默认设置是10s,推荐(1s~2s)log_long_format# 没有使用索引的查询也会被记录。(推荐,根据业务来调整)log-slow-queries = /data/3306/slow.log# 慢查询日志文件路径(如果开启慢查询,建议打开此日志)log-bin = /data/3306/mysql-bin# logbin数据库的操作日志,例如update、delete、create等都会存储到binlog日志,通过logbin可以实现增量恢复relay-log = /data/3306/relay-bin# relay-log日志记录的是从服务器I/O线程将主服务器的二进制日志读取过来记录到从服务器本地文件,然后SQL线程会读取relay-log日志的内容并应用到从服务器relay-log-info-file = /data/3306/relay-log.info# 从服务器用于记录中继日志相关信息的文件,默认名为数据目录中的relay-log.info。binlog_cache_size = 4M# 在一个事务中binlog为了记录sql状态所持有的cache大小,如果你经常使用大的,多声明的事务,可以增加此值来获取更大的性能,所有从事务来的状态都被缓冲在binlog缓冲中,然后再提交后一次性写入到binlog中,如果事务比此值大,会使用磁盘上的临时文件来替代,此缓冲在每个链接的事务第一次更新状态时被创建。max_binlog_cache_size = 8M# 最大的二进制Cache日志缓冲尺寸。max_binlog_size = 1G# 二进制日志文件的最大长度(默认设置1GB)一个二进制文件信息超过了这个最大长度之前,MySQL服务器会自动提供一个新的二进制日志文件接续上。expire_logs_days = 7# 超过7天的binlog,mysql程序自动删除(如果数据重要,建议不要开启该选项)key_buffer_size = 256M# 指定用于索引的缓冲区大小,增加它可得到更好的索引处理性能。对于内存在4GB左右的服务器来说,该参数可设置为256MB或384MB。# 注意:如果该参数值设置得过大反而会使服务器的整体效率降低!read_buffer_size = 4M# 读查询操作所能使用的缓冲区大小。和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享。read_rnd_buffer_size = 16M# 设置进行随机读的时候所使用的缓冲区。此参数和read_buffer_size所设置的Buffer相反,一个是顺序读的时候使用,一个是随机读的时候使用。但是两者都是针对与线程的设置,每个线程都可以产生两种Buffer中的任何一个。默认值256KB,最大值4GB。bulk_insert_buffer_size = 8M# 如果经常性的需要使用批量插入的特殊语句来插入数据,可以适当调整参数至16MB~32MB,建议8MB。myisam_sort_buffer_size = 8M# 设置在REPAIR Table或用Create index创建索引或 Alter table的过程中排序索引所分配的缓冲区大小,可设置范围4Bytes至4GB,默认为8MBlower_case_table_names = 1# 实现MySQL不区分大小。(发开需求-建议开启)slave-skip-errors = 1032,1062# 从库可以跳过的错误数字值(mysql错误以数字代码反馈,全的mysql错误代码大全,以后会发布至博客)。replicate-ignore-db=mysql# 在做主从的情况下,设置不需要同步的库。server-id = 1# 表示本机的序列号为1,如果做主从,或者多实例,serverid一定不能相同。myisam_sort_buffer_size = 128M# 当需要对于执行REPAIR, OPTIMIZE, ALTER 语句重建索引时,MySQL会分配这个缓存,以及LOAD DATA INFILE会加载到一个新表,它会根据最大的配置认真的分配的每个线程。myisam_max_sort_file_size = 10G# 当重新建索引(REPAIR,ALTER,TABLE,或者LOAD,DATA,TNFILE)时,MySQL被允许使用临时文件的最大值。myisam_repair_threads = 1# 如果一个表拥有超过一个索引, MyISAM 可以通过并行排序使用超过一个线程去修复他们.myisam_recover# 自动检查和修复没有适当关闭的 MyISAM 表.innodb_additional_mem_pool_size = 4M# 用来设置InnoDB存储的数据目录信息和其他内部数据结构的内存池大小。应用程序里的表越多,你需要在这里面分配越多的内存。对于一个相对稳定的应用,这个参数的大小也是相对稳定的,也没有必要预留非常大的值。如果InnoDB用广了这个池内的内存,InnoDB开始从操作系统分配内存,并且往MySQL错误日志写警告信息。默认为1MB,当发现错误日志中已经有相关的警告信息时,就应该适当的增加该参数的大小。