

HBase——系统调优
JVM层
HMaster 没有处理过重的负载,并且实际的数据服务不经过 HMaster,它的主要任务有2个:一、管理Hbase Table的 DDL操作, 二、region的分配工作,任务不是很艰巨。
但是如果采用默认自动split region的方式,HMaster会稍微忙一些,负载不大,可适度对此进程做适量放大heap 的操作,但不可太大。
RegionServer 在写入数据时,数据会先保存在memstore 中,当大于阈值时候,再写入到磁盘。因为写入的数据是由客户端在不同时间写入的,故而他们占据的Java堆空间很可能是不连续的,会出现孔洞,所以需要调整垃圾回收机制。
RegionServer的新生代大小在128M~512M,老生代大小在几GB。最初写入的数据会保存在新生代,再刷写到磁盘;当数据刷写到磁盘的速度较慢时候,新生代中的数据停留时间过长,会被移到老生代。
新生代空间可以被迅速回收,对内存管理没有影响;老生代数据量大,回收慢,对内存管理影响大。所以二者需要不同的垃圾回收策略。
-
Master和RegionServer统一配置
进入conf目录,修改hbase-env.sh文件的HBASE_OPTS属性值:
export HBASE_OPTS="$HBASE_OPTS -Xmx3g -Xms3g -Xmn512m -Xss256k -XX:MaxPermSize=256m -XX:SurvivorRatio=2 -XX:MaxTenuringThreshold=15 -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+UseCMSInitiatingOccupancyOnly -XX:-DisableExplicitGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintTenuringDistribution -Xloggc:$HBASE_HOME/logs/gc-$(hostname)-hbase.log"
- Master和RegionServer单独配置
进入conf目录,修改hbase-env.sh文件的以下属性值:
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS $HBASE_JMX_BASE -Xmx2g -Xms2g -Xmn750m -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70" export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS $HBASE_JMX_BASE -Xmx20g -Xms20g -Xmn1g -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly"
-
配置解读
-Xmx3g 最大堆内存3g
-Xms3g 初始堆内存设置与最大堆内存一样大。如果Xms设置得比较小,当遇到数据量较大时候,堆内存会迅速增长,当上升到最大又会回落,伸缩堆大小会带来压力。
-Xmn512M 新生代512M。新生代不能过小,否则新生代中的生存周期较长的数据会过早移到老生代,引起老生代产生大量内存碎片;新生代也不能过大,否则回收新生代也会造成太长的时间停顿,影响性能。
-XX:CMSInitiatingOccupancyFraction=75 初始占用比为75%的时候开始CMS回收。此值不能太小,否则CMS发生得太频繁。此值不能太大,否则因为CMS需要额外堆内存,会发生堆内存空间不足,导致CMS 失败。
-Xloggc:$HBASE_HOME/logs/gc-$(hostname)-hbase.log 写入日志
-XX:+UseParNewGC 新生代采用 ParallelGC 回收器。ParallelGC 将停止运行Java 进程去清空新生代堆,因为新生代很小,所以停顿的时间也很短,需几百毫秒。
-XX:+UseConMarkSweepGC
老年代采用CMS回收器(Concurrent Mark-Sweep Collector) . CMS 在不停止运行Java进程的情况下异步地完成垃圾回收,CMS会增加CPU的负载,但是可以避免重写老年代堆碎片时候的停顿。
老年代回收不可使用 ParallelGC 回收机制,因为老生代的堆空间大,ParallelGC会造成Java进程长时间停顿,使得RegionServer与ZooKeeper的会话超时,该RegionServer会被误认为已经奔溃并会被抛弃。
对于老年代来说, 它可以更早的开始回收。当分配在老年代的空间比率超过了一个阀值,CMS 开始运行。如果 CMS 开始的太晚,HBase 或许会直接进行 full garbage collection。这种情况会导致block所有的线程,
如果这个时间过长,就会导致hbase连接超时,结果就是regionserver集体下线。这是不能容忍额。为了避免这种情况的发生,
我们建议设置 -XX:CMSInitiatingOccupancyFraction JVM 参数来精确指定在多少百分比 CMS 应该被开始,正如上面的配置中做的那样。在 百分之 60 或 70 开始是一个好的实践。
当老年代使用 CMS,默认的年轻代 GC 将被设置成 Parallel New Collector。再来看看hbase为什么可能进行full gc,如果我们不配置-XX:CMSInitiatingOccupancyFraction,jdk1.5以后会使用默认值90%,
那么很可能,当老年代内存占用超过分配给他的内存大小的90%,会进行CMS(老年代的回收),但是不会阻止年轻代到老年代的迁移,如果迁移过快,CMS较慢,会出现老年代内存使用率100%,这时会导致full gc。
如果我们把这个参数调整小一点,那么能给年轻带到老年代迁移的同时做CMS时一些时间,也就减少了full gc的发生。当然这可能会频繁的gc,但总比整个hbase挂掉的好不是么?
