执行系统命令
执行系统命令
- os.system
- os.spawn*
- os.popen
- popen2.*
- commands.*
后面三个已经废弃,以上执行shell命令的相关的模块和函数的功能均在subprocess模块中实现,并提供了更加丰富的功能
call
执行命令,返回状态码。
import subprocess ret1 = subprocess.call(["ls","-l"],shell=False) print ret1 ret2 = subprocess.call("ls -l",shell=True) print ret2
shell = True ,允许shell命令是字符串形式(是使用系统自带的shell)
shutil
高级的文件、文件夹、压缩包处理模块
shutil.copyfileobj(fsrc,fdst,length)将文件内容拷贝到另一个文件中,length是每次读取多少拷贝
import shutil
s = open('test1.py')
d = open('test7.py','wb')
#d.write(s.read())
shutil.copyfileobj(s,d)
shutil.copyfile(src,dst)拷贝文件
import shutil shutil.copyfile('test1.py','test7.py')
尽拷贝权限,内容组用户均不变
shutil.copymode(src, dst)
创建压缩包并返回文件路径
shutil.make_archive(base_name,format….)
- base_name:压缩包的文件名,也可以是压缩包的路径,当只是文件名时,则保存在当前目录,否则保存至指定路径
- format:压缩包的种类 zip tar batar gztar
- root_dir: 要压缩的文件夹路径,默认是当前目录
实例
import shutil # 将/user/local/ftp下面的文件www打包放置在当前程序目录 ret = shutil.make_archive("www",'tar',root_dir='/user/local/ftp') # 将/user/local/ftp下面的文件www打包放置在/user/local目录 ret2 = shutil.make_archive("/user/loca/www",'tar',root_dir='/user/local/ftp')
shutil对压缩包的处理是调用ZipFile和TarFile两个模块来进行的
import zipfile
# 压缩
z = zipfile.ZipFile('ll.zip','w')
z.write('test1.py')
z.write('test2.py')
z.close()
# 解压
j = zipfile.ZipFile('ll.zip','r')
j.extractall()
j.close()
import tarfile
# 压缩
tar = tarfile.open('y.tar','w')
tar.add('/usr/local/1.zip',arcname='1.zip')
tar.add('/usr/local/2.zip',arcname='2.zip')
tar.close()
# 解压
tar = tarfile.open('y.tar','r')
tar.extractall()
tar.close()
ConfigParser
用于对特定的配置进行操作,当前模块的名称在python3.x版本中变更为configparser
#!/usr/bin/env python
# coding:utf-8
# 用于对特定的配置进行操作,当前模块的名称在 python 3.x 版本中变更为 configparser。
import ConfigParser
config = ConfigParser.ConfigParser()
config.read('goods.txt')
##########读操作######
# 获取模块的名称
secs = config.sections()
print secs
# 结果:['section1', 'section2']
# 获取指定模块的key值
options = config.options('section1')
print options
# 结果:['k1', 'k2']
# 获取指定模块下的items
item_list = config.items('section1')
print item_list
# 结果:[('k1', 'v1'), ('k2', 'v2')]
# 获取指定模块下的key的值
val = config.get('section1','k2')
print val
#########写操作############
# 删除一个section模块
sec =config.remove_section('car')
config.write(open('i.txt','w'))
# 添加section模块。查看一个section是否存在;不存在则添加
sec = config.has_section('car1')
print sec # False:表示不存在
sec = config.add_section('car1')
sec = config.has_section('car1')
print sec # True: 表示不存在
config.write(open('i.txt','w'))
# 添加seection下面的key-value
config.set('car','k1',111111111)
config.write(open('1.txt',"w"))
# 删除section下面的key值为baoma
config.remove_option('car','baoma')
config.write(open('1.txt',"w"))
logging
用于便捷记录日志且线程安全的模块
#!/usr/bin/env python
# coding:utf-8
import logging
logging.basicConfig(filename='1.log',
format='%(asctime)s - %(name)s - %(levelname)s - %(module)s - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
# level=logging.CRITICAL,
level=40,
)
logging.debug('debugdebugdebugdebugdebug')
logging.info('infoinfoinfoinfoinfoinfoinfo')
logging.warning('warningwarningwarningwarning')
logging.error('errorerrorerrorerrorerrorerror')
logging.critical('criticalcriticalcriticalcritical')
logging.log(50,'asdfghjkl')
解读:
1:filename创建日志文件,然后以追加的方式接收
2:format格式:时间-用户-日志级别-哪个模块的日志-日志信息
3:时间格式:2015-12-09 11:00:28 AM
4:日志级别:可以使用数字,也可以直接指定
日志级别对应表:
CRITICAL = 50
ERROR = 40
WARNING = 30
INFO = 20
DEBUG = 10
#!/usr/bin/env python
# coding:utf-8
import logging
logging.basicConfig(filename='1.log',
format='%(asctime)s - %(name)s - %(levelname)s - %(module)s - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
# level=logging.CRITICAL,
level=logging.DEBUG,
)
while True:
option = raw_input("请输入数字")
if option.isdigit():
print "是数字",option
logging.info('孩子输入的是数字')