innodb_buffer_pool_size = 64M# InnoDB使用一个缓冲池来保存索引和原始数据,设置越大,在存取表里面数据时所需要的磁盘I/O越少。强烈建议不要武断地将InnoDB的Buffer Pool值配置为物理内存的50%~80%,应根据具体环境而定。innodb_data_file_path = ibdata1:128M:autoextend# 设置配置一个可扩展大小的尺寸为128MB的单独文件,名为ibdata1.没有给出文件的位置,所以默认的是在MySQL的数据目录内。innodb_file_io_threads = 4# InnoDB中的文件I/O线程。通常设置为4,如果是windows可以设置更大的值以提高磁盘I/Oinnodb_thread_concurrency = 8# 你的服务器有几个CPU就设置为几,建议用默认设置,一般设为8。innodb_flush_log_at_trx_commit = 1# 设置为0就等于innodb_log_buffer_size队列满后在统一存储,默认为1,也是最安全的设置。innodb_log_buffer_size = 2M# 默认为1MB,通常设置为8~16MB就足够了。innodb_log_file_size = 32M# 确定日志文件的大小,更大的设置可以提高性能,但也会增加恢复数据库的时间。innodb_log_files_in_group = 3# 为提高性能,MySQL可以以循环方式将日志文件写到多个文件。推荐设置为3。innodb_max_dirty_pages_pct = 90# InnoDB主线程刷新缓存池中的数据。innodb_lock_wait_timeout = 120# InnoDB事务被回滚之前可以等待一个锁定的超时秒数。InnoDB在它自己的锁定表中自动检测事务死锁并且回滚事务。InnoDB用locak tables 语句注意到锁定设置。默认值是50秒。innodb_file_per_table = 0# InnoDB为独立表空间模式,每个数据库的每个表都会生成一个数据空间。0关闭,1开启。# 独立表空间优点:# 1、每个表都有自己独立的表空间。# 2 、每个表的数据和索引都会存在自己的表空间中。# 3、可以实现单表在不同的数据库中移动。# 4、空间可以回收(除drop table操作处,表空不能自己回收。)
[mysqldump]quick
max_allowed_packet = 2M# 设定在网络传输中一次消息传输量的最大值。系统默认值为1MB,最大值是1GB,必须设置为1024的倍数。单位为字节。
建议:
强烈建议不要武断地将InnoDB的Buffer Pool值配置为物理内存的50%~80%,应根据具体环境而定。
如果key_reads太大,则应该把my.cnf中的key_buffer_size变大,保持key_reads/key_read_re-quests至少在1/100以上,越小越好。
如果qcache_lowmem_prunes很大,就要增加query_cache_size的值。
不过很多时候需要具体情况具体分析,其他参数的变更我们可以等MySQL上线稳定一段时间后在根据status值进行调整。
范例
一份电子商务网站MySQL数据库调整后所运行的配置文件/etc/my.cnf(服务器为DELL R710、16GB内存、RAID10),大家可以根据实际的MySQL数据库硬件情况进行调整配置文件如下:
[client]port = 3306socket = /data/3306/mysql.sockdefault-character-set = utf8[mysqld]user = mysqlport = 3306character-set-server = utf8socket = /data/3306/mysql.sockbasedir = /application/mysqldatadir = /data/3306/datalog-error=/data/3306/mysql_err.logpid-file=/data/3306/mysql.pidlog_slave_updates = 1log-bin = /data/3306/mysql-binbinlog_format = mixedbinlog_cache_size = 4Mmax_binlog_cache_size = 8Mmax_binlog_size = 1Gexpire_logs_days = 90binlog-ignore - db = mysqlbinlog-ignore - db = information_schemakey_buffer_size = 384Msort_buffer_size = 2Mread_buffer_size = 2Mread_rnd_buffer_size = 16Mjoin_buffer_size = 2Mthread_cache_size = 8query_cache_size = 32Mquery_cache_limit = 