docker+mesos+marathon
前言
一、熟知mesos
1.1 mesos中的基本术语解释
Mesos-master:Mesos master,主要负责管理各个framework和slave,并将slave上的资源分配给各个framework
Mesos-slave:Mesos slave,负责管理本节点上的各个mesos-task,比如:为各个executor分配资源
Framework:计算框架,如:Hadoop,Spark等,通过MesosSchedulerDiver接入Mesos
Executor:执行器,安装到mesos-slave上,用于启动计算框架中的task。
Mesos-master是整个系统的核心,负责管理接入mesos的各个framework(由frameworks_manager管理)和 slave(由slaves_manager管理),并将slave上的资源按照某种策略分配给framework(由独立插拔模块Allocator管 理)。
Mesos-slave负责接收并执行来自mesos-master的命令、管理节点上的mesos-task,并为各个task分配资源。 mesos-slave将自己的资源量发送给mesos-master,由mesos-master中的Allocator模块决定将资源分配给哪个 framework,当前考虑的资源有CPU和内存两种,也就是说,mesos-slave会将CPU个数和内存量发送给mesos-master,而用 户提交作业时,需要指定每个任务需要的CPU个数和内存量,这样,当任务运行时,mesos-slave会将任务放到包含固定资源的linux container中运行,以达到资源隔离的效果。很明显,master存在单点故障问题,为此,mesos采用了zookeeper解决该问题。
Framework是指外部的计算框架,如Hadoop,Mesos等,这些计算框架可通过注册的方式接入mesos,以便mesos进行统一管理 和资源分配。Mesos要求可接入的框架必须有一个调度器模块,该调度器负责框架内部的任务调度。当一个framework想要接入mesos时,需要修 改自己的调度器,以便向mesos注册,并获取mesos分配给自己的资源, 这样再由自己的调度器将这些资源分配给框架中的任务,也就是说,整个mesos系统采用了双层调度框架:第一层,由mesos将资源分配给框架;第二层, 框架自己的调度器将资源分配给自己内部的任务。当前Mesos支持三种语言编写的调度器,分别是C++,java和python,为了向各种调度器提供统 一的接入方式,Mesos内部采用C++实现了一个MesosSchedulerDriver(调度器驱动器),framework的调度器可调用该 driver中的接口与Mesos-master交互,完成一系列功能(如注册,资源分配等)。
Executor主要用于启动框架内部的task。由于不同的框架,启动task的接口或者方式不同,当一个新的框架要接入mesos时,需要编写 一个executor,告诉mesos如何启动该框架中的task。为了向各种框架提供统一的执行器编写方式,Mesos内部采用C++实现了一个 MesosExecutorDiver(执行器驱动器),framework可通过该驱动器的相关接口告诉mesos启动task的方法。
1.2 总体架构
