MySQL索引-聚簇索引
概念
聚簇索引:聚簇顾名思义,聚集在一起,即索引和数据是存放同一个文件中。其叶子节点中存放的就是整张表的行记录数据,也将聚集索引的叶子节点称为数据页。InnoDB引擎使用的是非聚簇索引。
非聚簇索引:索引文件和数据文件是分开的。MyISAM引擎默认使用的是非聚簇索引。
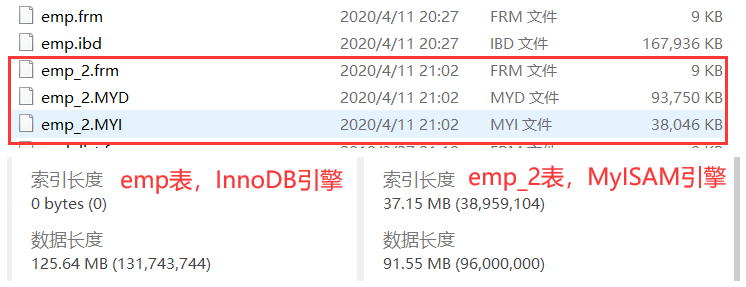
如下图所示:
emp表是通过InnoDB引擎创建的表,emp表有一个emp.ibd这一个文件
emp_2表是通过MyISAM引擎创建的表,emp_2表有两个文件,即emp_2.myd(数据文件)和emp_2.myi(索引树文件)
主要特征如下:
1.innodb如果不设置主键,默认会找一个唯一的且不为NULL的列作为其隐式主键!如果设置了主键,则以主键构造一颗B+树,叶子节点存放数据行;
2.聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针;
3.在InnoDB中,主键索引就是聚簇索引。MyISAM中主键索引为非聚簇索引,因为其数据文件与索引文件是分开的;
4.InnoDB中非聚簇索引与数据是分开的,但是保存在同一个文件中;
5.一个表只能拥有一个聚集索引,可以有多个非聚集索引;
6.聚簇索引中的每个叶子节点包含主键值、事务ID、回滚指针(rollback pointer用于事务和MVCC)和余下的列(如col2);
为了加深理解,以Innodb的一个主键索引为例(备注:这里画的是BTree方便大家理解,而MySQL用的是B+Tree结构比这个复杂的多):
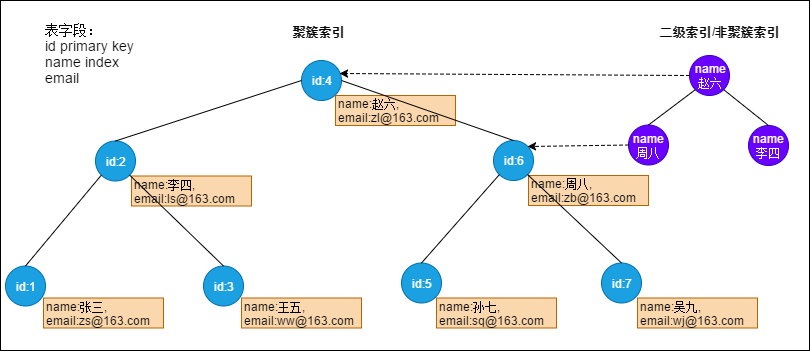
主键索引就是一种聚簇索引,二级索引就是非聚簇索引。
从上图我们可以看出二级索引/非主键索引的叶子节点存储的不是记录的指针,而是主键的值。对于二级索引的查询,会查询两棵B+树。先去二级索引查询,再去主键索引去查(回表查询)。
Innodb中,叶子节点较大,直接在叶子节点存放字段如name、email字段。在查找的过程中,当找到了叶子节点的时候,相应就数据就找到了,无需回到磁盘上取数据。这也就是为什么通过主键索引查找要远远高于二级索引的效率的原因。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号