2Mquery_cache_min_res_unit = 2kthread_concurrency = 32table_cache = 614table_open_cache = 512open_files_limit = 10240back_log = 600max_connections = 5000max_connect_errors = 6000external-locking = FALSEmax_allowed_packet =16Mthread_stack = 192Ktransaction_isolation = READ-COMMITTEDtmp_table_size = 256Mmax_heap_table_size = 512Mbulk_insert_buffer_size = 64Mmyisam_sort_buffer_size = 64Mmyisam_max_sort_file_size = 10Gmyisam_repair_threads = 1myisam_recoverlong_query_time = 2slow_query_logslow_query_log_file = /data/3306/slow.logskip-name-resolvskip-lockingskip-networkingserver-id = 1innodb_additional_mem_pool_size = 16Minnodb_buffer_pool_size = 512Minnodb_data_file_path = ibdata1:256M:autoextendinnodb_file_io_threads = 4innodb_thread_concurrency = 8innodb_flush_log_at_trx_commit = 2innodb_log_buffer_size = 16Minnodb_log_file_size = 128Minnodb_log_files_in_group = 3innodb_max_dirty_pages_pct = 90innodb_lock_wait_timeout = 120innodb_file_per_table = 0[mysqldump]quickmax_allowed_packet = 64M[mysql]no – auto - rehash
四:存储引擎的选择
五:线上优化调整
MySQL数据库上线后,可以等其稳定运行一段时间后再根据服务器的status状态进行适当优化,我们可以用如下命令列出MySQL服务器运行的各种状态值。通过命令:show global status; 也可以通过 show status like '查询%';
1、慢查询
有时我们为了定位系统中效率比较低下的Query语法,需要打开慢查询日志,也就是Slow Query log。打开慢查询日志的相关命令如下:
mysql>show variables like '%slow%';+---------------------+-----------------------------------------+|Variable_name | Value |+---------------------+-----------------------------------------+|log_slow_queries | ON ||slow_launch_time | 2 |+---------------------+-----------------------------------------+mysql>show global status like '%slow%';+---------------------+-------+|Variable_name | Value |+---------------------+-------+|Slow_launch_threads | 0 ||Slow_queries | 2128 |+---------------------+-------+
2、连接数
我们如果经常遇见MySQL:ERROR1040:Too many connections的情况,一种情况是访问量确实很高,MySQL服务器扛不住了,这个时候就要考虑增加从服务器分散读压力,从架构层面。另外一种情况是MySQL配置文件中max_connections的值过小。来看一个例子。
