Python之路---day1
Python简介
Python前世今生
Python创始人是吉多.范罗苏姆。在1989年万圣节期间为打发时间而开发的。
目前Python在TIOBE排行榜第五位置
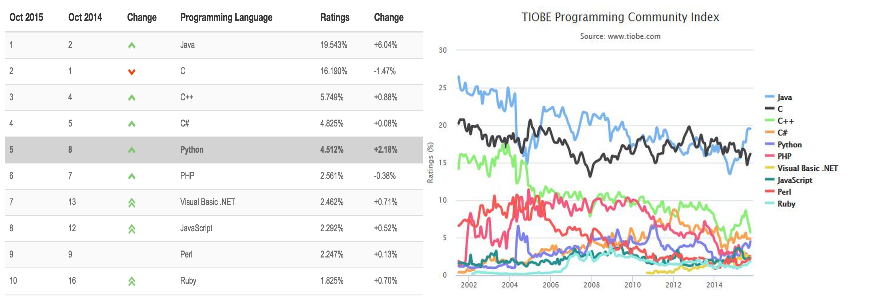
Python可以应用在众多的领域中:
数据分析、组建集成、网络服务、图像处理、数值计算和科学计算等领域。
Python应用的知名公司有:
Youtube、Dropbox、BT、知乎、豆瓣、谷歌、百度、腾讯、
汽车之家等。
Python可以做的工作有:
自动化运维、自动化测试、大数据分析、爬虫、Web等
Python与其他语言的异同:
- python是由C语言来发而来的。
- 代码的执行:
C语言:代码编译===》机器码===》执行
其他语言:代码编译===》字节码===》机器码===》执行
python也是这样,在字节码===》机器码的过程会生成一个.pyc的文件,这个文件就是机器码的文件。
注视:python在执行过程中会先找有没有.pyc文件,然后与原py文件进行对比,如果没有变化,则直接执行.pyc文件;如果.py文件较新,则重新生产.pyc文件。然后执行。
-
代码执行速度
由上面代码的执行顺序,也可以看出,python的运行速度相比较C会慢。
-
内置模版库
Python内部会自带很多的模版库,可以直接调用。可以满足大多数的基本的需求。
- Python的种类
-
Cpython
官方的版本。使用C语言实现,使用最为广泛。CPython实现会将源文件(py文件)转换成字节码文件(pyc文件),然后运行在Python虚拟机上。
-
Jyhton
Python的Java实现,Jython会将Python代码动态编译成Java字节码,然后在JVM上运行。
-
IronPython
Python的C#实现,IronPython将Python代码编译成C#字节码,然后在CLR上运行。
-
PyPy
Python实现的Python,将Python的字节码字节码再编译成机器码。它在Python的基础上对Python的字节码进一步处理,提升了执行速度。
Python环境
推荐使用2.7版本的
Windows:
1:下载安装包
https://www.python.org/ftp/python/2.7.10/python-2.7.10.msi
或者直接去官网下载你想要的版:https://www.python.org/downloads/
2:直接安装
默认的安装路径是:C:\Python27
3:配置环境变量
【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【Python安装目录追加到变值值中,用 ; 分割】
例如:;C:\Python27 在最后面添加即可。
Linux:
1:linux都自带Python环境。推荐使用ubuntu。因为其自带比较新的版本。
Python入门
一:你好世界
创建hello.py


1 root@python:/python/day1# cat hello.py 2 3 #!/usr/bin/env python #告诉系统使用python解释器 4 5 #-*- coding:utf-8 -*- #设置字符集,使用UTF-8 6 7 print "你好,世界" 8 9 root@python:/python/day1# python hello.py #py文件的执行 10 11 你好,世界
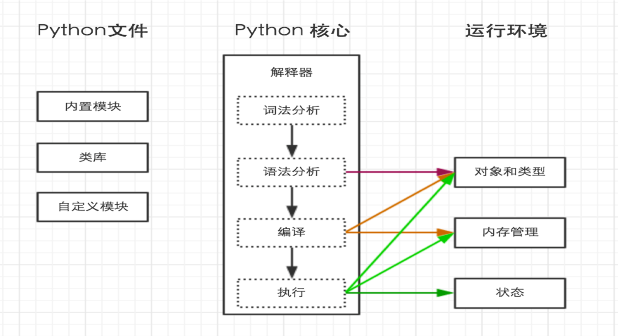
二:python程序的执行过程
三:编码格式
- ASCII:美国标准信息交换代码是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
-
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多。
-
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存。
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)。但是3.0以后的版本默认是UTF-8。
四:注释的方式
- 单行注释:#
- 多行注释:"""注释的内容"""或者是三个单引号
五:传参
上面已经说了,Python有大量的模块,从而使得开发很简洁,类库主要包含三种:
1:Python内部提供的模块
2:业内开源的模块
3:程序员自己开发的模块
Python内部提供一个sys的模块,其中的sys.argv就是用来捕获执行python脚本时传入的参数。
