
Redis——常用命令
一、集群管理
- 启动集群:
# 逐个节点启动 {redisDir}/bin/redis-server {redisDir}/conf/redis_7000.conf {redisDir}/bin/redis-server {redisDir}/conf/redis_7001.conf {redisDir}/bin/redis-server {redisDir}/conf/redis_7002.conf # 批量启动节点(写入批处理文件中): [root@manager-node bin]# cat cluster_start.sh {redisDir}/redis-server {redisDir}/conf/redis_7000.conf {redisDir}/redis-server {redisDir}/conf/redis_7001.conf {redisDir}/redis-server {redisDir}/conf/redis_7002.conf
- 关闭集群:
# 逐个节点关闭 {redisDir}/bin/redis-cli -h 192.168.10.81 -p 7000 shutdown {redisDir}/bin/redis-cli -h 192.168.10.81 -p 7001 shutdown {redisDir}/bin/redis-cli -h 192.168.10.81 -p 7002 shutdown 或者 ps -ef|grep redis-server kill {pid}
# 批量关闭节点
pgrep redis-server | xargs -exec kill -9
- 查看集群信息:
cluster info
结果说明:
cluster_state #集群的状态。ok表示集群是成功的,如果至少有一个solt坏了,就将处于error状态。 cluster_slots_assigned #有多少槽点被分配了,如果是16384,表示全部槽点已被分配。 cluster_slots_ok #多少槽点状态是OK的, 16384 表示都是好的。 cluster_slots_pfail #多少槽点处于暂时疑似下线[PFAIL]状态,这些槽点疑似出现故障,但并不表示是有问题,也会继续提供服务。 cluster_slots_fail #多少槽点处于暂时下线[FAIL]状态,这些槽点已经出现故障,下线了。等待修复解决。 cluster_known_nodes #已知节点的集群中的总数,包括在节点 握手的状态可能不是目前该集群的成员。 cluster_size #(The number of master nodes serving at least one hash slot in the cluster) 简单说就是集群中主节点[Master]的数量。 cluster_current_epoch #本地当前时期变量。这是使用,以创造独特的不断增加的版本号过程中失败接管。{不懂} cluster_my_epoch #这是分配给该节点的当前配置版本。{不懂} cluster_stats_messages_sent #通过群集节点到节点的二进制总线发送的消息数。 cluster_stats_messages_received #通过群集节点到节点的二进制总线上接收报文的数量。
- 查看集群节点:
cluster nodes
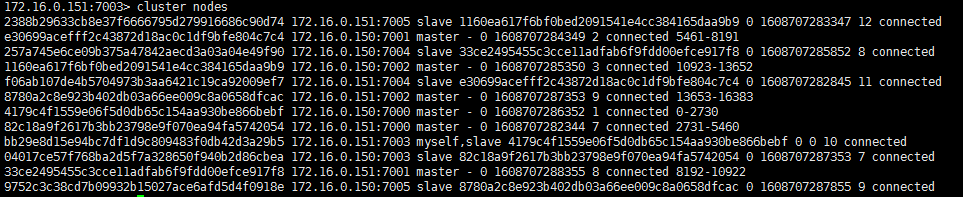
每一条结构说明:
<id> <ip:port> <flags> <master> <ping-sent> <pong-recv> <config-epoch> <link-state> <slot> <slot> ... <slot>
[节点id] [ip:端口] [标志(master、myself、salve)] [(- 或者主节id)] [ping发送的毫秒UNIX时间,0表示没有ping] [pong接收的unix毫秒时间戳] [配置-epoch] [连接状态] [槽点]
- 加入集群
将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子
cluster meet <ip> <port>
192.168.0.2:7000> cluster meet 192.168.0.2 7006 OK 192.168.0.2:7000> cluster nodes … 70795a3a7b93b7d059124e171cd46ba1683d6b7d 192.168.0.2:7006 master - 0 1446198910590 0 connected
现在7009已经成功加入到来集群当中,但是,还没有分配槽点给它。槽点分配在下面的命令中再仔细说。
- 从集群中移除
从集群中移除一个节点。
cluster forget <node_id>
192.168.0.2:7000> cluster forget 70795a3a7b93b7d059124e171cd46ba1683d6b7d OK
提示OK了,说明已经成功了。
- 副本信息:
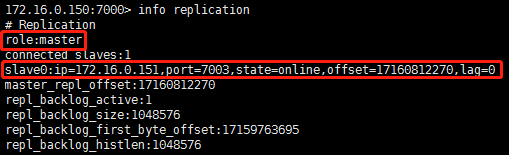
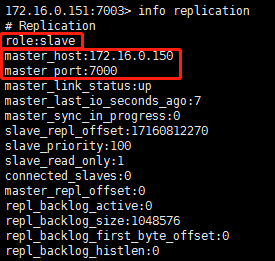
info replication
Master:
Slave:
- 将当前节点设置为 node_id 指定的节点的从节点
cluster replicate <master_nodeId> # 在相应的从节点上执行
- 添加节点
当集群的压力比较大时,可以通过动态的扩容提高集群的写读并发能力
# 添加主节点 redis-cli --cluster add-node ip3:7007 ip1:7001
使用add-node添加集群节点,第一个地址参数为要添加的redis实例地址,第二个参数为集群中任意一个实例地址,节点会默认被添加为主节点,请注意这个时候添加的主节点与其他的master相比具有两个特点
- 它没有数据,因为它没有分配哈希槽
- 因为它是没有分配插槽的设备,所以当从节点想成为主节点时,它不参与选举过程
添加成功的标识:

# 添加从节点 redis-cli --cluster add-node ip3:7007 ip1:7001 --cluster-slave
上述会把ip3:7007实例作为集群的从节点加入到集群中,会挑选拥有从服务器数量最少的主服务器,然后把新加入的节点作为该主服务器的从节点。
- 重新整理集群
当使用上述方式添加完主节点之后,添加进入的节点为空,并没有分配任何槽,此时我们需要执行reshard操作,为新添加的主节点分配插槽,已达到分担集群压力,提高并发能力的目的。
-
- 1:开启重新分片(reshard)操作
redis-cli -h ip1 -p 7001 --cluster reshard ip1:7001
-
- 2:指定需要重新reshard的slots的个数

-
- 3:指定接收这些slots的插槽的目的节点id

-
- 4:指定分配这些slots的插槽的源节点id,输入done为结束符
Source node #1:ca33b3d7a60f8df7b74473f86c11f84df609fa45 Source node #2:done
- 删除节点
当系统负载压力比较小的时候,为了避免耗费资源,可以选择动态的删除节点,命令如下所示:
redis-cli -h ip1 -p 7001 --cluster del-node ip1:7001 node-id
使用上述方式删除节点的时候,当删除节点为从节点的时候可以直接删除,当删除节点为主节点的时候,则必须主节点不为空,即需要把主节点的插槽及插槽中的数据分配给其他的主节点。
- 槽(slot)
cluster addslots <slot> [slot ...] :将一个或多个槽( slot)指派( assign)给当前节点。 cluster delslots <slot> [slot ...] :移除一个或多个槽对当前节点的指派。 cluster flushslots :移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。 cluster setslot <slot> node <node_id> :将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
cluster setslot <slot> migrating <node_id> :将本节点的槽 slot 迁移到 node_id 指定的节点中。
cluster setslot <slot> importing <node_id> :从 node_id 指定的节点中导入槽 slot 到本节点。
cluster setslot <slot> stable :取消对槽 slot 的导入( import)或者迁移( migrate)。
- 键
cluster keyslot <key> :计算键 key 应该被放置在哪个槽上。 cluster countkeysinslot <slot> :返回槽 slot 目前包含的键值对数量。 cluster getkeysinslot <slot> <count> :返回 count 个 slot 槽中的键 。
- 保存配置
将节点的配置文件保存到硬盘里面
cluster saveconfig
它会覆盖配置文件夹里的nodes.conf文件。这样做是为了某种情况下nodes文件丢失,这样就会生成一个最新的节点配置文件。
- 删除槽(slot)
移除当前节点的一个或多个槽点。只能删除自己的节点,删除别人的没用。因为master才会有槽点,所以,也是只能在master 节点上操作,在slave 操作也没用。
用法是:
cluster delslots slots1 slotes2 slots3
示例:
我们看一下槽点的分配情况:
[root@web3 7009]# redis-cli -p 7009 -c cluster nodes| grep master 3d2b7dccfc45ae2eb7aeb9e0bf001b0ac8f7b3da 192.168.33.13:7000 master - 0 1448529511113 1 connected 0-4095 404cf1ecf54d4df46d5faaec4103cfdf67888ad2 192.168.33.13:7001 master - 0 1448529511113 2 connected 4096-8191 6f5cd78ee644c1df9756fc11b3595403f51216cc 192.168.33.13:7002 master - 0 1448529509101 3 connected 8192-12287 35bdcb51ceeff00f9cc608fa1b4364943c7c07ce 192.168.33.13:7003 master - 0 1448529510609 4 connected 12288-16383
4台master,那就把16381 16382 16383 3个槽点给删掉。开始: [root@web3 7009]# redis-cli -p 7003 127.0.0.1:7003> cluster delslots 16381 16382 16383 OK
127.0.0.1:7003> cluster nodes 35bdcb51ceeff00f9cc608fa1b4364943c7c07ce 192.168.33.13:7003 myself,master - 0 0 4 connected 12288-16380 看,7003的缺失少了3个节点。我们在看下cluster info 127.0.0.1:7003> cluster info cluster_state:fail cluster_slots_assigned:16381 cluster_slots_ok:16381 只有16381个,确实少了4个。但是,注意:cluster_state:fail,集群失败了!!! 为什么呢?为什么删除了3个槽点就失败了呢。因为集群就是要满足所有的16364个槽点全部分配才会成功。所以。就失败了。
那如何挽救呢?那就顺便看下面的增加糟的这个命令吧。
- 增加槽(slot)
将一个或多个槽(slot)指派(assign)给当前节点。
cluster addslots
用法是:
cluster addslots slots1 slotes2 slots3
示例:
那,我就用这个命令将上面删掉的3个槽点再加到7003上看看: 127.0.0.1:7003> cluster addslots 16381 16382 16383 OK OK了,看下是不是真的成功了: 127.0.0.1:7003> cluster nodes 35bdcb51ceeff00f9cc608fa1b4364943c7c07ce 192.168.33.13:7003 myself,master - 0 0 4 connected 12288-16383 确实回来了,再看下集群状态,启动了没? 127.0.0.1:7003> cluster info cluster_state:ok
二、重建集群
- 1、停止每个节点的服务
# 逐个节点关闭 {redisDir}/bin/redis-cli -h 10.0.102.51 -p 7000 shutdown {redisDir}/bin/redis-cli -h 10.0.102.51 -p 7001 shutdown {redisDir}/bin/redis-cli -h 10.0.102.51 -p 7002 shutdown
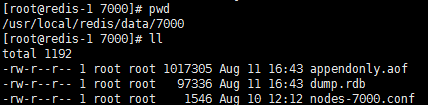
- 2、删除数据
删除每个节点data目录下aof、rdb、nodes.conf本地备份文件,删除每个节点log目录下的日志文件
- 3、清空当前数据库(这一步可以省略)
./redis-cli -c -p 7000 -h 10.0.102.51 flushdb ./redis-cli -c -p 7001 -h 10.0.102.51 flushdb ./redis-cli -c -p 7002 -h 10.0.102.51 flushdb
- 4、启动每个节点服务
# 逐个节点启动 {redisDir}/bin/redis-server {redisDir}/conf/redis_7000.conf {redisDir}/bin/redis-server {redisDir}/conf/redis_7001.conf {redisDir}/bin/redis-server {redisDir}/conf/redis_7002.conf
- 5、重新执行创建集群命令
./redis-cli --cluster create 10.0.102.51:7000 10.0.102.52:7000 10.0.102.53:7000 10.0.102.51:7001 10.0.102.52:7001 10.0.102.53:7001 10.0.102.51:7002 10.0.102.52:7002 10.0.102.53:7002 10.0.102.51:7003 10.0.102.52:7003 10.0.102.53:7003 --cluster-replicas 1
注:以上创建集群的命令,在其中一个节点上执行即可。
- 6、登录集群查看节点信息
登陆其中一个节点,执行以下命令查看:
./redis-cli -c -p 7000 -h 10.0.102.51
10.0.102.51:7000> cluster info cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:12 cluster_size:6 cluster_current_epoch:12 cluster_my_epoch:1 cluster_stats_messages_ping_sent:370903 cluster_stats_messages_pong_sent:371514 cluster_stats_messages_publish_sent:9570 cluster_stats_messages_sent:751987 cluster_stats_messages_ping_received:371503 cluster_stats_messages_pong_received:370900 cluster_stats_messages_meet_received:11 cluster_stats_messages_publish_received:6551 cluster_stats_messages_received:748965
10.0.102.51:7000> cluster nodes 242bd7bab3869af03cae3bc8ca77ca0a7575f0e7 10.0.102.52:7001@17001 master - 0 1628671953591 5 connected 10923-13652 85ec3c81e7b213d7e1554b1fa18ba84ed2c7503b 10.0.102.52:7002@17002 slave 9b52daaa90ab1cc9132d8db625f8a1f697e4b657 0 1628671953000 1 connected 76d9f356a2d9721d6d7d901d756471d5d93d1eed 10.0.102.53:7003@17003 slave 242bd7bab3869af03cae3bc8ca77ca0a7575f0e7 0 1628671953091 5 connected de2aaebd660f01e1b54f4b94220ad5a5ea7e1b0b 10.0.102.53:7002@17002 slave b62cc30408d60a6ec29357e3ac8e5e2c51cd7415 0 1628671954593 2 connected 6b8e6dfdfc2d9dfd657c2c858ef3fc44781c34f8 10.0.102.51:7003@17003 slave 633710ef9f9269bad592e12cde5d0d24858f8d99 0 1628671953591 3 connected b62cc30408d60a6ec29357e3ac8e5e2c51cd7415 10.0.102.52:7000@17000 master - 0 1628671953000 2 connected 2731-5460 ea06a2c9f72d17fad10d6ccc6b03af94a51511b5 10.0.102.53:7001@17001 master - 0 1628671954092 6 connected 13653-16383 9b52daaa90ab1cc9132d8db625f8a1f697e4b657 10.0.102.51:7000@17000 myself,master - 0 1628671952000 1 connected 0-2730 633710ef9f9269bad592e12cde5d0d24858f8d99 10.0.102.53:7000@17000 master - 0 1628671953591 3 connected 5461-8191 554ce97679c311741a84d75d540b34dc1c87d9d5 10.0.102.51:7002@17002 slave ea06a2c9f72d17fad10d6ccc6b03af94a51511b5 0 1628671953000 6 connected 1c59253e898313d31e4fd6af983cd597b7a2584a 10.0.102.51:7001@17001 master - 0 1628671954000 4 connected 8192-10922 b75a7c5e5d77b5b8b287d537429fc71ce3ba3625 10.0.102.52:7003@17003 slave 1c59253e898313d31e4fd6af983cd597b7a2584a 0 1628671954592 4 connected
三、集群节点损坏修复
问题现象
启动集群后,有些节点没启动成功,检查log文件显示如下信息:
Unrecoverable error: corrupted cluster config file.
这种情况,因为集群cluster-config-file文件损坏引起,导致该节点无法启动。
修复方案
- 首先在各个node上移除该出错节点
- 删除该cluster-config-file文件
- 重新启动该节点
- 将该节点加入集群
- 指定该节点的master,将该节点以slave加入集群(本次修复未执行,集群自动恢复正常)
实施步骤
- 一、首先在各个node上移除该出错节点
执行以下脚本,将fail节点移除出集群,该操作仅移除一个机器中的无用节点信息,如果是多个机器,请在相应的节点上执行多次
./redis-cli -c -h 7000 -p 10.0.102.51 cluster forget $nodeid
- 二、停止出错节点服务
ps -ef|grep redis-server kill -9 pid
- 三、删除该cluster-config-file文件
mv nodes-7000.conf nodes-7000.conf.bak
- 四、启动该节点
{redisDir}/bin/redis-server {redisDir}/conf/redis_7000.conf
- 五、将该节点加入集群
在集群任意instance 执行以下命令
CLUSTER MEET <ip> <port> //将ip和port所指定的节点添加到集群当中,让它成为集群的一份子
- 六、指定该节点的master,将该节点以slave加入集群
在此次修复场景中未进行第五步,集群自动分配成为不均衡节点的slave
如果集群未自动分配,在需要加入集群的实例上执行,指定为某一个master的slave
CLUSTER REPLICATE <node_id> //将当前节点设置为 node_id 指定的节点的从节点。
四、其它
- 查看内存使用情况
info memory

- 检查集群状态
redis-cli --cluster check 172.16.0.89:7000
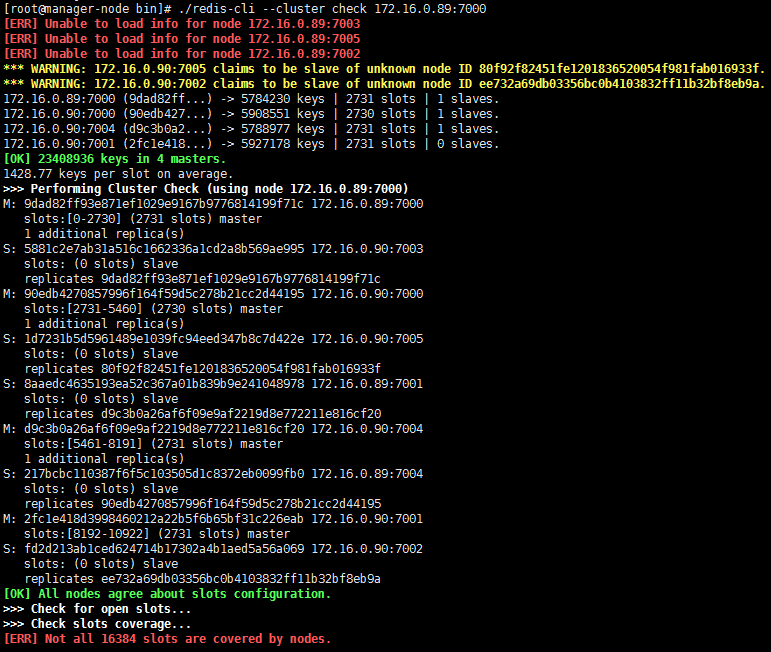
- 修复集群状态
redis-cli --cluster fix 127.0.0.1:6379