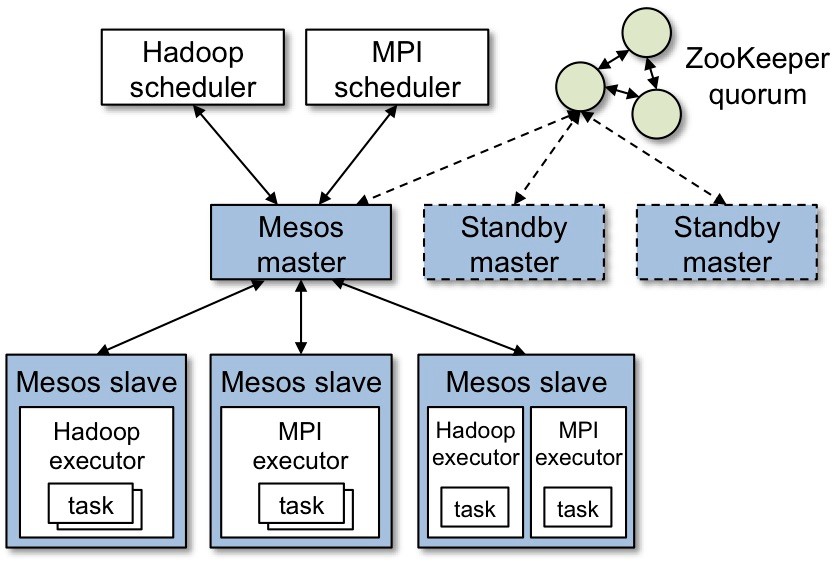
1.3 资源提供的例子

1)slave 1 报告给master他拥有4核cpu和4G剩余内存,matser调用allocation政策模块,告诉salve 1 计算框架1应该被提供可用的资源。
2)master给计算框架1发送一个在slave1上可用的资源描述。
3)计算框架的调度器回复给master运行在slave上两个任务的相关信息,任务1需使用2个cpu,内存1G,任务2需使用1个cpu,2G内存。
4)最后,master发送任务给slave,分配适当的给计算框架执行器,继续发起两个任务(图上虚线处),因为仍有1个cpu和1G内存未分配,allocation模块现在或许提供剩下的资源给计算框架2。
除此之外,当任务完成,新的资源成为空闲时,这个资源提供程序将会重复。
二、学习zookeeper
2.1 Zookeeper简介
ZooKeeper是用来给集群服务维护配置信息,域名服务,提供分布式同步和提供组服务。所有这些类型的服务都使用某种形式的分布式应用程序。是一个分布式的,开放源码的协调服务,是的Chubby一个的实现,是Hadoop和Hbase的重要组件。
2.2角色
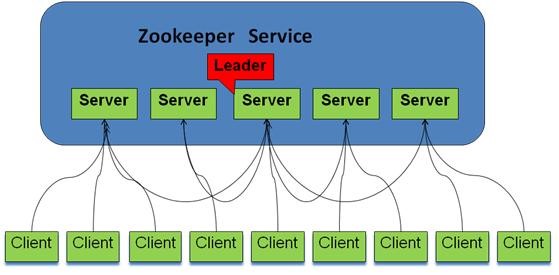
跟随者(follwoer):follower用于接收客户请求并向客户端返回结果,在选主过程中参与投票
观察者:ObServer可以接受客户端连接,将写请求转发给leader节点,但ObServer不参加投票过程,只同步leader的状态,ObServer的目的是为了拓展系统,提高读取速度。
客户端:请求发起方
2.3 ZooKeeper的工作原理
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
每个Server在工作过程中有三种状态:
- LOOKING:当前Server不知道leader是谁,正在搜寻
- LEADING:当前Server即为选举出来的leader
- FOLLOWING:leader已经选举出来,当前Server与之同步
2.4 选主流程
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的Server都恢复到一个正确的状态。Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。先介绍basic paxos流程:
1)选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
2)选举线程首先向所有Server发起一次询问(包括自己);
3)选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
4)收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
5)线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数, 设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。
通过流程分析我们可以得出:要使Leader获得多数Server的支持,则Server总数必须是奇数2n+1,且存活的Server的数目不得少于n+1.