1 root@python:/python/day1# cat hello.py 2 3 #!/usr/bin/env python 4 5 #-*- coding:utf-8 -*- 6 7 import sys #导入sys模块 8 9 print sys.argv #使用argv 10 11 root@python:/python/day1# python hello.py user_argv #文件名后面是参数 12 13 ['hello.py', 'user_argv']
六:变量
1:声明变量
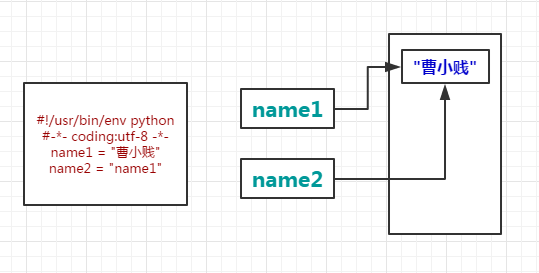
1 #!/usr/bin/env python 2 3 #-*- coding:utf-8 -*- 4 5 name = "曹小贱"
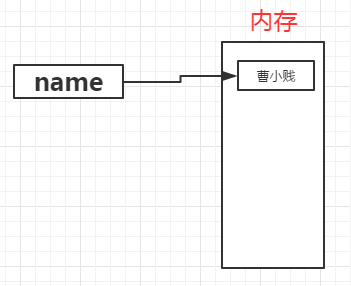
变量的名:name 变量的值:"曹小贱"
变量的作用:昵称,代指内存里某个地址中保存的内容。
变量定义的规则:
1:变量名只能是字母、数字或下划线的任意组合。
2:变量名不能以数字开头。
3:不能使用关键字进行声明。
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
2:变量的赋值

七:输入
1 root@python:/python/day1# cat hello.py 2 3 #!/usr/bin/env python 4 5 #-*- coding:utf-8 -*- 6 7 #将用户输入的内容赋值给name变量 8 9 name = raw_input("请输入用户名:") 10 11 #打印输入的内容 12 13 print name 14 15 root@python:/python/day1# python hello.py 16 17 请输入用户名:曹高田 18 19 曹高田 20 21 输入密码时,如果想要不可见,需要利用getpass方法即可: 22 23 #!/usr/bin/env python 24 25 #-*- coding:utf-8 -*- 26 27 #首先导入getpass模块 28 29 import getpass 30 31 #设置隐藏密码 32 33 pwd = getpass.getpass("请输入密码:") 34 35 print pwd 36 37 root@python:/python/day1# python hello.py 38 39 请输入密码: 40 41 can not look
八:流程控制和缩进
需求一:用户登录验证
1 #!/usr/bin/env python 2 3 #coding:utf-8 4 5 import getpass 6 7 name = raw_input("请输入用户名:") 8 9 pwd = getpass.getpass("请输入密码:") 10 11 if name == "曹小贱" and pwd == "123456": 12 13 print "欢迎,曹小贱" 14 15 else: 16 17 print "大哥,你走错门了吧" 18 19 执行: 20 21 root@python:/python/day1# python 1.py 22 23 请输入用户名:cao 24 25 请输入密码: 26 27 大哥,你走错门了吧 28 29 root@python:/python/day1# python 1.py 30 31 请输入用户名:曹小贱 32 33 请输入密码: 34 35 欢迎,曹小贱
需求二:根据用户输入内容输出其权限
1 #!/usr/bin/env python 2 3 #coding:utf-8 4 5 import getpass 6 7 name = raw_input('请输入用户名:') 8 9 pwd = getpass.getpass('这是隐藏的密码:') 10 11 if name == 'eric' and pwd == '123': 12 13 print '普通' 14 15 elif name == 'tony' and pwd == '123': 16 17 print '超级' 18 19 elif name == 'alex' and pwd == '123': 20 21 print '超神' 22 23 else: 24 25 print '登录失败'
注释:外层变量可以被内存变量调用,反之不行。
九:Python的基本类型
1:数字
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
注:Python中存在小数字池:-5 ~ 257
2:布尔值(bool)
