

Kafka——指定位移消费(回溯消费)
前言
消费者在消费消息时会根据之前提交的消费位移offset去kafka拉取offset之后的消息进行消费。但是一些情况下消费者开始消费时会没有消费位移:
- 一个新的消费组建立的时候;
- 消费组内的一个新的消费者订阅了一个新的主题;
- __consumer_offsets主题中关于这个消费组的位移信息已经过期而被删除的时候;
这时消费者开始消费的消费位移就由客户端参数 auto.offset.reset 来决定,各值的含义如下:
- earliest:当各分区下存在已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,从头开始消费;
- latest:当各分区下存在已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,消费该分区下新产生的数据(默认值);
- none:当各分区都存在已提交的 offset 时,从 offset 后开始消费;只要有一个分区不存在已提交的offset,则直接抛出NoOffsetForPartitionException异常;
Kafka 提供的 auto.offset.reset 参数也只能在找不到消费位移或位移越界的情况下粗粒度地从开头或末尾开始消费。
有的时候,我们需要一种更细粒度的掌控,可以让我们从指定的位移处开始拉取消息,可通过以下两种方式来实现。
一、消费者API
消费者可以通过 seek() 方法手动重设位移,让我们得以追前消费或回溯消费:
public void seek(TopicPartition partition, long offset)
seek() 方法中的参数 partition 表示分区,而 offset 参数用来指定从分区的哪个位置开始消费。
seek() 方法只能重置消费者分配到的分区的消费位置,而分区的分配是在 poll() 方法的调用过程中实现的,也就是说,在执行 seek() 方法之前需要先执行一次 poll() 方法,等到分配到分区之后才可以重置消费位置。
poll方法带有Duration参数,可能会存在到达指定时间后,poll()方法直接返回,内部的分区分配逻辑还未实施,那么此时获取到的consumer.assignment()就是一个空集合,
所以调用时需注意进行循环判断调用poll获取订阅的分区后再去调用seek方法重置位移:
Set<TopicPartition> assignment = new HashSet<>(); // 在poll()方法内部执行分区分配逻辑,该循环确保分区已被分配。 // 当分区消息为0时进入此循环,如果不为0,则说明已经成功分配到了分区。 while (assignment.size() == 0) { consumer.poll(100); // assignment()方法是用来获取消费者所分配到的分区消息的 // assignment的值为:topic-demo-3, topic-demo-0, topic-demo-2, topic-demo-1 assignment = consumer.assignment(); }
消费者内的seek位移的方法有如下几种:
//将指定分区partition的位移offset重置到offset void seek(TopicPartition partition, long offset); //将指定分区partition的位移offset重置到offset,并带有一些自定义的字符串元数据信息metadata void seek(TopicPartition partition, OffsetAndMetadata offsetAndMetadata); //将多个分区partitions消费位移offset重置到分区开头 void seekToBeginning(Collection<TopicPartition> partitions); //将多个分区partitions消费位移offset重置到分区末尾 void seekToEnd(Collection<TopicPartition> partitions);
消费者内获取位移的方法有如下几种:
//获取多个分区的分区开始位移 Map<TopicPartition, Long> beginningOffsets(Collection<TopicPartition> partitions); //在指定时间内获取多个分区的分区开始位移 Map<TopicPartition, Long> beginningOffsets(Collection<TopicPartition> partitions, Duration timeout); //获取多个分区的分区末尾位移 Map<TopicPartition, Long> endOffsets(Collection<TopicPartition> partitions); //在指定时间内获取多个分区的分区末尾位移 