MySQL索引-组合索引
示例数据
-- 创建表 create table table1( col1 int primary key, col2 int, col3 int, col4 int, col5 varchar(20) ) engine=INNODB; -- 插入数据 insert into table1 values(4, 3, 1, 1, 'd'); insert into table1 values(1, 1, 1, 1, 'a'); insert into table1 values(8, 8, 8, 8, 'h'); insert into table1 values(2, 2, 2, 2, 'b'); insert into table1 values(5, 2, 3, 5, 'e'); insert into table1 values(3, 3, 2, 2, 'c'); insert into table1 values(7, 4, 5, 5, 'g'); insert into table1 values(6, 6, 4, 4, 'f'); -- 添加组合索引 alter table table1 add index idx_table1_col234(col2, col3, col4);
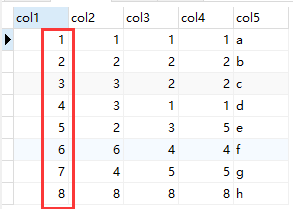
查询SQL:select * from table1; 默认按主键从小到大排序,如下图所示
组合索引原理
组合索引排序规则:先比较第一个列值的大小进行排序,如果相同,再比较第二列值的大小进行排序,如果再相同,再比较第三列值的大小...依次进行排序。
组合索引(没有主键索引的情况)如下图所示:
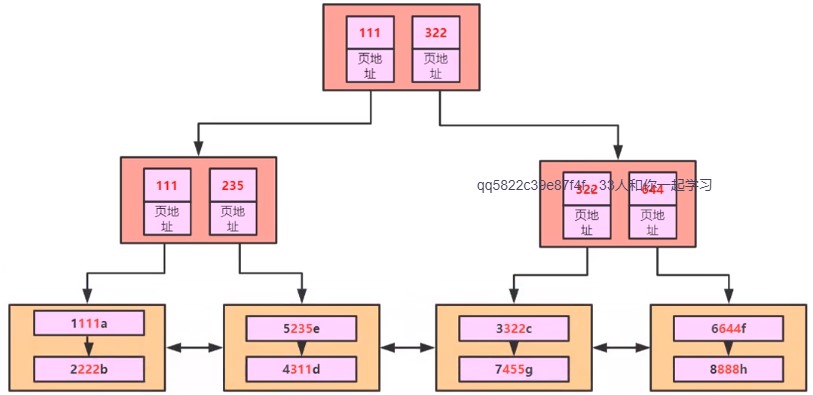
如图所示
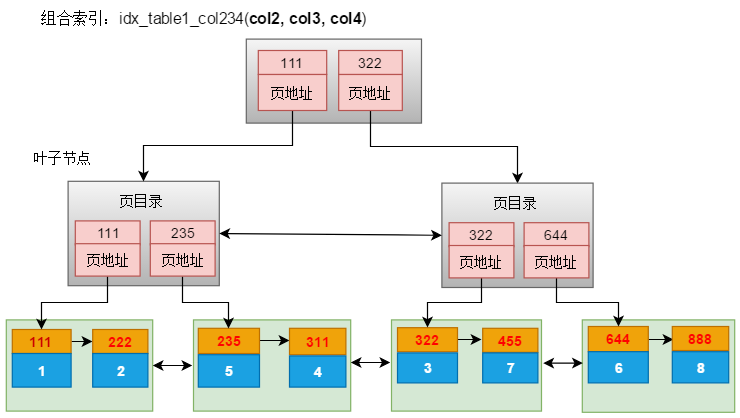
说明:111,表示col2,col3,col4的组合值,蓝色表示主键
假设:
- select * from table1 where col2 =2 and col3 =2 and col4 = 5;相当于查询索引值 = 225;
- select * from table1 where col2 =2 and col3 =2;相当于查询索引值 = 22*;
- select * from table1 where col2 =2;相当于查询索引值 = 2**;
假设:
- select * from table1 where col3 =2 and col4 = 5; 即相当于查询”索引值“ = *25,无法确定其值的大小。索引失效
(1)为什么范围后面的索引全失效?
组合索引中未遵循最左例原则的情况下,索引失效,这个好理解,但是当最左列为范围查找时,后面那些列的索引不会用到,为什么?
(2)为什么有时候明明用了索引而不走索引?
select col2, col5 from table1 where col2 > 3; -- 走索引 select col2 from table1;-- 走索引 select col2 from table1 where col2 > 1; -- 走索引 select col2, col5 from table1 where col2 > 1; -- 不走索引 select col1, col2 from table1 where col2 > 1; -- 走索引
原因:
当执行查询select col2, col5 from table1 where col2 > 1 时,查询出来一共会有7条记录(总记录8条),因为非聚簇索引,索引与数据是分开的,因此每查询出来一条数据都要回表查询一次,这里共要回表7次;即走索引时,需要回表查询7次,7次IO,而全表扫描时4次,4次IO,mysql优化器自动帮你选择了走全表扫描。
当执行查询select col1, col2 from table1 where col2 > 1 时,因为col1属于主键索引,并且数据保存在该组合索引的节点上,因此不需要回表查询,也就走索引。
(3)发生类型转换时不走索引的原因
select * from table1 where col1 = 'a'; -- 不走索引,字符a会默认转换为数字0(所有字符都会转换为0) select * from table1 where col5 = 1; -- 不走索引,mysql会将col5列所有字段全部转换为int类型,因此为不走索引,全表扫描; 同理 select * from table1 where col1 + 1 = 5;--也不会走索引,mysql会将 col1列所有字段全部+1操作,所有列全部操作一次,就相当于进行了一次全表扫描

 浙公网安备 33010602011771号
浙公网安备 33010602011771号