Canal——高可用架构设计与应用
前言
本篇只介绍跟 高可用 相关的配置。
- TCP模式 请参考文章:【Canal——增量同步MySQL数据到ElasticSearch】
Canal server 和 client 端的高可用方案依赖 zookeeper, 启动 canal server 和 client 的时候都会 zookeeper 读取信息. Canal 在 zookeeper 存储的数据结构如下:
/otter └── canal └── destinations └── flight_segment # canal 实例名称 ├── 1001 # canal client 信息 │ ├── cursor # 当前消费的 mysql binlog 位点 │ ├── filter # binlog 过滤条件 │ └── running # 当前正在运行的 canal client 服务器 ├── cluster # canal server 列表 │ └── 10.93.61.86:11111 └── running # 当前正在运行的 canal server 服务器
Canal server 和 client 启动的时候都会去抢占 zk 对应的 running 节点, 保证只有一个 server 和 client 在运行, 而 server 和 client 的高可用切换也是基于监听 running 节点进行的.
一、架构
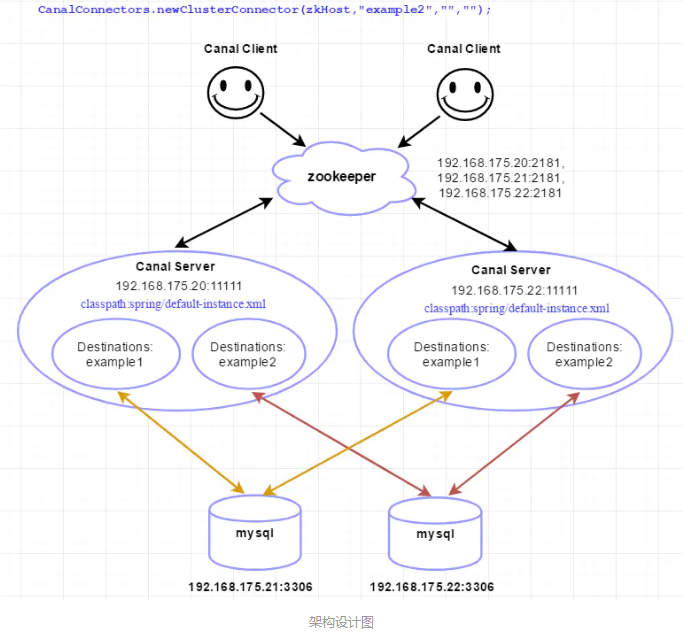
配置说明:
- zookeeper x 3 + canal x 2 + mysql x 2
组件说明:
- linux内核版本(CentOS Linux 7):(命令:uname -a)
Linux slave1 3.10.0-693.el7.x86_64 #1 SMP Tue Aug 22 21:09:27 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
- mysql版本:(SQL命令:select version(); 或 status)
Server version: 5.6.43-log MySQL Community Server (GPL)
- canal版本:canal-1.1.4
- zookeeper版本:zookeeper-3.4.14
- JDK版本: 1.8
二、搭建zookeeper集群
192.168.175.20:2181,192.168.175.21:2181,192.168.175.22:2181,具体搭建流程,可查看文章:【Zookeepr3.4.5集群搭建】。三、搭建canal server集群
前提: mysql已打开binlog功能,且配置binlog模式为row。具体配置,可查看文章:【增量同步MySQL数据到ElasticSearch】。
1. 下载最新canal安装包
下载地址: https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz
2.上传并解压
进入192.168.175.20服务器,使用rz命令上传,使用如下命令进行解压至/usr/local/hadoop/app/canal:
tar xzvf canal.deployer-1.1.4.tar.gz -C canal
3. 修改配置instance.properties
新解压的文件夹/usr/local/hadoop/app/canal/conf/有一个example文件夹,一个example就代表一个instance实例.而一个instance实例就是一个消息队列,
所以这里可以将文件名改为example1,同时再复制出来一个叫example2.(命名可以使用监听的数据库名)。
修改/usr/local/hadoop/app/canal/conf/example1/instance.properties配置文件:
canal.instance.master.address=192.168.175.21:3306 canal.instance.dbUsername=canal canal.instance.dbPassword=canal canal.instance.connectionCharset = UTF-8 canal.mq.topic=example1
修改/usr/local/hadoop/app/canal/conf/example2/instance.properties配置文件:
canal.instance.master.address=192.168.175.22:3306 canal.instance.dbUsername=canal canal.instance.dbPassword=canal canal.instance.connectionCharset = UTF-8 canal.mq.topic=example2
配置文件参数说明,可查看:https://github.com/alibaba/canal/wiki/AdminGuide
4. 修改配置canal.properties
配置/usr/local/hadoop/app/canal/conf/canal.properties是一个对应canal server的全局配置(instance.properties是对应canal instance的配置)。
canal.id = 2 #保证每个canal server的id不同 canal.port = 11111 canal.zkServers =192.168.175.20:2181,192.168.175.21:2181,192.168.175.22:2181 canal.instance.global.spring.xml = classpath:spring/default-instance.xml #其他配置默认即可.
注意: 两台机器上的instance目录的名字需要保证完全一致,HA模式是依赖于instance name进行管理,同时必须都选择default-instance.xml配置。
配置完成,将文件从192.168.175.20远程复制一份到192.168.175.22上:
#需要确保已开通免密
scp -rp /usr/local/hadoop/app/canal slave2:/usr/local/hadoop/app/
5. 启动canal server
分别进入2台服务器的文件夹/usr/local/hadoop/app/canal/bin执行如下启动命令:
./startup.sh
- 查看 server 日志:
/usr/local/hadoop/app/canal/logs/canal/canal.log,出现如下内容,即表示启动成功:
2019-06-07 21:15:03.372 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## load canal configurations 2019-06-07 21:15:03.427 [main] INFO c.a.o.c.d.monitor.remote.RemoteConfigLoaderFactory - ## load local canal configurations 2019-06-07 21:15:03.529 [main] INFO com.alibaba.otter.canal.deployer.CanalStater - ## start the canal server. 2019-06-07 21:15:06.251 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[192.168.175.22:11111] 2019-06-07 21:15:22.245 [main] INFO com.alibaba.otter.canal.deployer.CanalStater - ## the canal server is running now ......
- 查看 instance 的日志:/usr/local/hadoop/app/canal/logs/example1/example1.log 和 /usr/local/hadoop/app/canal/logs/example2/example2.log,出现如下内容,即表示启动成功:

注:只会看到一台机器上出现了以上instance启动成功的日志,即 192.168.175.20 和 192.168.175.22 只会有1台有以上日志输出。
6. 验证canal server
- 在zk中查看canal server节点注册情况:
[zk: localhost:2181(CONNECTED) 27] ls2 /otter/canal/destinations [example2, example1] [zk: localhost:2181(CONNECTED) 26] ls2 /otter/canal/cluster [192.168.175.22:11111, 192.168.175.20:11111]
可以看到canal server节点已经在zk集群上注册成功。当停掉一个canal server时,可以看到zk上对应的临时节点也会删除.
- 在zk中查看canal server当前正在工作的节点:
[zk: localhost:2181(CONNECTED) 0] get /otter/canal/destinations/example1/running {"active":true,"address":"192.168.175.20:11111"}
- canal server 自动平滑切换:
先停止正在工作的 192.168.175.20 的 canal server:
bin/stop.sh
这时 192.168.175.22 会立马启动example instance,提供新的数据服务:
[zk: localhost:2181(CONNECTED) 0] get /otter/canal/destinations/example1/running {"active":true,"address":"192.168.175.22:11111"}
与此同时,客户端也会随着canal server的切换,通过获取zookeeper中的最新地址,与新的canal server建立链接,继续消费数据,整个过程自动完成。
四、搭建canal client
使用canal client通过zookeeper连接canal server集群。注意运行canal客户端代码时,一定要先启动canal server!!!
1. 代码实现
- 添加pom依赖:
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.3</version>
</dependency>
- canal client代码:
package com.xgh.canal; import com.alibaba.otter.canal.client.CanalConnector; import com.alibaba.otter.canal.client.CanalConnectors; import com.alibaba.otter.canal.protocol.CanalEntry.*; import com.alibaba.otter.canal.protocol.Message; import java.net.InetSocketAddress; import java.util.List; public class TestCanalByZk { public static void main(String args[]) { String zkHost="192.168.175.20:2181,192.168.175.21:2181,192.168.175.22:2181"; // 创建链接 CanalConnector connector = CanalConnectors.newClusterConnector(zkHost,"example1","",""); /*CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("192.168.175.22", 11111), "example", "", "");*/ int batchSize = 1000; int emptyCount = 0; long batchId = 0; //外层死循环:在canal节点宕机后,抛出异常,等待zk对canal处理切换,切换完后,继续创建连接处理数据 while(true) { try { connector.connect(); connector.subscribe(".*\\..*");//订阅所有库下面的所有表 //connector.subscribe("canal.t_canal");//订阅库canal库下的表t_canal connector.rollback(); //内层死循环:按频率实时监听数据变化,一旦收到变化数据,立即做消费处理,并ack,考虑消费速度,可以做异步处理并ack. while (true) { Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据 batchId = message.getId(); int size = message.getEntries().size(); //// 偏移量不等于-1 或者 获取的数据条数不为0 时,认为拿到消息,并处理 if (batchId == -1 || size == 0) { emptyCount++; System.out.println("empty count : " + emptyCount);//此時代表當前數據庫無遍更數據 Thread.sleep(200); //200ms拉一次变动数据 } else { emptyCount = 0; System.out.printf("message[batchId=%s,size=%s] \n", batchId, size); printEntry(message.getEntries()); } connector.ack(batchId); // 提交确认 } }catch(Exception e){ e.printStackTrace(); connector.rollback(batchId); // 处理失败, 回滚数据 } finally { connector.disconnect(); } } } private static void printEntry(List<Entry> entrys) { for (Entry entry : entrys) { if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) { continue; } RowChange rowChage = null; try { rowChage = RowChange.parseFrom(entry.getStoreValue()); } catch (Exception e) { throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(), e); } System.out.println("rowChare ======>"+rowChage.toString()); EventType eventType = rowChage.getEventType(); //事件類型,比如insert,update,delete System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s", entry.getHeader().getLogfileName(),//mysql的my.cnf配置中的log-bin名稱 entry.getHeader().getLogfileOffset(), //偏移量 entry.getHeader().getSchemaName(),//庫名 entry.getHeader().getTableName(), //表名 eventType));//事件名 for (RowData rowData : rowChage.getRowDatasList()) { if (eventType == EventType.DELETE) { printColumn(rowData.getBeforeColumnsList()); } else if (eventType == EventType.INSERT) { printColumn(rowData.getAfterColumnsList()); } else { System.out.println("-------> before"); printColumn(rowData.getBeforeColumnsList()); System.out.println("-------> after"); printColumn(rowData.getAfterColumnsList()); } } } } private static void printColumn(List<Column> columns) { for (Column column : columns) { System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated()); } } }
canal功能含义:
- 连接,connector.connect() - 订阅,connector.subscribe - 获取数据,connector.getWithoutAck() - 业务处理 - 提交确认,connector.ack() - 回滚,connector.rollback() - 断开连接,connector.disconnect()
canal client运行实例:
empty count : 1 empty count : 2 empty count : 3 empty count : 4
2. 验证canal client
- 触发数据库变更:
创建库:create database canal;
创建表:create table t_canal (id int,name varchar(20),status int);
插入数据:insert into t_canal values(11,'xxiao',1);
canal client 输出日志:
================> binlog[mysql-bin.000001:6973] , name[canal,t_canal] , eventType : INSERT id : 11 update=true name : xxiao update=true status : 1 update=true
- 在zk中查看正在连接的 canal client 节点:
[zk: localhost:2181(CONNECTED) 0] get /otter/canal/destinations/example1/1001/running
{"active":true,"address":"192.168.175.18:11111","clientId":1001}
- 在zk中查看最后一次消费成功的binlog位点:
数据消费成功后,canal server会在zookeeper中记录下当前最后一次消费成功的binlog位点. (下次你重启client时,会从这最后一个位点继续进行消费)。
[zk: localhost:2181(CONNECTED) 16] get /otter/canal/destinations/example1/1001/cursor {"@type":"com.alibaba.otter.canal.protocol.position.LogPosition","identity":{"slaveId":-1,"sourceAddress":{"address":"10.20.144.15","port":3306}},"postion":{"included":false,"journalName":"mysql-bin.002253","position":2574756,"timestamp":1363688722000}}
五、其它
1. canal数据结构
canal的数据传输有两块,一块是进行binlog订阅时,binlog转换为我们所定义的Message,第二块是client与server进行TCP交互时,传输的TCP协议。
Entry数据结构:
Entry Header version [协议的版本号,default = 1] logfileName [binlog文件名] logfileOffset [binlog position] serverId [服务端serverId] serverenCode [变更数据的编码] executeTime [变更数据的执行时间] sourceType [变更数据的来源,default = MYSQL] schemaName [变更数据的schemaname] tableName [变更数据的tablename] eventLength [每个event的长度] eventType [insert/update/delete类型,default = UPDATE] props [预留扩展] gtid [当前事务的gitd] entryType [事务头BEGIN/事务尾END/数据ROWDATA/HEARTBEAT/GTIDLOG] storeValue [byte数据,可展开,对应的类型为RowChange] RowChange tableId [tableId,由数据库产生] eventType [数据变更类型,default = UPDATE] isDdl [标识是否是ddl语句,比如create table/drop table] sql [ddl/query的sql语句] rowDatas [具体insert/update/delete的变更数据,可为多条,1个binlog event事件可对应多条变更,比如批处理] beforeColumns [字段信息,增量数据(修改前,删除前),Column类型的数组] afterColumns [字段信息,增量数据(修改后,新增后),Column类型的数组] props [预留扩展] props [预留扩展] ddlSchemaName [ddl/query的schemaName,会存在跨库ddl,需要保留执行ddl的当前schemaName] Column index [字段下标] sqlType [jdbc type] name [字段名称(忽略大小写),在mysql中是没有的] isKey [是否为主键] updated [是否发生过变更] isNull [值是否为null] props [预留扩展] value [字段值,timestamp,Datetime是一个时间格式的文本] length [对应数据对象原始长度] mysqlType [字段mysql类型]
六、总结
1. 启动两个监听example1的canal client,启动两个监听example2的canal client:
在example1或example2对应的数据发生变化时,两个canal client只有一个消费消息。
当两个监听同一个队列的canal client有一个宕掉时,再有数据变化时,剩下的一个canal client就会开始消费数据。
这就验证了canal client的HA机制:为了保证有序性,一份instance同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序.
2. 启动两个canal server并在zk上注册
当停掉其中一个canal server时,当产生数据变化时,整个canal server集群仍可以正常对外提供服务。
这就验证了canal server的HA机制:为了减少对mysql dump的请求,不同server上的instance要求同一时间只能有一个处于running,其他的处于standby状态.
3. 在canal server切换过程中,canal client存在重复消费数据的问题
这点需要在消费端自行进行处理。
参考:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号