mysql> show variables like 'max_connections';+-----------------+-------+|Variable_name | Value |+-----------------+-------+|max_connections | 800 |+-----------------+-------+#### 这台服务器最大连接数是256,然后查询一下该服务器响应的最大连接数;mysql> show global status like 'Max_used_connections';+----------------------+-------+|Variable_name | Value |+----------------------+-------+|Max_used_connections | 245 |+----------------------+-------+#### MySQL服务器过去的最大连接数是245,没有达到服务器连接数的上线800,不会出现1040错误。#### Max_used_connections /max_connections * 100% = 85%#### 最大连接数占上限连接数的85%左右,如果发现比例在10%以下,则说明MySQL服务器连接数的上限设置得过高了。
3.key_buffer_size
key_buffer_size是设置MyISAM表索引缓存空间的大小,此参数对MyISAM表性能影响最大。下面是一台MyISAM为主要存储引擎服务器的配置:
mysql> show variables like 'key_buffer_size';+-----------------+-----------+|Variable_name | Value |+-----------------+-----------+|key_buffer_size | 536870912 |+-----------------+-----------+#### 从上面可以看出,分配了512MB内存给key_buffer_size。再来看key_buffer_size的使用情况:mysql> show global status like 'key_read%';+-------------------+--------------+|Variable_name | Value |+-------------------+-------+|Key_read_requests | 27813678766 ||Key_reads | 6798830|+-------------------+--------------+
4.临时表
当执行语句时,关于已经被创建了隐含临时表的数量,我们可以用如下命令查询其具体情况:
mysql> show global status like 'created_tmp%';+-------------------------+----------+|Variable_name | Value |+-------------------------+----------+|Created_tmp_disk_tables | 21119 ||Created_tmp_files | 6 ||Created_tmp_tables | 17715532 |+-------------------------+----------+- #### MySQL服务器对临时表的配置:
mysql> show variables where Variable_name in ('tmp_table_size','max_heap_table_size');+---------------------+---------+|Variable_name | Value |+---------------------+---------+|max_heap_table_size | 2097152 ||tmp_table_size | 2097152 |+---------------------+---------+
5.打开表的情况
mysql> show global status like 'open%tables%';+---------------+-------+|Variable_name | Value |+---------------+-------+|Open_tables | 351 ||Opened_tables | 1455 |#### 查询下服务器table_open_cache;mysql> show variables like 'table_open_cache';+------------------+-------+|Variable_name | Value |+------------------+-------+|table_open_cache | 2048 |+------------------+-------+
6.进程使用情况
mysql> show global status like 'thread%';+-------------------+-------+|Variable_name | Value |+-------------------+-------+|Threads_cached | 40||Threads_connected | 1 ||Threads_created | 330 ||Threads_running | 1 |+-------------------+-------+#### 查询服务器thread_cache_size配置如下:mysql> show variables like 'thread_cache_size';+-------------------+-------+|Variable_name | Value |+-------------------+-------+|thread_cache_size | 100 |+-------------------+-------+
