MySQL索引-页结构
前言
首先思考一个问题,MySQL可以通过索引提高查询效率,但是有时候某个索引大到达几十个G远远超过了内存的容量MySQL不可能把整个索引全部加载到内存,然后通过查找算法(二叉查找)去查找,MySQL是如何处理这个问题的?
这里MySQL就用到了操作系统中页的概念,操作系统中页的概念是什么?就是加载其中一页的数据到内存,然后在内存中读取,当下一条指令再执行读取数据时,就可以用到这一页的数据,而不用去硬盘中读取( 磁盘IO);
MySQL通过将索引拆分成页,一页为其最小数据单元,每次读取数据时,加载其中某几页数据即可。
MySQL这种页结构,与书的目录结构几乎一样,如假设有一个非常非常厚的书籍....
概念
页可分为索引页和数据页
如下图所示为一个页的结构,数据存储最小单元,mysql默认为16 kb。B+Tree中的一个叶子节点是一页。
所有InnoDB的索引是B树,其中索引记录被存储在树的树叶页。一个索引页的默认大小是16KB。当新记录被插入,InnoDB试着为将来索引记录的插入和更新留下十六分之一的空白页。
如果索引记录以连续的顺序被插入(升序或者降序),结果索引页大约是15/16满。如果记录被以随机的顺序被插入,页面是从1/2到 15/16满。如果索引页的填充因子降到低于1/2,InnoDB试着搜索索引树来释放页。
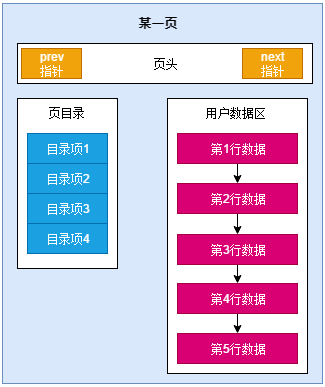
页结构图
图示说明: 1111a,分别表示col1,col2,col3,col4,col5 五列数据。红色标记为以主键构造的主键索引,也为聚簇索引。
用户数据区:数据为链表结构,对于链表结构而言,插入性能较高,而查询性较低,因此这个链表的长度不会很长,那么mysql是怎么解决这个问题的呢?当然是通过页目录来解决。
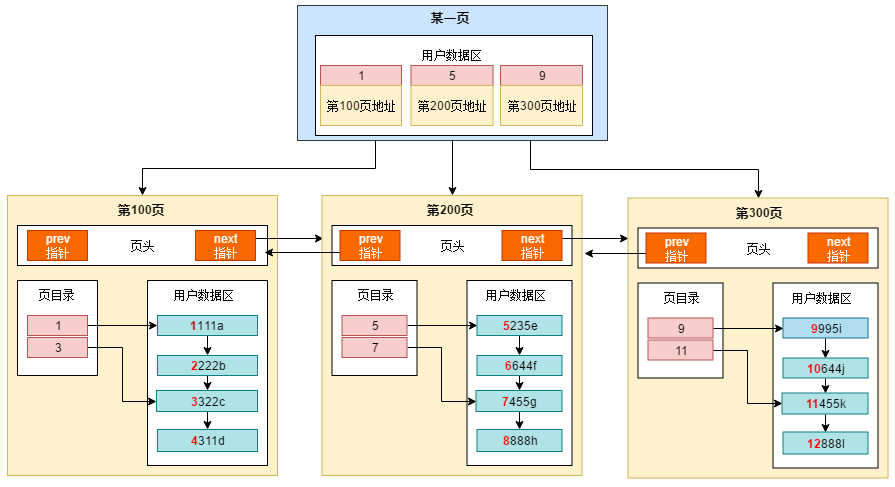
索引结构图
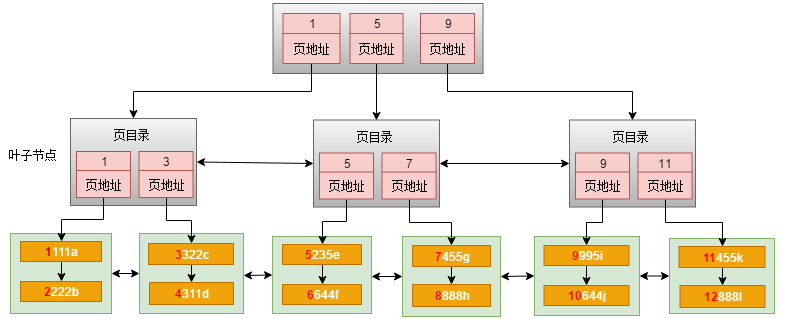
(1)为什么页之间会有一个指针?为什么是双向链表结构?
当进行范围查询时,如select * from table where id > 3;
首先先会根据索引查找到id=3的那条记录,然后根据next或prev指针横向查找到所有数据行。
(2)什么情况下走索引?
当查找时是从上至下进行查找,则认为是走索引的。当查找时是从左至右进行查找时,则为全索引扫描。
(3)为什么非叶子节点不存储数据?
树的高度越小,IO次数越少,查询速度就快
(4)为什么推荐使用自增主键?
如果不使用自增主键,容易造成页分裂,其实就是B+Tree 重新构建的过程;而避免页分裂最好的方法就是使用主键自增,提高插入性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号