每个Server启动后都会重复以上流程。在恢复模式下,如果是刚从崩溃状态恢复的或者刚启动的server还会从磁盘快照中恢复数据和会话信息,zk会记录事务日志并定期进行快照,方便在恢复时进行状态恢复。选主的具体流程图如下所示:
fast paxos流程是在选举过程中,某Server首先向所有Server提议自己要成为leader,当其它Server收到提议以后,解决epoch和zxid的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息,重复这个流程,最后一定能选举出Leader。其流程图如下所示: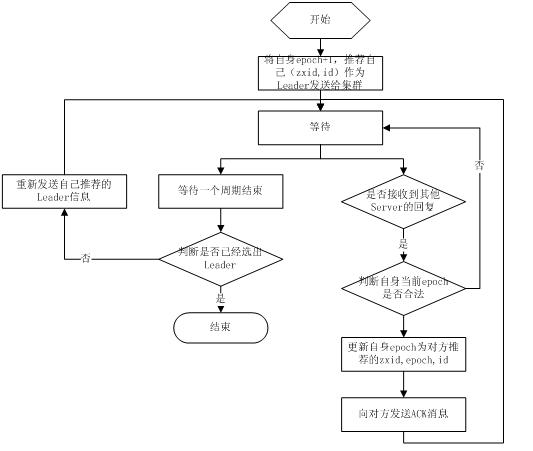
2.5 同步流程
选完leader以后,zk就进入状态同步过程。
1)leader等待server连接;
2)Follower连接leader,将最大的zxid发送给leader;
3)Leader根据follower的zxid确定同步点;
4)完成同步后通知follower 已经成为uptodate状态;
5)Follower收到uptodate消息后,又可以重新接受client的请求进行服务了。
流程图如下所示:
2.6 工作流程
2.6.1 Leader工作流程
Leader主要有三个功能:
1)恢复数据;
2)维持与Learner的心跳,接收Learner请求并判断Learner的请求消息类型;
3)Learner的消息类型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根据不同的消息类型,进行不同的处理。
PING消息是指Learner的心跳信息;REQUEST消息是Follower发送的提议信息,包括写请求及同步请求;ACK消息是Follower的对提议的回复,超过半数的Follower通过,则commit该提议;REVALIDATE消息是用来延长SESSION有效时间。
Leader的工作流程简图如下所示,在实际实现中,流程要比下图复杂得多,启动了三个线程来实现功能。
2.6.2 Follower工作流程
Follower主要有四个功能:
1)向Leader发送请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
2)接收Leader消息并进行处理;
3)接收Client的请求,如果为写请求,发送给Leader进行投票;
4)返回Client结果。
Follower的消息循环处理如下几种来自Leader的消息:
1)PING消息: 心跳消息;
2)PROPOSAL消息:Leader发起的提案,要求Follower投票;
3)COMMIT消息:服务器端最新一次提案的信息;
4)UPTODATE消息:表明同步完成;
5)REVALIDATE消息:根据Leader的REVALIDATE结果,关闭待revalidate的session还是允许其接受消息;
6)SYNC消息:返回SYNC结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新。
Follower的工作流程简图如下所示,在实际实现中,Follower是通过5个线程来实现功能的。
三、搞懂marathon
marathon是一个mesos框架,能够支持运行长服务,比如web应用等。是集群的分布式Init.d,能够原样运行任何Linux二进制发布版本,如Tomcat Play等等,可以集群的多进程管理。也是一种私有的Pass,实现服务的发现,为部署提供提供REST API服务,有授权和SSL、配置约束,通过HAProxy实现服务发现和负载平衡。

我们可以如同一台Linux主机一样管理数千台服务器,它们的对应原理如下图,使用Marathon类似Linux主机内的init Systemd等外壳管理,而Mesos则不只包含一个Linux核,可以调度数千台服务器的Linux核,实际是一个数据中心的内核:
四、引入docker
五、实战准备
5.1 系统准备
[root@docker-slave ~]# cat /etc/redhat-releaseCentOS Linux release 7.1.1503 (Core)[root@docker-slave ~]# uname -r3.10.0-229.4.2.el7.x86_64[root@docker-slave ~]# uname -mx86_64[root@docker-slave ~]# uname -aLinux docker-slave 3.10.0-229.4.2.el7.x86_64 #1 SMP Wed May 13 10:06:09 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux[root@docker-slave ~]# cat /etc/sysconfig/networkHOSTNAME=docker-slave[root@docker-slave ~]# ping docker-salveping: unknown host docker-salve[root@docker-slave ~]# ping docker-slavePING docker-slave (192.168.100.6) 56(84) bytes of data.64 bytes from docker-slave (192.168.100.6): icmp_seq=1 ttl=64 time=0.058 ms
5.2 部署Zookeeper
[root@docker-slave ~]# yum install -y java[root@docker-slave ~]# cd /usr/local/src/[root@docker-slave src]# wget https://www.apache.org/dist/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz[root@docker-slave src]# tar zxf zookeeper-3.4.6.tar.gz[root@docker-slave src]# mv zookeeper-3.4.6 /usr/local/[root@docker-slave src]# ln -s /usr/local/zookeeper-3.4.6/ /usr/local/zookeeper