操作系统层
- vm.swappiness
设置方法:
echo 1 > /proc/sys/vm/swappiness,或sysctl -w vm.swappiness=1,或- 编辑/etc/sysctl.conf文件,加入
vm.swappiness=1
swap即交换空间,作用类似于Windows中的虚拟内存,也就是当物理内存不足时,将硬盘上的swap分区当做内存来使用。但是,由于磁盘的读写速率与内存相比差太多,一旦发生大量交换,
系统延迟就会增加,甚至会造成服务长期不可用,这对于大数据集群而言是致命的。vm.swappiness参数用于控制内核对交换空间的使用积极性,默认是60。值越高,就代表内核越多地使用交换空间。
对于内存较大的CDH集群,我们一般将这个值设为0或1。0表示只有当可用物理内存小于最小阈值vm.min_free_kbytes(后面会提到)时才使用交换空间,1则表示最低限度地使用交换空间。
关于这个配置的具体机制,找到了两种解释:
- 当物理内存占用率高于(100 - vm.swappiness)%时,开始使用交换分区。
- vm.swappiness通过控制内存回收时,回收的匿名内存更多一些还是回收的文件缓存更多一些来达到这个效果。如果等于100,表示匿名内存和文件缓存将用同样的优先级进行回收,默认60表示文件缓存会优先被回收掉。
- vm.min_free_kbytes
设置方法:
echo 4194304 > /proc/sys/vm/min_free_kbytes,或sysctl -w vm.min_free_kbytes=4194304,或- 编辑/etc/sysctl.conf文件,加入
vm.min_free_kbytes=4194304
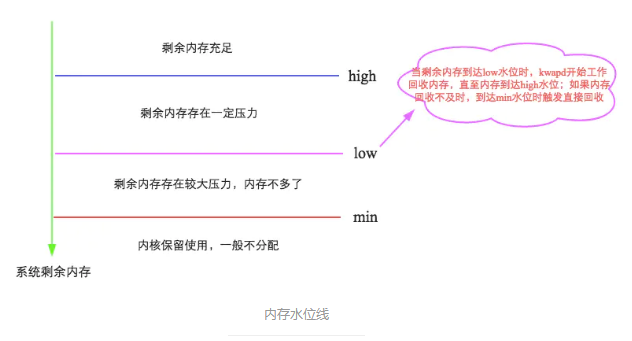
Linux系统中,剩余内存有3个水位线,从高到低记为high、low和min。并且有如下的关系:min = vm.min_free_kbytes,low = min * 5 / 4,high = min * 3 / 2。
当剩余内存低于high值时,系统会认为内存有一定的压力。当剩余内存低于low值时,守护进程kswapd就会开始进行内存回收。
当其进一步降低到min值时,就会触发系统的直接回收(direct reclaim),此时会阻塞程序的运行,使延迟变大。因此vm.min_free_kbytes的值既不应过小,也不应过大。如果过小(比如只有几十M),low与min之间的差值就会非常小,极易触发直接回收,使效率降低。
而如果设置得过大,又会造成内存资源的浪费,kswapd回收时也会耗费更多的时间。
上面的语句中设置成了4G,视物理内存大小,一般设在1G~8G之间。
- 透明大页面(THP)
设置方法:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
大页面(Huge Page)是内存分页管理的一种实现方式。计算机内存是通过表映射(页表)的方式进行内存寻址,目前系统内存以4KB为一个页,作为内存寻址的最小单元。随着内存不断增大,页表的大小将会不断增大。
一台256G内存的机器,如果使用4KB小页,仅页表大小就要4G左右。页表是必须装在内存的,而且是在CPU内存,太大就会发生大量miss,内存寻址性能就会下降。
Huge Page就是为了解决这个问题,它使用2MB的大页代替传统小页来管理内存,这样页表大小就可以控制的很小,进而全部装在CPU内存,防止出现miss。
它有两种实现方式,一是静态大页面(Static Huge Pages,SHP),二是透明大页面(Transparent Huge Pages,THP)。从它们的名字就可以看出,SHP是静态的,而THP是动态的。
由于THP是在运行期做分配和管理,因此会有一定程度的延迟,对于内存密集型的应用十分不利,必须关闭它。
-
vm.zone_reclaim_mode
设置方法:
-
echo 0 > /proc/sys/vm/zone_reclaim_mode,或 -
sysctl -w vm.zone_reclaim_mode=0,或 -
编辑/etc/sysctl.conf文件,加入
vm.zone_reclaim_mode=0
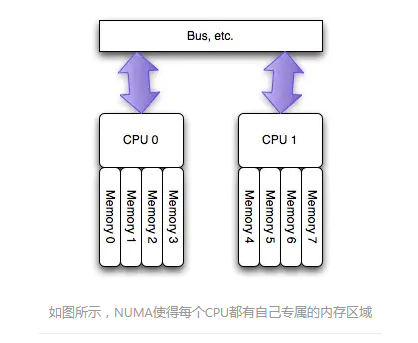
只有当CPU访问自身直接attach内存对应的物理地址时,才会有较短的响应时间(Local Access)。而如果需要访问其他CPU attach的内存的数据时,
就需要通过inter-connect通道访问,响应时间就相比之前变慢了(Remote Access)。
NUMA这种特性可能会导致CPU内存使用不均衡,部分CPU的local内存不够使用,频繁需要回收,进而可能发生大量swap,系统响应延迟会严重抖动。