True False
真或假
1 或0
3:字符串
"Hello World"
万恶的字符串拼接:
python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的+号每出现一次就会在内从中重新开辟一块空间。
字符串格式化
>>> name = "曹小贱"
>>> print "i am %s " % name
i am 曹小贱
注释:字符串是%s;整数%d;浮点数%f
字符串的常用功能:
移除空白
strip
lstrip
rstrip
>>> name = " alex "
>>> import tab
>>> print name.strip()
alex
>>> print name.lstrip()
alex
>>> print name.rstrip()
alex
分割
>>> name = "a;b;c;d"
>>> name1 = name.split(';')
>>> name1
['a', 'b', 'c', 'd']
长度
>>> name
'a;b;c;d'
>>> len(name)
7
>>> name[len(name)-1]
'd'
索引
>>> name
'a;b;c;d'
>>> name[1]
';'
>>> name[2]
'b'
切片
>>> name = "alexd"
>>> name[0]
'a'
>>> name[0]
'a'
>>> name[1:2]
'l'
>>> name[1:4]
'lex'
>>> name[3:4]
'x'
>>> name[-3:]
'exd'
>>> name[0:]
'alexd'
4:列表
创建(第一种方式最终要调用第二种方式)
>>> name = ['ccc','ggg','ttt']
>>> name
['ccc', 'ggg', 'ttt']
>>> name = list(['ccc','ggg','ttt'])
>>> name
['ccc', 'ggg', 'ttt']
索引
>>> name[1]
'ggg'
切片
>>> name[1:3]
['ggg', 'ttt']
追加
>>> name.append('sss')
>>> name
['ccc', 'ggg', 'ttt', 'sss']
删除
>>> name
['ccc', 'ggg', 'ttt', 'sss']
>>> del name[2]
>>> name
['ccc', 'ggg', 'sss']
长度
>>> name
['ccc', 'ggg', 'sss']
>>> len(name)
3
循环
#!/usr/bin/env python
#coding:utf-8
name = ['ccc','ggg','ttt']
for i in name:
if i == "ccc":
print "找到了"
break
包含
>>> name
['ccc', 'ggg', 'sss']
>>> 'ccc' in name
True
>>> 'cgt' in name
False
5:元组(tuple)
创建元组
>>> name = ('ccc','ggg','ttt')
>>> name
('ccc', 'ggg', 'ttt')
>>> name1 = tuple(('aaa','bbb','ccc'))
>>> name1
('aaa', 'bbb', 'ccc')
上面的name的方式最终还是要调用下面的方式。
索引
>>> name1
('aaa', 'bbb', 'ccc')
>>> name1[2]
'ccc'
切片
>>> name1
('aaa', 'bbb', 'ccc')
>>> name[1:2]
('ggg',)
解释:顾头不顾尾
循环
#!/usr/bin/env python
#coding:utf-8
name = ('aaa', 'bbb', 'ccc')
for i in name:
if i == "ccc":
print "找到了"
break
包含
>>> name1
('aaa', 'bbb', 'ccc')
>>> 'bbb' in name1
True
>>> 'abc' in name1
False
6:字典(无序)
创建字典
>>> menu = {'name':'cgt','age':24,'job':'IT'}
>>> menu
{'job': 'IT', 'age': 24, 'name': 'cgt'}
>>> menu1 = {'name':'cgt1','age':2424,'job':'IT'}
>>> menu1
{'job': 'IT', 'age': 2424, 'name': 'cgt1'}
索引
>>> menu
{'job': 'IT', 'age': 24, 'name': 'cgt'}
>>> menu[1] #字典是一种键值对的方式,不能使用下标来获取,通过键值。原因是它是无序的
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 1
>>> menu['name']
'cgt'
新增
>>> menu['salary']=400000
>>> menu
{'job': 'IT', 'salary': 400000, 'age': 24, 'name': 'cgt'} #从这里也可以体现出他的无序
修改
>>> menu['salary']=400000
>>> menu
{'job': 'IT', 'salary': 400000, 'age': 24, 'name': 'cgt'}
>>> menu['salary']=1 #可以直接重新定义变量的值,进行修改
>>> menu
{'job': 'IT', 'salary': 1, 'age': 24, 'name': 'cgt'}
删除
>>> menu
{'job': 'IT', 'salary': 1, 'age': 24, 'name': 'cgt'}
>>> del menu['salary']
>>> menu
{'job': 'IT', 'age': 24, 'name': 'cgt'}
#通过pop来删除键,它的不同之处是再删除的同时,显示出值
>>> menu
{'job': 'IT', 'age': 24, 'name': 'cgt'}
>>> menu.pop('name')
'cgt'
>>> menu
{'job': 'IT', 'age': 24}
#清除所有的键
>>> menu1
{'job': 'IT', 'age': 2424, 'name': 'cgt1'}
>>> menu1.clear()
>>> menu1
{}
循环
#!/usr/bin/env python
#coding:utf-8
menu = {
'name':'曹小贱',
'age':24,
'job':'IT'
}
#开始遍历循环
for key in menu:
print key,'对应的值',menu[key]
结果: #这里呈现的结果打印出来也是无序的
job 对应的值 IT
age 对应的值 24
name 对应的值 曹小贱
#####################################################
#!/usr/bin/env python
#coding:utf-8
menu = {
'name':'曹小贱',
'age':24,
'job':'IT'
}
#开始遍历循环
for key,value in menu.items():
print key,'对应的值',value
结果:
job 对应的值 IT
age 对应的值 24
name 对应的值 曹小贱
PS:循环,range,continue 和 break
range在什么范围内
continue跳出本次循环,继续执行下次循环
break终止循环
长度
len(menu)
十:运算
|
运算符 |
描述 |
实例 |
|
算术运算 |
||
|
+ |
两个对象相加 |
10+19输出结果29 |
|
_ |
得到负数;两个对象相减 |
10-19输出结果-9 |
|
* |
两个数相乘, |
10*19输出结果190 |
|
/ |
两个数相除 |
10/2输出结果5 |
|
% |
取模-返回除法的余数 |
10%3输出结果1 |
|
** |
幂 |
2**2输出结果4 |
|
// |
取整除返回商的整数部分 |
9//2输出结果4 |
|
比较运算 |
||
|
== |
等于 |
(a==b)返回false |
|
!= |
不等于 |
(a != b)返回true |
|
<> |
不等于 |
(a <> b)返回false |
|
> |
大于 |
(a > b)返回false |
|
< |
小于 |
(a < b)返回true |
|
>= |
大于等于 |
(a >= b)返回false |
|
<= |
小于等于 |
(a <= b)返回true |
|
赋值运算 |
||
|
= |
简单的赋值运算符 |
c = a + b将a+b的运算结果赋值给c |
|
+= |
加法赋值运算 |
c+=a等效于c=c+a |
|
-= |
减法赋值运算 |
c-=a等效于c=c-a |
|
/= |
除法赋值运算 |
c/=a等效于c=c/a |
|
%= |
取模赋值运算 |
c%=a等效于c=c%a |