7.查询缓存(query cache)
mysql> show global status like 'qcache%';+-------------------------+-----------+|Variable_name | Value |+-------------------------+-----------+|Qcache_free_blocks | 22756 ||Qcache_free_memory | 76764704 ||Qcache_hits | 213028692 ||Qcache_inserts | 208894227 ||Qcache_lowmem_prunes | 4010916 ||Qcache_not_cached | 13385031 ||Qcache_queries_in_cache | 43560 ||Qcache_total_blocks | 111212 |+-------------------------+-----------+
MySQL查询缓存变量的相关解释如下:
query_cache的配置命令:
mysql> show variables like 'query_cache%';+------------------------------+---------+|Variable_name | Value |+------------------------------+---------+|query_cache_limit | 1048576 ||query_cache_min_res_unit | 2048 ||query_cache_size | 2097152 ||query_cache_type | ON ||query_cache_wlock_invalidate | OFF |+------------------------------+---------+
字段解释如下:
8.排序使用情况
mysql> show global status like 'sort%';+-------------------+----------+|Variable_name | Value |+-------------------+----------+|Sort_merge_passes | 10 ||Sort_range | 37431240 ||Sort_rows | 6738691532 ||Sort_scan | 1823485 |+-------------------+----------+
9.文件打开数(open_files)
show global status like 'open_files';+---------------+-------+|Variable_name | Value |+---------------+-------+|Open_files | 1481 |+---------------+-------+mysql> show global status like 'open_files_limit';+------------------+-------+|Variable_name | Value |+------------------+--------+|Open_files_limit | 4509 |+------------------+--------+
10.InnoDB_buffer_pool_cache合理设置
很多时候我们会发现,通过参数设置进行性能优化所带来的性能提升,并不如许多人想象的那样会产生质的飞跃,除非是之前的设置存在严重不合理的情况。我们不能将性能调优完全依托与通过DBA在数据库上线后进行参数调整,而应该在系统设计和开发阶段就尽可能减少性能问题。(重点在于前期架构合理的设计及开发的程序合理)
六:MySQL数据库的可扩展架构方案
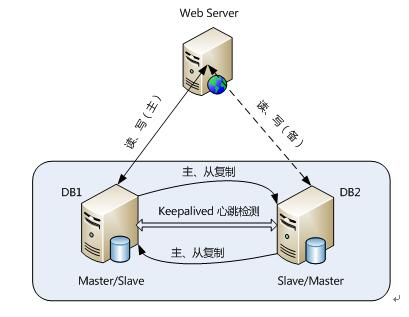
1、主从复制解决方案
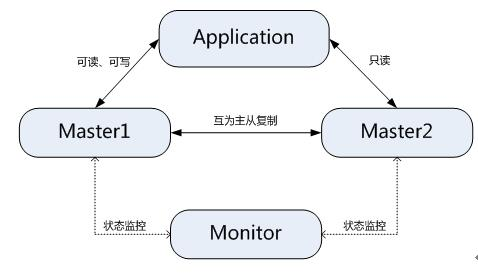
2、MMM/MHA高可用解决方案
3、Heartbeat/SAN高可用解决方案
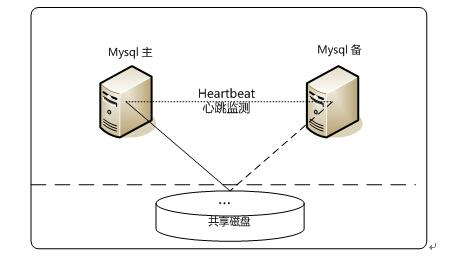
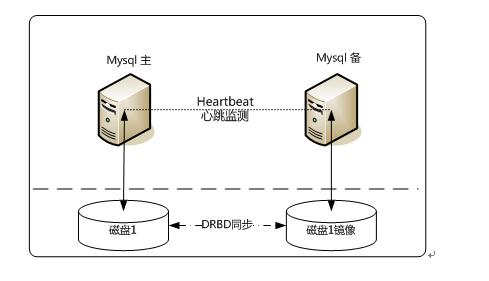
4、Heartbeat/DRBD高可用解决方案
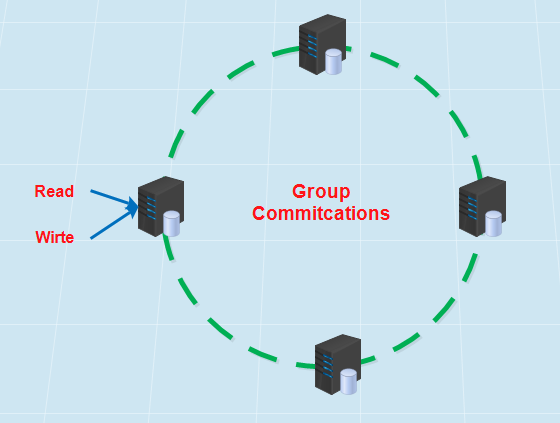
5、percona xtradb cluster
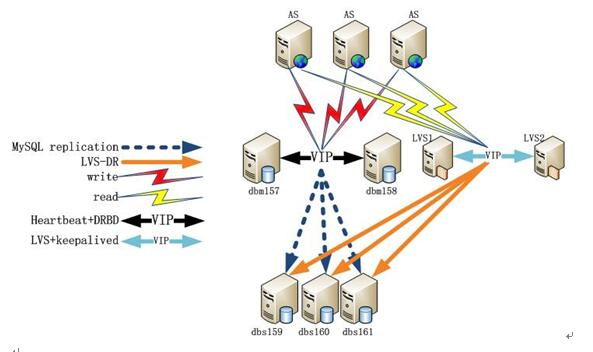
MYSQL经典应用架构