而与此同时其他部分CPU的local内存可能都很空闲。这就会产生一种怪现象:使用free命令查看当前系统还有部分空闲物理内存,系统却不断发生swap,导致某些应用性能急剧下降。
因此必须改进NUMA的内存回收策略,即vm.zone_reclaim_mode。这个参数可以取值0/1/3/4:
0 表示在local内存不够用的情况下可以去其他的内存区域分配内存;
1 表示在local内存不够用的情况下本地先回收再分配;
3 表示本地回收尽可能先回收文件缓存对象;
4 表示本地回收优先使用swap回收匿名内存。
由此可见,将其设为0可以降低swap发生的概率。
HDFS
HDFS 作为HBase最终数据存储系统,通常会使用三副本策略存储HBase数据文件以及日志文件。从HDFS的角度看,HBase是它的客户端。
实际实现中,HBase服务通过调用HDFS的客户端对数据进行读写操作,因此对HDFS客户端的相关优化也会影响HBase的读写性能。这里主要关注以下三个方面。
- Short-Circuit Local Read
当前HDFS读取数据都需要经过DataNode,客户端会向DataNode发送读取数据的请求,DataNode接收到请求后从磁盘中将数据读出来,再通过TCP发送给客户端。
对于本地数据,Short Circuit Local Read 策略允许客户端绕过DataNode直接从磁盘上读取本地数据,因为不需要经过DataNode而减少了多次网络传输开销,因此数据读取的效率会更高。
设置方法:在 {hbaseDir}/conf/hbase-site.xml 中,增加以下参数:
# 省略其他配置 <property> <name>dfs.client.read.shortcircuit</name> <value>true</value> </property> <property> <name>dfs.client.read.shortcircuit.buffer.size</name> <value>131072</value> <!-- 默认是1M,有可能会造成OOM,所以改成128M --> </property>
-
Hedged Read
HBase数据在HDFS中默认存储三个副本,通常情况下HBase会根据一定算法优先选择一个DataNode进行数据读取。然而在某些情况下,有可能因为磁盘或者网络问题等引起读取超时,
根据Hedged Read策略,如果在指定时间内读取请求没有返回,HDFS客户端将会向第二个副本发送第二次数据请求,并且谁先返回就使用谁,之后返回的将会被丢弃。
设置方法:在 {hbaseDir}/conf/hbase-site.xml 中,增加以下参数:
<property>
<name>dfs.client.hedged.read.threadpool.size</name>
<value>20</value> <!-- hedged read 线程池数量 -->
</property>
<property>
<name>dfs.client.hedged.read.threshold.millis</name>
<value>10</value> <!-- 读取超时时间,超过这个阈值,将会再发起一次读取请求,单位为 milliseconds -->
</property>
- Region Data Locality
Region Data Locality,即数据本地率,表示当前Region在数据在Region所在节点存储的比例。
举个例子,HDFS数据通常存储三份,假如当前RegionA处于Node1上,数据a写入的时候三副本为(Node1,Node2,Node3),数据b写入三副本是(Node1,Node4,Node5),
数据c写入三副本(Node1,Node3,Node5),可以看出来所有数据写入本地Node1肯定会写一份,数据都在本地可以读到,因此数据本地率是100%。
现在假设RegionA被迁移到了Node2上,只有数据a在该节点上,其他数据(b和c)读取只能远程跨节点读,本地率就为33%(假设a,b和c的数据大小相同)。
优化原理:
数据本地率太低很显然会产生大量的跨网络IO请求,必然会导致读请求延迟较高,因此提高数据本地率可以有效优化随机读性能。
数据本地率低的原因一般是因为Region迁移(自动balance开启、RegionServer宕机迁移、手动迁移等),因此一方面可以通过避免Region无故迁移来保持数据本地率,
另一方面如果数据本地率很低,也可以通过执行major_compact提升数据本地率到100%。
优化建议:
避免Region无故迁移,比如关闭自动balance、RS宕机及时拉起并迁回飘走的Region等;在业务低峰期执行major_compact提升数据本地率。
引用:

