

Netty——自定义协议通信
前言
为了满足自己业务场景的需要, 应用层之间通信需要实现各种各样的网络协议。本文记录如何设计一个高效、可扩展、易维护的自定义通信协议,以及如何使用 Netty 实现自定义的通信协议。
一、通信协议设计
所谓的协议,就是通信双方事先商量好的接口“暗语”, 在 TCP 网络编程中,发送方和接收方的数据包格式都是二进制,
发送方将对象转化成二进制流发送给接收方,接收方获得二进制数据后需要知道如何解析对象,所以协议是双方能够正常通行的基础。
通用协议
市面上已经有不小通用的协议,例如 HTTP、 HTTPS、JSON-RPC、FTP、IMAP、Protobuf等。通用协议兼容性好,易于维护,各种异构系统间可以实现无缝对接等。
如果满足业务场景及性能需求的前提下,推荐采用通用协议的方案。
自定义协议
在特定的场景下,需要自定义自有协议。自定义协议有以下的优点:
- 极致性能:通用协议考虑很多兼容性的因素,必然在性能有所损失。
- 扩展性:自定义的协议相比通用协议更好扩展,可以更好地满足自己的业务需求。
- 安全性:通用协议是公开的,可能存在很多漏洞。自定义协议通常是私有的,黑客需要先破解协议内容,才能攻破漏洞。
网络协议需要具备的要素
一个较为通用的协议示例:
/* +---------------------------------------------------------------+ | 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte | +---------------------------------------------------------------+ | 状态 1byte | 保留字段 4byte | 数据长度 4byte | +---------------------------------------------------------------+ | 数据内容 (长度不定) | 校验字段 2byte | +---------------------------------------------------------------+ */
- 1. 魔数
魔数是通信双方协商的一个暗号,通常采用固定的几个字节表示。魔数的作用是用于服务端在接收数据时先解析出前几个固定字节做正确性对比。
如果和协议中的魔数不匹配,则认为是非法数据,可以直接关闭连接或采取其他措施增强系统安全性。
魔数的思想在很多场景中都有体现,如 Java Class 文件开头就存储了魔数 OxCAFEBABE,在 JVM 加载 Class 文件时首先就会验证魔数对的正确性。
- 2. 协议版本号
为了应对业务需求的变化,可能需要对自定义协议的结构或字段进行改动。不同版本的协议对应的解析方法也是不同的。所以在生产级项目中强烈建议预留协议版本这个字段。
-
3. 序列化算法
序列化算法字段表示发送方将对象转换成二进制流,以及接收方将接收的二进制流转换成对象的方法,如 JSON、 Hessian、Java 自带序列化等。
-
4. 报文类型
报文类型用于描述业务场景中存在的不同报文类型。如 RPC 框架中有请求、响应、心跳类型。IM 通讯场景中有登陆、创建群聊、发送消息、接收消息、退出群聊等类型。
-
5. 长度域字段
长度域字段代表请求数据的长度,可以定义整个报文的长度,也可以是请求数据部分的长度。
-
6. 请求数据
请求数据通常为的业务对象信息序列化后的二进制流。是整个报文的主体。
-
7. 状态
状态字段用于标识请求是否正常,一般由被调用方设置。例如一次 RPC 调用失败,状态字段可被服务提供方设置为异常状态。
- 8. 校验字段
校验字段存放某种校验算法计算报文校验码,校验码用于验证报文的正确性。
- 9. 保留字段
保留字段是可选项,为了应对协议升级的可能性,可以预留若干字节的保留字段,以备不时之需。
二、Netty 实现自定义通信协议
Netty 作为一个非常优秀的网络通信框架,提供了非常丰富的编解码抽象基类来实现自定义协议。
Netty 中编解码器分类
编码解码分类:
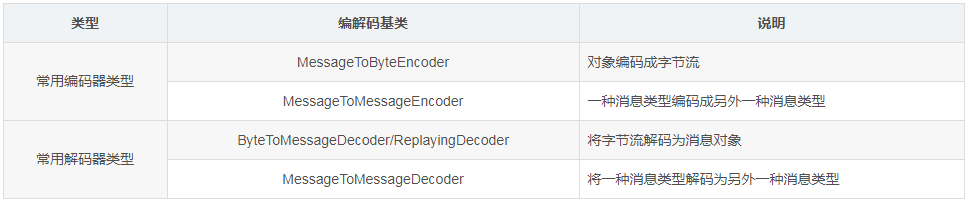
分层解码分类:
一次解码:一次解码用于解决 TCP 拆包/粘包问题,按协议解析得到的字节数据。常用一次编解码器:MessageToByteEncoder / ByteToMessageDecoder。