else:
logging.error('孩子,你是不是傻')
结果:
2015-12-09 13:23:39 PM - root - ERROR - test8 - 孩子,你是不是傻
2015-12-09 13:24:30 PM - root - ERROR - test8 - 孩子,你是不是傻
2015-12-09 13:24:31 PM - root - INFO - test8 - 孩子输入的是数字
2015-12-09 13:24:42 PM - root - INFO - test8 - 孩子输入的是数字
time datetime
时间相关的操作
时间有三种表示方式:
-
时间戳 1970年1月1日之后的秒 time.time()
-
格式化的字符串 2015-12-12 12:12
-
结构化时间 元组包含了:年、月、日、星期等 time.struct_time time.localtime()
#!/usr/bin/env python
# coding:utf-8
import time
import datetime
print time.time()
# 1449631804.64
print time.strftime('%Y-%m-%d %H-%M-%S %p')
# 默认是当前时间2015-12-09 11-04-30 AM
print time.localtime()
# time.struct_time(tm_year=2015, tm_mon=12, tm_mday=9, tm_hour=11, tm_min=31, tm_sec=55, tm_wday=2, tm_yday=343, tm_isdst=0)
print time.strptime('2014-11-11','%Y-%m-%d')
# 将格式化时间转成结构化时间
# 日期到时间戳的转化
t = datetime.datetime(2015,11,14,14,14)
print type('t') # <type 'str'>
ti = time.mktime(t.timetuple())
print ti # 1447481640.0
# 时间戳到日期的转化
tt = time.localtime()
print tt
timestr = time.strftime('%Y-%m-%d %H:%M:%S')
print timestr
# 2015-12-09 13:53:23
re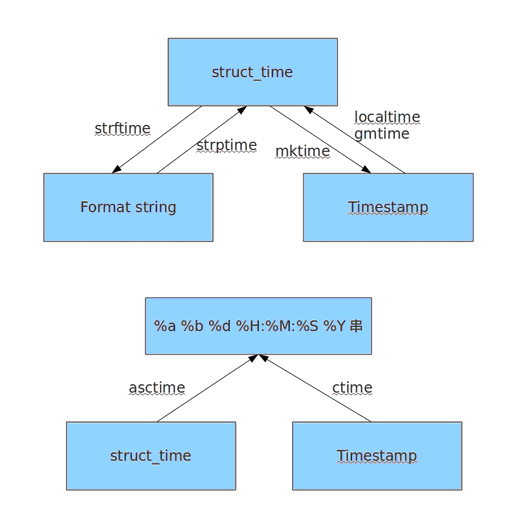
re模块是用于python的正则表达式的操作
字符:
-
.匹配除换行符意外的任意字符
-
\w匹配字母或数字或下划线或汉字
-
\s匹配任意的空白符
-
\d匹配数字
-
\b匹配单词的开始或结束
-
^匹配字符串的开始
-
$匹配字符串的结束
次数:
-
*重复零次或更多次
-
+重复一次或更多次
-
?重复零次或一次
-
{n}重复n次
-
{n,}重复n次或更多次
-
{n,m}重复n到m次
1:match(pattern,string,flahs=0)
从起始位置开始根据模型去字符串中匹配指定内容,匹配单个
-
正则表达式
-
要匹配的字符串
-
标志位,用于控制正则表达式的匹配方式
import re obj = re.match('\d+','213dsfa32134') print obj # <_sre.SRE_Match object at 0x0201EA30> print obj.group() # 213
2:search(pattern,string,flahs=0)
根据模版去字符串中匹配指定内容,匹配单个
import re obj = re.search('\d+','213dsfa32134') print obj # <_sre.SRE_Match object at 0x0201EA30> print obj.group() # 213
3:group和groups
返回一个或多个子组。如果参数为一个,就返回一个子串;如果参数有多个,就返回多个子串组成的元组
import re a = "4321fdsa4132" print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group() print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0) print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1) print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2) print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3) print re.search("([0-9]*)([a-z]*)([0-9]*)",a).groups()
结果:
4321fdsa4132
4321fdsa4132
4321
fdsa
4132
('4321', 'fdsa', '4132')
4:findall(pattern,string,flahs=0)
match和search只能匹配字符串中的一个,如果想要匹配到字符串中所有符合条件的元素,则需要使用findall
import re a = "4321fd2sa4132" print re.findall("\d+",a)
结果:
['4321', '2', '4132']
5:sub(pattern,repl,string,count=0,flag=0)用于替换匹配的字符串
import re c = "32gbj4321hbj45321" new_c = re.sub('\d+','+++',c) print new_c
结果:
+++gbj+++hbj+++
6:split(pattern,string,maxsplit=0,flags=0)
根据指定匹配进行分组
import re content = "'1 - 2 * ((60-30+1*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2) )'" new_content = re.split('\*',content) print new_content # ["'1 - 2 ", ' ((60-30+1', '(9-2', '5/3+7/3', '99/4', '2998+10', '568/14))-(-4', '3)/(16-3', "2) )'"] new_content1= re.split('[\+\-\*\/]+',content) print new_content1 # ["'1 ", ' 2 ', ' ((60', '30', '1', '(9', '2', '5', '3', '7', '3', '99', '4', '2998', '10', '568', '14))', '(', '4', '3)', '(16', '3', "2) )'"] a = "'1 - 2 * ((60-30+1*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2) )'" new_a = re.sub('\s*','',a) print new_a # '1-2*((60-30+1*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))' new_1 = re.split('\(([\+\-\*\/]?\d+[\+\-\*\/]?\d+)\)',new_a,1) print new_1 # ["'1-2*((60-30+1*(9-2*5/3+7/3*99/4*2998+10*568/14))-", '-4*3', "/(16-3*2))'"]
random
随机数
它会自动生成四位数字字母组合的字符串
import random checkcode = '' for i in range(4): current = random.randrange(0,4) if current != i: temp = chr(random.randint(65,90)) else: temp = random.randint(0,9) checkcode += str(temp) print checkcode

