
HBase——冷热分离方案
前言
HBase是当下流行的一款海量数据存储的分布式数据库。往往海量数据存储会涉及到一个成本问题,如何降低成本。
常见的方案就是通过冷热分离来治理数据。冷数据可以用更高的压缩比算法(ZSTD),更低副本数算法(Erasure Coding),更便宜存储设备(HDD,高密集型存储机型)。
HBase冷热分离常见解决方案
-
1.主备集群
如果是传统开源的HBase要做冷热分离,方案只能是搞两个集群(主备),主集群是SSD的配置,负责在线查询,备(冷)集群用更廉价的硬件(HDD),负责历史查询和并行计算等等。
主集群设置TTL,这样当数据热度退去,冷数据自然只在冷集群有。这两张表之间利用Replication机制进行同步,并且客户端需要感知两个集群的配置。

优点:方案简单,现成内核版本都能搞,无需改动HBase代码;
缺点:双集群维护开销大,冷集群CPU存在浪费;
注意:1.x版本的HBase在不改内核情况下,基本只能有这种方案。
-
2. HDFS Archival Storage + HBase CF-level Storage Policy
在2.0的HBase的版本中新加入了一个特性,可以指定表的HDFS存在哪种介质上。这利用了HDFS的分级存储功能,HDFS的分级存储功能,可以将DataNode配置到不同介质的盘。
比如下图中有三块是机械盘一块SSD,在表上可以设置这样的策略,指定表的HDFS是写在冷介质还是热介质上,最后调到HDFS接口的时候,会根据设置的文件的属性放置数据。
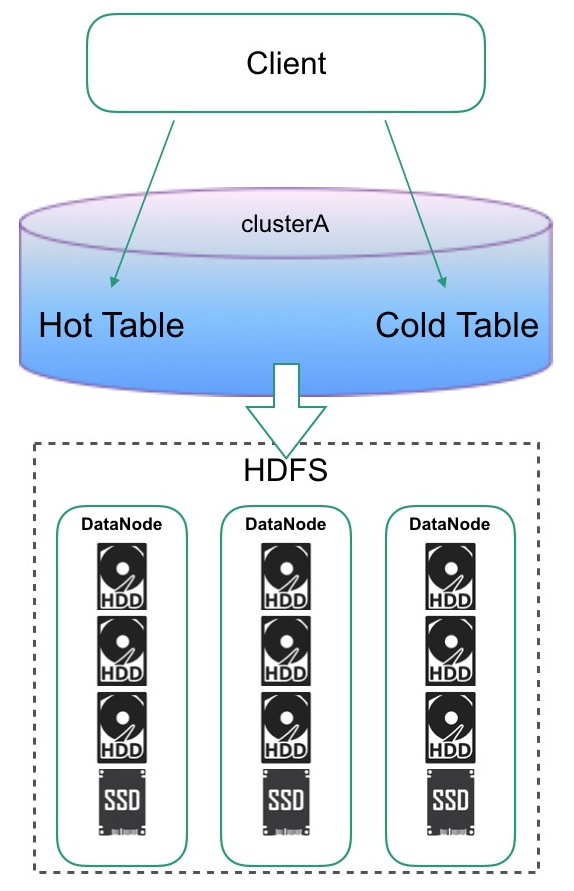
需要在2.x之后的版本才能使用。结合HDFS分层存储能力 + 在Table层面指定数据存储策略,实现同集群下,不同表数据的冷热分离。
优点:同一集群冷热分离,维护开销少,更灵活的配置不同业务表的策略
缺点:磁盘配比是个很大的问题,不同业务冷热配比是不一样的,比较难整合在一起,一旦业务变动,集群硬件配置是没法跟着变的。
-
3.云HBase冷热分离解决方案
上述2套方案都不是最好的方案,对于云上来说。第一套方案就不说了,客户搞2个集群,对于数据量不大的客户其实根本降不了成本。
第二套方案,云上客户千千万,业务各有各样,磁盘配置是很难定制到合适的状态。
云上要做 cloud native 的方案,必须满足同集群下,极致的弹性伸缩,才能真正意义上做到产品化。
云上低成本,弹性存储,只有OSS了。所以很自然的想到如下架构:
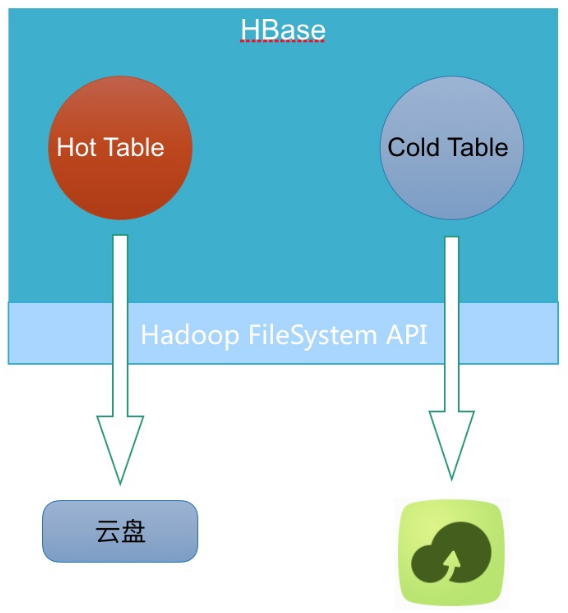
引用:


