

HBase——Snapshot(快照)
前言
HBase数据迁移方案有很多种,但今天我们来通过Snapshot方式来实现HBase的数据迁移(即将A集群HBase的数据迁移到B集群)。
HBase Snapshots允许你对一个表进行快照(即可用副本),它不会对Region Servers产生很大的影响,它进行复制和恢复操作的时候不包括数据拷贝。
导出快照到另外的集群也不会对Region Servers产生影响。
一、使用场景
snapshot是HBase非常核心的一个功能,使用snapshot的不同用法可以实现很多功能,比如:
1.全量/增量备份
任何数据库都需要有备份的功能来实现数据的高可靠性,snapshot可以非常方便的实现表的在线备份功能,并且对在线业务请求影响非常小。
使用备份数据,用户可以在异常发生的情况下快速回滚到指定快照点。增量备份会在全量备份的基础上使用binlog进行周期性的增量备份。
- 使用场景一:通常情况下,对重要的业务数据,建议至少每天执行一次snapshot来保存数据的快照记录,并且定期清理过期快照,这样如果业务发生重要错误需要回滚的话是可以回滚到之前的一个快照点的。
- 使用场景二:如果要对集群做重大的升级的话,建议升级前对重要的表执行一次snapshot,一旦升级有任何异常可以快速回滚到升级前。
2.数据迁移
可以使用ExportSnapshot功能将快照导出到另一个集群,实现数据的迁移。
- 使用场景一:机房在线迁移,通常情况是数据在A机房,因为A机房机位不够或者机架不够需要将整个集群迁移到另一个容量更大的B集群,而且在迁移过程中不能停服。
基本迁移思路是先使用snapshot在B集群恢复出一个全量数据,再使用replication技术增量复制A集群的更新数据,等待两个集群数据一致之后将客户端请求重定向到B机房。
- 使用场景二:使用snapshot将表数据导出到HDFS,再使用Hive\Spark等进行离线OLAP分析,比如审计报表、月度报表等。
二、使用方法
开启快照支持
在0.95+之后的版本都是默认开启的,在0.94.6+是默认关闭
<property> <name>hbase.snapshot.enabled</name> <value>true</value> </property>
创建快照
- 在原集群上,用snapshot命令创建快照
hbase> snapshot 'ZAT_TRACE',’SNAPSHOT_ZAT_TRACE_20200904093200'
- 查看创建的快照,用list_snapshots命令
hbase> list_snapshots
- 如果快照创建有问题,可以先删除,用delete_snapshot命令
hbase> delete_snapshot 'SNAPSHOT_ZAT_TRACE_20200904093200'
- 创建完快照后在/hbase根目录会产生一个目录
[user_w@emr-header-1 ~]$ hadoop fs -ls hdfs://172.16.120.199:9000/hbase/.hbase-snapshot/ #子目录下有如下几个文件 Found 2 items drwxr-x--x - hbase hadoop 0 2018-11-29 10:54 hdfs://172.16.120.199:9000/hbase/.hbase-snapshot/.tmp drwxr-x--x - hbase hadoop 0 2018-11-29 10:54 hdfs://172.16.120.199:9000/hbase/.hbase-snapshot/SNAPSHOT_ZAT_TRACE_20200904093200
数据迁移
在上面创建好快照后,使用ExportSnapshot命令进行数据迁移,ExportSnapshot也是HDFS层的操作,本质还是利用MR进行迁移,
这个过程主要涉及IO操作并消耗网络带宽,在迁移时要指定下map数和带宽,不然容易造成机房其它业务问题,
如果是单独的MR集群,可以在MR集群上使用如下命令:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \ -snapshot SNAPSHOT_ZAT_TRACE_20200904093200 \
-copy-from hdfs://172.16.120.199:9000/hbase \ -copy-to hdfs://172.16.120.213:9000/hbase \
-mappers 16 \
-bandwidth 1024\
快照恢复数据
- 恢复指定快照,恢复过程会替代原有数据,将表还原到快照点,快照点之后的所有更新将会丢失。它需要先禁用表,再进行恢复
hbase> disable 'ZAT_TRACE' hbase> restore_snapshot 'SNAPSHOT_ZAT_TRACE_20200904093200' hbase> enable 'ZAT_TRACE'
- 根据快照恢复出一个新表,恢复过程不涉及数据移动,可以在秒级完成。
hbase> clone_snapshot 'SNAPSHOT_ZAT_TRACE_20200904093200','ZAT_TRACE_NEW'
- 检查HBase数据是否迁移成功
hbase> scan 'ZAT_TRACE'
hbase> count 'ZAT_TRACE'
验证数据
通过HBase自带的VerifyReplication工具,验证两个集群的数据是否一致:
hbase org.apache.hadoop.hbase.mapreduce.replication.VerifyReplication -mappers 10 -bandwidth 1024 1 ZAT_TRACE
数据一致结果:

数据不一致结果:
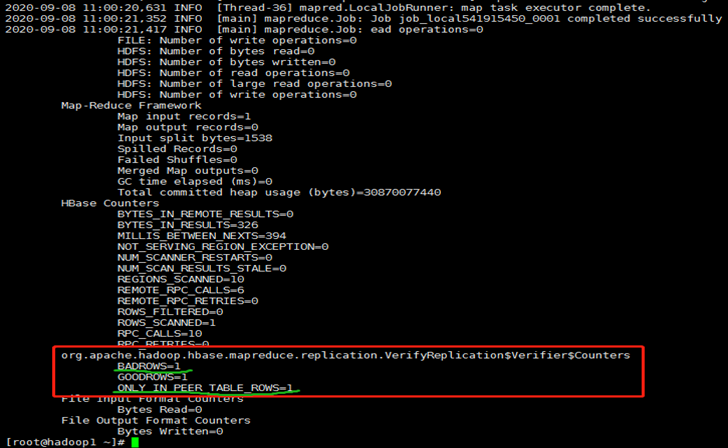
注:只有GOODROWS时,说明集群间的数据一致;存在BADROWS或ONLY_IN_PEER_TABLE_ROW时,说明集群间的数据不一致。
验证命令说明:
#命令: hbase org.apache.hadoop.hbase.mapreduce.replication.VerifyReplication [--starttime=timestamp1] [--stoptime=timestamp] [--families=comma separated list of families] peerId tableName #命令参考: bash-4.2$ ./bin/hbase org.apache.hadoop.hbase.mapreduce.replication.VerifyReplication Usage: verifyrep [--starttime=X] [--endtime=Y] [--families=A] [--row-prefixes=B] [--delimiter=] [--recomparesleep=] [--batch=] [--verbose] [--sourceSnapshotName=P] [--sourceSnapshotTmpDir=Q] [--peerSnapshotName=R] [--peerSnapshotTmpDir=S] [--peerFSAddress=T] [--peerHBaseRootAddress=U] Options: starttime beginning of the time range without endtime means from starttime to forever endtime end of the time range versions number of cell versions to verify batch batch count for scan, note that result row counts will no longer be actual number of rows when you use this option raw includes raw scan if given in options families comma-separated list of families to copy row-prefixes comma-separated list of row key prefixes to filter on delimiter the delimiter used in display around rowkey recomparesleep milliseconds to sleep before recompare row, default value is 0 which disables the recompare. verbose logs row keys of good rows sourceSnapshotName Source Snapshot Name sourceSnapshotTmpDir Tmp location to restore source table snapshot peerSnapshotName Peer Snapshot Name peerSnapshotTmpDir Tmp location to restore peer table snapshot peerFSAddress Peer cluster Hadoop FS address peerHBaseRootAddress Peer cluster HBase root location Args: peerid Id of the peer used for verification, must match the one given for replication tablename Name of the table to verify Examples: To verify the data replicated from TestTable for a 1 hour window with peer #5 $ hbase org.apache.hadoop.hbase.mapreduce.replication.VerifyReplication --starttime=1265875194289 --endtime=1265878794289 5 TestTable
验证结果参考:

引用:


