Kafka与Logstash的数据采集对接
Logstash工作原理
由于Kafka采用解耦的设计思想,并非原始的发布订阅,生产者负责产生消息,直接推送给消费者。而是在中间加入持久化层——broker,生产者把数据存放在broker中,消费者从broker中取数据。这样就带来了几个好处::
1 生产者的负载与消费者的负载解耦
2 消费者按照自己的能力fetch数据
3 消费者可以自定义消费的数量
由于broker采用了主题topic–>分区的思想,使得某个分区内部的顺序可以保证有序性,但是分区间的数据不保证有序性。这样,消费者可以以分区为单位,自定义读取的位置——offset。
Kafka采用zookeeper作为管理,记录了producer到broker的信息,以及consumer与broker中partition的对应关系。因此,生产者可以直接把数据传递给broker,broker通过zookeeper进行leader–>followers的选举管理;消费者通过zookeeper保存读取的位置offset以及读取的topic的partition分区信息。
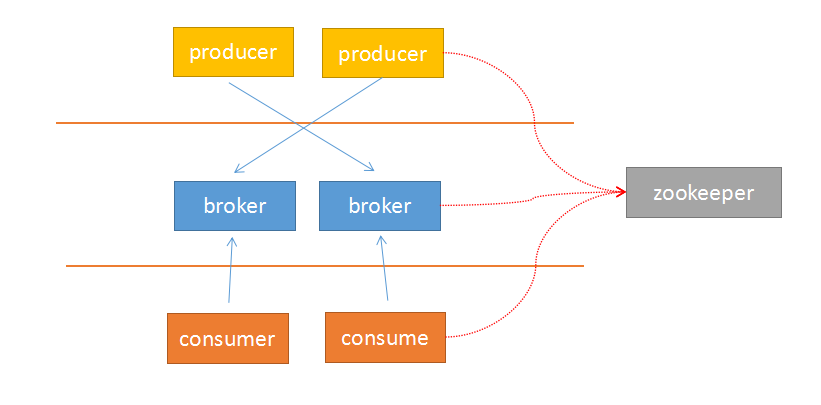
由于上面的架构设计,使得生产者与broker相连;消费者与zookeeper相连。有了这样的对应关系,就容易部署logstash–>kafka–>logstash的方案了。
接下来,按照下面的步骤就可以实现logstash与kafka的对接了。

启动zookeeper
$zookeeper/bin/zkServer.sh start
启动kafka
$kafka/bin/kafka-server-start.sh $kafka/config/server.properties &
创建主题
$kafka/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --topic hello --replication-factor 1 --partitions 1
查看主题
$kafka/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --describe
测试环境
执行生存者脚本
$kafka/bin/kafka-console-producer.sh --broker-list 10.0.67.101:9092 --topic hello
执行消费者脚本
$kafka/bin/kafka-console-consumer.sh --zookeeper 127.0.0.1:2181 --from-beginning --topic hello
测试输入
input{stdin{}}output{kafka{topic_id => "hello"bootstrap_servers => "192.168.0.4:9092" # kafka的地址batch_size => 5}stdout{codec => rubydebug}}
读取测试
input{kafka {codec => "plain"group_id => "logstash1"auto_offset_reset => "smallest"reset_beginning => truetopic_id => "hello"#white_list => ["hello"]#black_list => nilzk_connect => "192.168.0.5:2181" # zookeeper的地址}}output{stdout{codec => rubydebug}}
作者:曹小贱
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