|
*= |
乘法赋值运算 |
c*=a等效于c=c*a |
|
**= |
幂赋值运算 |
c**=a等效于c=c**a |
|
//= |
取整赋值运算 |
c//a等效于c=c//a |
|
逻辑运算 |
||
|
and |
布尔"与"如果x为False,x and y 返回false,否则返回y的值 |
(a and b)返回true |
|
or |
布尔"或"如果x为True,,则返回True。否则返回y大的值 |
(a or b)返回true |
|
not |
布尔"非",x为true,返回false |
not (a and b)返回false |
|
成员运算 |
||
|
in |
如果在指定的序列内找到值,则返回True. |
x在y的序列中,返回True |
|
not in |
如果在指定的序列内没找到值,则返回True. |
x不在y的序列中,返回True |
|
身份运算 |
||
|
is |
is 是判断两个标识符是不是引用自一个对象 |
x is y,如果id(x)=id(y) is返回结果1 |
|
is not |
is not 是判断两个标识符是不是引用来自不同的对象 |
x is not y 如果id(x)!=id(y)返回结果1 |
|
位运算 |
||
|
& |
按位与运算 |
(a&b)输出结果12.二进制解释:0000 1100 |
|
| |
按位或运算 |
(a|b)输出结果61二进制解释:0011 1101 |
|
^ |
按位异或运算 |
(a^b)输出结果49 二进制解释:0011 0001 |
|
- |
按位取反 |
(-a)输出结果-61 二进制解释:1100 0011 |
|
<< |
左移动运算 |
a<<2输出结果240二进制解释:1111 0000 |
|
>> |
右移动运算 |
a>>2输出结果15二进制解释:0000 1111 |
1 #!/usr/bin/env python 2 3 #coding:utf-8 4 5 import getpass 6 7 name = raw_input('请输入用户名:') 8 9 pwd = getpass.getpass('这是隐藏的密码:') 10 11 if name == 'eric' and pwd == '123': 12 13 print '普通' 14 15 elif name == 'tony' and pwd == '123': 16 17 print '超级' 18 19 elif name == 'alex' and pwd == '123': 20 21 print '超神' 22 23 else: 24 25 print '登录失败'
运算符优先级
|
运算符 |
描述 |
|
** |
指数(最高优先级) |
|
~+- |
按位翻转,一元加号和减号(最后两个方法名为:+@和-@) |
|
*/%// |
乘除取模取整除 |
|
+ - |
加法减法 |
|
左移右移 |
|
|
& |
位 'AND' |
|
^ | |
位运算 |
|
<= <> >=s |
比较运算符 |
|
<> == != |
等于运算符 |
|
= %= /= //= -= += *= **= |
赋值运算符 |
|
is is not |
身份运算符 |
|
in not in |
成员运算符 |
|
not or and |
逻辑运算符 |
十一:对文件的基本操作
file = file("文件路径名称","模式")
f = file('文件名','模式') 打开一个文件,
f = open('文件名','模式') 打开一个文件,
f.read():是以字符串的形式读取出来
f.readline():是以列表的形式
f.name获取文件的名字
f.realines():全部一次性读取到内存中出来
f.xrealines():全部读取到内存中出来,但是一行一行的读取
f.flush():将内存中的内容刷到硬盘文件中
f.close():关闭文件.
f.write():写入
f.seek(0): 回到文件开头
f.mode:文件打开的模式,读写等
f.truncate():加数字 截取多少字节
文件打开的模式
w 以写方式打开,
a 以追加模式打开 (从 EOF 开始, 必要时创建新文件)
r+ 以读写模式打开(一般使用r+)
w+ 以读写模式打开 (参见 w )
a+ 以读写模式打开 (参见 a )
rb 以二进制读模式打开
wb 以二进制写模式打开 (参见 w )
ab 以二进制追加模式打开 (参见 a )
rb+ 以二进制读写模式打开 (参见 r+ )
wb+ 以二进制读写模式打开 (参见 w+ )
ab+ 以二进制读写模式打开 (参见 a+ )