二次解码:对一次解析后的字节数据做对象模型的转换,这时候需要二次解码器,同理编码器的过程是反过来的。常用二次编解码器:MessageToMessageEncoder / MessageToMessageDecoder。
抽象编码类
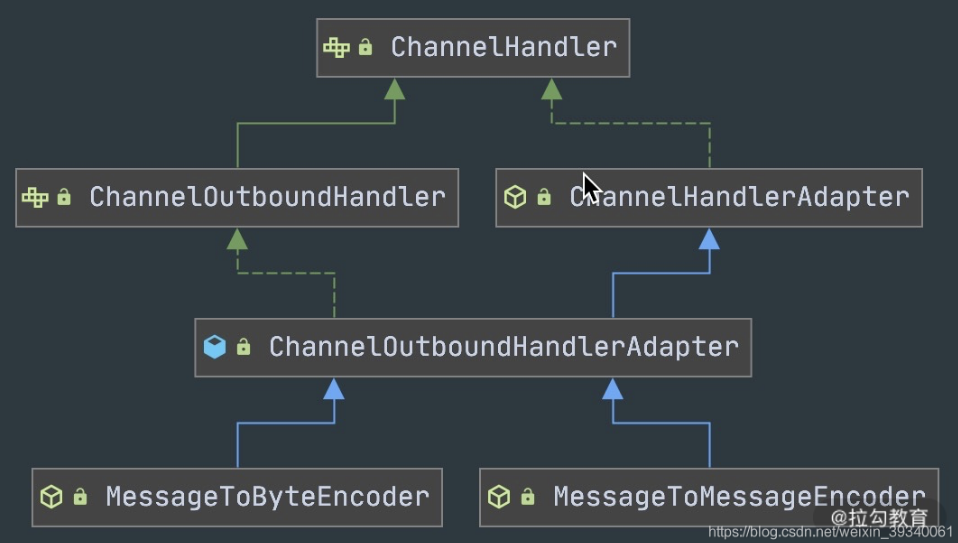
通过抽象编码类的继承图可以看出,编码类是 ChanneOutboundHandler 的抽象类实现,具体操作的是 Outbound 出站数据。
抽象解码类
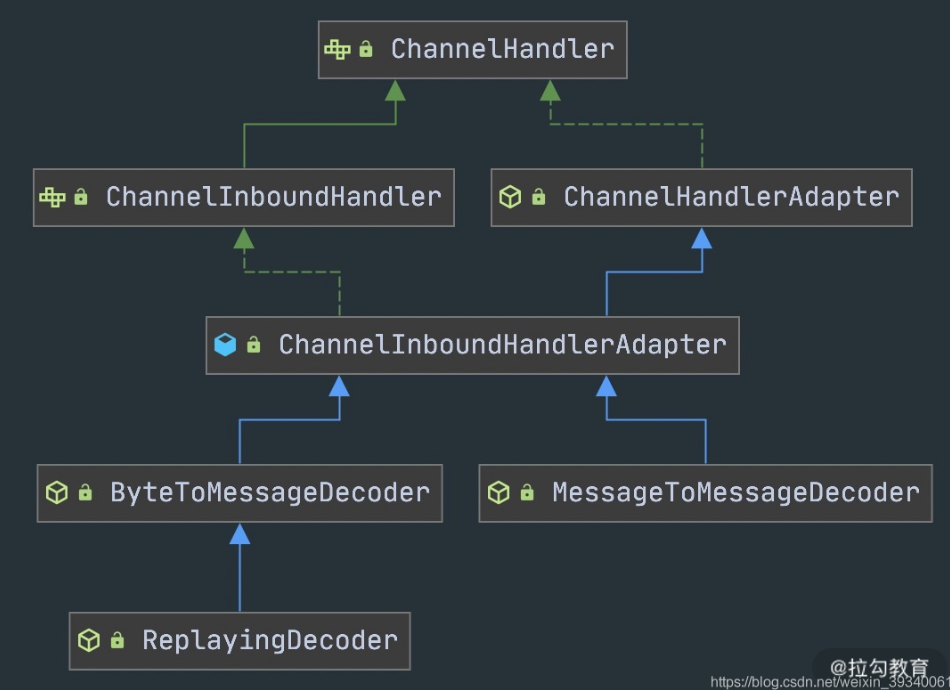
解码类是 ChanneInboundHandler 的抽象类实现,操作的是 Inbound 入站数据。解码器的主要难度在于拆包和粘包问题,
由于接收方可能没有接受到完整的消息,所以编码框架还要对入站数据做缓冲处理,直到获取到完整的消息。
三、通信协议实战
/* +---------------------------------------------------------------+ | 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte | +---------------------------------------------------------------+ | 状态 1byte | 保留字段 4byte | 数据长度 4byte | +---------------------------------------------------------------+ | 数据内容 (长度不定) | +---------------------------------------------------------------+ */
对以上的自定义报文,协议头部包含了魔数、协议版本号、数据长度等固定字段。而 ByteBuf 是否完整,需要通过消息长度 dataLength 字段来判断。
自定义编码器需要重写 ByteToMessageDecoder 的 encode 方法,具体代码如下所示:
@Override public final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) { // 判断 ByteBuf 可读取字节 if (in.readableBytes() < 14) { return; } in.markReaderIndex(); // 标记 ByteBuf 读指针位置 in.skipBytes(2); // 跳过魔数 in.skipBytes(1); // 跳过协议版本号 byte serializeType = in.readByte(); in.skipBytes(1); // 跳过报文类型 in.skipBytes(1); // 跳过状态字段 in.skipBytes(4); // 跳过保留字段 int dataLength = in.readInt(); if (in.readableBytes() < dataLength) { in.resetReaderIndex(); // 重置 ByteBuf 读指针位置 return; } byte[] data = new byte[dataLength]; in.readBytes(data); SerializeService serializeService = getSerializeServiceByType(serializeType); Object obj = serializeService.deserialize(data); if (obj != null) { out.add(obj); } }
引用:
- https://blog.csdn.net/weixin_39340061/article/details/109611936
- https://blog.csdn.net/qq276726581/article/details/55522144
- https://blog.csdn.net/zbw18297786698/article/details/53691915
- http://zhongm.in/2019/09/25/To-Solve-Two-Problem-In-Using-ByteToMessageDecoder/
- https://vimsky.com/examples/detail/java-method-io.netty.buffer.ByteBuf.markReaderIndex.html