[root@docker-slave src]# cd /usr/local/zookeeper/conf/[root@docker-slave conf]# cp zoo_sample.cfg zoo.cfg[root@docker-slave conf]# grep '^[a-z]' zoo.cfgtickTime=2000#Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。initLimit=10#Zookeeper的Leader 接受客户端(Follower)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5个心跳的时间(也就是tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒syncLimit=5#表示 Leader 与 Follower 之间发送消息时请求和应答时间长度,最长不能超过多少个tickTime 的时间长度,总的时间长度就是 2*2000=4 秒dataDir=/data/zk1#数据存放目录clientPort=2181#客户端连接端口#A 是一个数字,表示这个是第几号服务器;#B 是这个服务器的 ip 地址;#C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;#D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。server.1=192.168.100.6:3181:4181server.2=192.168.100.6:3182:4182server.3=192.168.100.6:3183:4183# 配置文件最终配置[root@docker-slave conf]# grep '^[a-z]' zoo.cfgtickTime=2000initLimit=10syncLimit=5dataDir=/data/zk1clientPort=2181server.1=192.168.100.6:3181:4181server.2=192.168.100.6:3182:4182server.3=192.168.100.6:3183:4183
[root@docker-slave conf]# mkdir -p /data/zk1 /data/zk2 /data/zk3[root@docker-slave conf]# echo "1" >/data/zk1/myid[root@docker-slave conf]# echo "2" >/data/zk2/myid[root@docker-slave conf]# echo "3" >/data/zk3/myid
[root@docker-slave conf]# cp zoo.cfg zk1.cfg[root@docker-slave conf]# cp zoo.cfg zk2.cfg[root@docker-slave conf]# cp zoo.cfg zk3.cfg
[root@docker-slave conf]# sed -i 's/zk1/zk2/g' zk2.cfg[root@docker-slave conf]# sed -i 's/zk1/zk3/g' zk3.cfg[root@docker-slave conf]# sed -i 's/2181/2182/g' zk2.cfg[root@docker-slave conf]# sed -i 's/2181/2183/g' zk3.cfg
[root@docker-slave conf]# /usr/local/zookeeper/bin/zkServer.sh start /usr/local/zookeeper/conf/zk1.cfgJMX enabled by defaultUsing config: /usr/local/zookeeper/conf/zk1.cfgStarting zookeeper ... STARTED[root@docker-slave conf]# /usr/local/zookeeper/bin/zkServer.sh start /usr/local/zookeeper/conf/zk2.cfgJMX enabled by defaultUsing config: /usr/local/zookeeper/conf/zk2.cfgStarting zookeeper ... STARTED[root@docker-slave conf]# /usr/local/zookeeper/bin/zkServer.sh start /usr/local/zookeeper/conf/zk3.cfgJMX enabled by defaultUsing config: /usr/local/zookeeper/conf/zk3.cfgStarting zookeeper ... STARTED[root@docker-slave conf]# /usr/local/zookeeper/bin/zkServer.sh status /usr/local/zookeeper/conf/zk1.cfgJMX enabled by defaultUsing config: /usr/local/zookeeper/conf/zk1.cfgMode: follower[root@docker-slave conf]# /usr/local/zookeeper/bin/zkServer.sh status /usr/local/zookeeper/conf/zk2.cfgJMX enabled by defaultUsing config: /usr/local/zookeeper/conf/zk2.cfgMode: leader[root@docker-slave conf]# /usr/local/zookeeper/bin/zkServer.sh status /usr/local/zookeeper/conf/zk3.cfgJMX enabled by defaultUsing config: /usr/local/zookeeper/conf/zk3.cfgMode: follower
[root@docker-master ~]# rpm -ivh http://repos.mesosphere.com/el/7/noarch/RPMS/mesosphere-el-repo-7-1.noarch.rpm[root@docker-slave conf]# rpm -ivh http://repos.mesosphere.com/el/7/noarch/RPMS/mesosphere-el-repo-7-1.noarch.rpm
[root@docker-master ~]# yum -y install mesos marathon
[root@docker-master ~]# cat /etc/mesos/zkzk://192.168.100.6:2181,192.168.100.6:2182,192.168.100.6:2183/mesos
[root@docker-master ~]# systemctl enable mesos-master mesos-slave[root@docker-master ~]# systemctl start mesos-master mesos-slave[root@docker-master ~]# systemctl enable marathon[root@docker-master ~]# systemctl start marathon
[root@docker-slave conf]# yum -y install mesos

[root@docker-master ~]# MASTER=$(mesos-resolve `cat /etc/mesos/zk`)[root@docker-master ~]# mesos-execute --master=$MASTER --name="cluster-test" --command="sleep 60"

5.4:使用marathon调用mesos管理docker容器
[root@docker-slave ~]# yum install -y docker[root@docker-master ~]# systemctl enable docker[root@docker-master ~]# systemctl start docker[root@docker-master ~]# docker pull nginx
[root@docker-master ~]# echo 'docker,mesos' | tee /etc/mesos-slave/containerizers[root@docker-master ~]# systemctl restart mesos-slave[root@docker-slave ~]# echo 'docker,mesos' | tee /etc/mesos-slave/containerizers[root@docker-slave ~]# systemctl restart mesos-slave

[root@docker-master ~]# cat nginx.json{"id":"nginx","cpus":0.2,"mem":20.0,"instances": 1,"constraints": [["hostname", "UNIQUE",""]],"container": {"type":"DOCKER","docker": {"image": "nginx","network": "BRIDGE","portMappings": [{"containerPort": 80, "hostPort": 0,"servicePort": 0, "protocol": "tcp" }]}}}
[root@docker-master ~]# curl -X POST http://192.168.100.5:8080/v2/apps -d @/root/nginx.json -H "Content-type: application/json"{"id":"/nginx","cmd":null,"args":null,"user":null,"env":{},"instances":1,"cpus":0.2,"mem":20,"disk":0,"executor":"","constraints":[["hostname","UNIQUE",""]],"uris":[],"fetch":[],"storeUrls":[],"ports":[0],"requirePorts":false,"backoffSeconds":1,"backoffFactor":1.15,"maxLaunchDelaySeconds":3600,"container":{"type":"DOCKER","volumes":[],"docker":{"image":"nginx","network":"BRIDGE","portMappings":[{"containerPort":80,"hostPort":0,"servicePort":0,"protocol":"tcp"}],"privileged":false,"parameters":[],"forcePullImage":false}},"healthChecks":[],"dependencies":[],"upgradeStrategy":{"minimumHealthCapacity":1,"maximumOverCapacity":1},"labels":{},"acceptedResourceRoles":null,"ipAddress":null,"version":"2016-03-01T07:19:44.339Z","tasksStaged":0,"tasksRunning":0,"tasksHealthy":0,"tasksUnhealthy":0,"deployments":[{"id":"502712f0-dc3a-44f8-a9cf-0dfa7407ec94"}],"tasks":[]}
[root@docker-master ~]# docker ps -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES2e333092a383 nginx "nginx -g 'daemon off" About a minute ago Up About a minute 443/tcp, 0.0.0.0:31705->80/tcp mesos-46abb5e7-3775-4383-b953-c5b2b9ae5c9f-S0.00229c83-5505-400d-984f-4849e9850b71
[root@docker-master ~]# curl 192.168.100.5:31705