Map<TopicPartition, Long> endOffsets(Collection<TopicPartition> partitions, Duration timeout); //根据时间戳获取指定时间戳之后的消息位移 Map<TopicPartition, OffsetAndTimestamp> offsetsForTimes(Map<TopicPartition, Long> timestampsToSearch); //指定时间内根据时间戳获取指定时间戳之后的消息位移 Map<TopicPartition, OffsetAndTimestamp> offsetsForTimes(Map<TopicPartition, Long> timestampsToSearch, Duration timeout);
通过以上方法就可以根据时间获取位移或者获取分区开始或结束的位移,并通过seek方法实现自定义位移消费。
-
指定offset开始消费
接下来的代码示例讲述了消费各分区 offset 为 80(包括80)之后的消息:
Properties props = initConfig(); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList(TOPIC)); Set<TopicPartition> assignment = new HashSet<>(); // 在poll()方法内部执行分区分配逻辑,该循环确保分区已被分配。 // 当分区消息为0时进入此循环,如果不为0,则说明已经成功分配到了分区。 while (assignment.size() == 0) { consumer.poll(100); // assignment()方法是用来获取消费者所分配到的分区消息的 // assignment的值为:topic-demo-3, topic-demo-0, topic-demo-2, topic-demo-1 assignment = consumer.assignment(); } System.out.println(assignment); for (TopicPartition tp : assignment) { int offset = 80; System.out.println("分区 " + tp + " 从 " + offset + " 开始消费"); consumer.seek(tp, offset); } while (true) { ConsumerRecords<String, String> records = consumer.poll(1000); // 消费记录 for (ConsumerRecord<String, String> record : records) { System.out.println(record.offset() + ":" + record.value() + ":" + record.partition()); } }
注意:假如某分区的前 100 条数据由于过期,导致被删除,那么此时如果使用 seek() 方法指定 offset 为 0 进行消费的话,是消费不到数据的。因为前 100 条数据已被删除,所以只能从 offset 为 100 ,来进行消费。
-
从分区开头或末尾开始消费
如果消费者组内的消费者在启动的时候能够找到消费位移,除非发生位移越界,否则 auto.offset.reset 参数不会奏效。此时如果想指定从开头或末尾开始消费,也需要 seek() 方法来实现。
如果按照指定位移消费的话,就需要先获取每个分区的开头或末尾的 offset 了。可以使用 beginningOffsets() 和 endOffsets() 方法。
Set<TopicPartition> assignment = new HashSet<>(); // 在poll()方法内部执行分区分配逻辑,该循环确保分区已被分配。 // 当分区消息为0时进入此循环,如果不为0,则说明已经成功分配到了分区。 while (assignment.size() == 0) { consumer.poll(100); // assignment()方法是用来获取消费者所分配到的分区消息的 // assignment的值为:topic-demo-3, topic-demo-0, topic-demo-2, topic-demo-1 assignment = consumer.assignment(); } // 指定分区从头消费 Map<TopicPartition, Long> beginOffsets = consumer.beginningOffsets(assignment); for (TopicPartition tp : assignment) { Long offset = beginOffsets.get(tp); System.out.println("分区 " + tp + " 从 " + offset + " 开始消费"); consumer.seek(tp, offset); } // 指定分区从末尾消费 Map<TopicPartition, Long> endOffsets = consumer.endOffsets(assignment); for (TopicPartition tp : assignment) { Long offset = endOffsets.get(tp); System.out.println("分区 " + tp + " 从 " + offset + " 开始消费"); consumer.seek(tp, offset); } // 再次执行poll()方法,消费拉取到的数据。 // ...(省略)
其实,KafkaConsumer 中直接提供了 seekToBeginning() 和 seekToEnd() 方法来实现上述功能。具体定义如下:
例如使用:
consumer.seekToBeginning(assignment);
直接可以代替:
Map<TopicPartition, Long> beginOffsets = consumer.beginningOffsets(assignment); for (TopicPartition tp : assignment) { Long offset = beginOffsets.get(tp); System.out.println("分区 " + tp + " 从 " + offset + " 开始消费"); consumer.seek(tp, offset); }
值得一说的是:
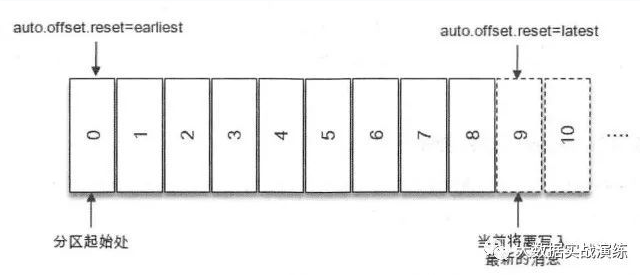
- 指定分区从头消费时,需要了解:一个分区的起始位置是 0 ,但并不代表每时每刻都为 0 ,因为日志清理的动作会清理旧的数据,所以分区的起始位置会自然而然地增加。
- 指定分区从末尾消费,需要了解:endOffsets() 方法获取的是将要写入最新消息的位置。如下图中 9 的位置:
-
根据时间戳消费
有时候我并不知道特定的消费位置,却知道一个相关的时间点。比如我想要消费某个时间点之后的消息,这个需求更符合正常的思维逻辑。
这时,我们可以用 offsetsForTimes() 方法,来获得符合筛选条件的 offset ,然后再结合 seek() 方法来消费指定数据。offsetsForTimes() 方法如下所示:
public Map<TopicPartition, OffsetAndTimestamp> offsetsForTimes(Map<TopicPartition, Long> timestampsToSearch)
offsetsForTimes() 方法的参数 timestampsToSearch 是一个 Map 类型,其中 key 为待查询的分区,value 为待查询的时间戳,该方法会返回时间戳大于等于查询时间的第一条消息对应的 offset 和 timestamp 。
接下来就以消费当前时间前一天之后的消息为例,代码片段如下所示:
Set<TopicPartition> assignment = new HashSet<>(); // 在poll()方法内部执行分区分配逻辑,该循环确保分区已被分配。 // 当分区消息为0时进入此循环,如果不为0,则说明已经成功分配到了分区。 while (assignment.size() == 0) { consumer.poll(100); // assignment()方法是用来获取消费者所分配到的分区消息的 // assignment的值为:topic-demo-3, topic-demo-0, topic-demo-2, topic-demo-1 assignment = consumer.assignment(); } Map<TopicPartition, Long> timestampToSearch = new HashMap<>(); for (TopicPartition tp : assignment) { // 设置查询分区时间戳的条件:获取当前时间前一天之后的消息 timestampToSearch.put(tp, System.currentTimeMillis() - 24 * 3600 * 1000); } // timestampToSearch的值为{topic-demo-0=1563709541899, topic-demo-2=1563709541899, topic-demo-1=1563709541899} Map<TopicPartition, OffsetAndTimestamp> offsets = consumer.offsetsForTimes(timestampToSearch); for(TopicPartition tp: assignment){ // 获取该分区的offset以及timestamp OffsetAndTimestamp offsetAndTimestamp = offsets.get(tp); // 如果offsetAndTimestamp不为null,则证明当前分区有符合时间戳条件的消息 if (offsetAndTimestamp != null) { consumer.seek(tp, offsetAndTimestamp.offset()); } } while (true) { ConsumerRecords<String, String> records = consumer.poll(1000); System.out.println("##############################"); System.out.println(records.count()); // 消费记录 for (ConsumerRecord<String, String> record : records) { System.out.println(record.offset() + ":" + record.value() + ":" + record.partition() + ":" + record.timestamp()); } }
二、命令行工具
kafka 0.11.0.0版本丰富了kafka-consumer-groups脚本的功能,用户可以直接使用该脚本很方便地为已有的consumer group重新设置位移。
前提必须consumer group必须是inactive的,即不能是处于正在工作中的状态(即要停止正在消费它的程序或应用)。否则会出现以下报错:

上图是:logstash组件还在消费组(logstash)的数据,所以失败,把logstash进程关掉就好了。
1、先查看消费进度:
bin/kafka-consumer-groups.sh --bootstrap-server 172.16.10.91:9092,172.16.10.92:9092,172.16.10.93:9092 --describe --group logstash

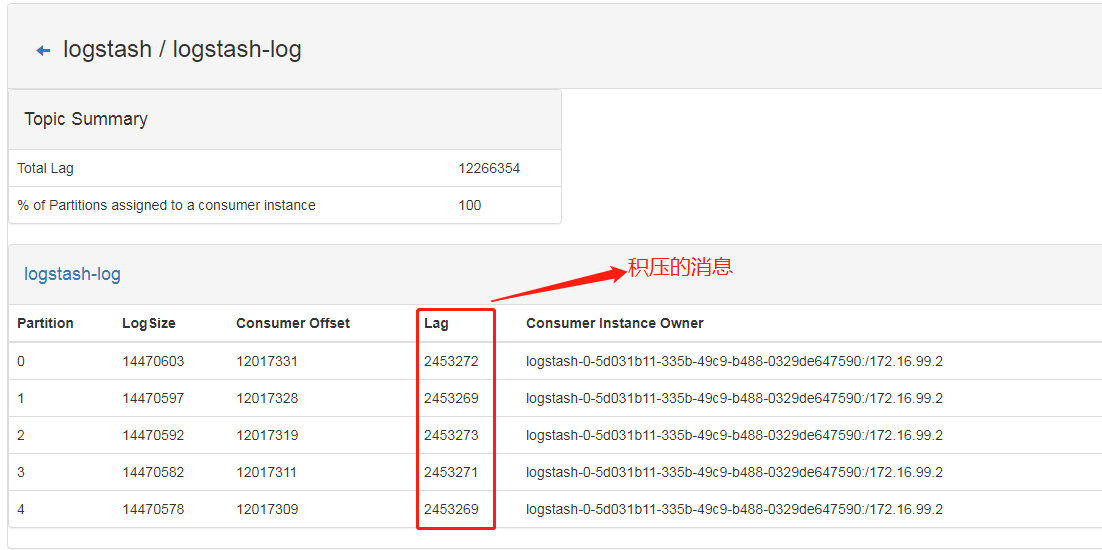
注:LAG列为未消费的记录,如果有很多,说明消费延迟很严重。
2、重设消费位移:
1、重设消费位移前积压消息:
2、执行命令:
bin/kafka-consumer-groups.sh --bootstrap-server 172.16.10.91:9092,172.16.10.92:9092,172.16.10.93:9092 --group logstash --reset-offsets --topic logstash-log --to-latest --execute

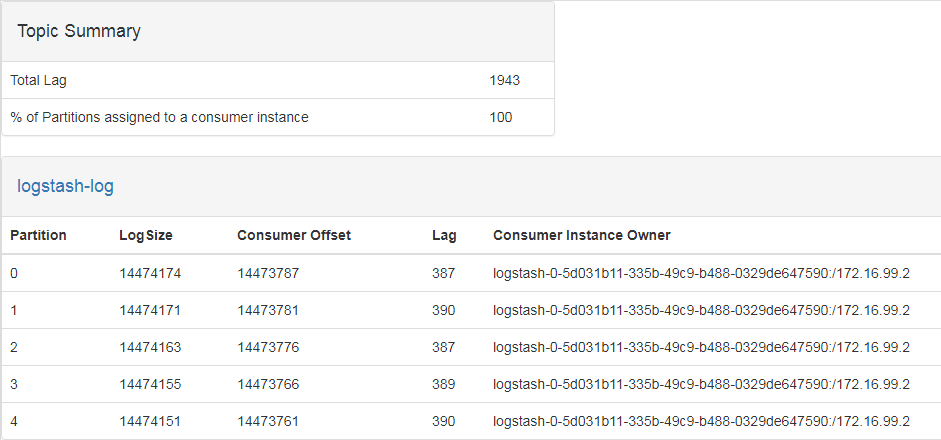
注:出现以上描述,则说明重设成功。
3、重设消费位移后积压消息:
3、参数说明:
-
确定topic作用域——当前有3种作用域指定方式:--all-topics(为consumer group下所有topic的所有分区调整位移),--topic t1 --topic t2(为指定的若干个topic的所有分区调整位移),--topic t1:0,1,2(为指定的topic分区调整位移)
-
确定位移重设策略——当前支持8种设置规则:
-
--to-earliest:把位移调整到当前最早位移处
-
--to-latest:把位移调整到当前最新位移处
-
--to-current:把位移调整到分区当前最新提交位移处
-
--to-offset <offset>: 把位移调整到指定位移处
-
--shift-by N: 把位移调整到当前位移 + N处,注意N可以是负数,表示向前移动
-
--to-datetime <datetime>:把位移调整到大于给定时间的最早位移处,datetime格式是yyyy-MM-ddTHH:mm:ss.xxx,比如2017-08-04T00:00:00.000
-
--by-duration <duration>:把位移调整到距离当前时间指定间隔的位移处,duration格式是PnDTnHnMnS,比如PT0H5M0S
-
--from-file <file>:从CSV文件中读取调整策略
-
确定执行方案——当前支持3种方案:
-
什么参数都不加:只是打印出位移调整方案,不具体执行
-
--execute:执行真正的位移调整
-
--export:把位移调整方案按照CSV格式打印,方便用户成csv文件,供后续直接使用
三、再均衡监听器
再均衡指的是发生以下情况之一而造成的分区消息重新分配的情况:
- 消费者上下线消费组内的消费者数量发生了变化
- 消费者订阅的主题发生了变化
- 主题对应的分区变化
若在再均衡过程中采用了kafka的自动提交机制就可能造成再均衡前的消费者消费状态丢失的问题。比如消费者拉取并处理了一部分消息,还未来得及提交消费位移,但再均衡之后会将这个分区分配给别的消费者,
就会造成已经消费的消息再次被拉取消费。这种情况也可以通过将已经处理的消息的offset暂存在程序中,在再均衡之后通过seek方法重置到之前已经处理的offset来避免。
再均衡使用seek的这一步就涉及之前讲到的再均衡监听器ConsumerRebalanceListener:
public interface ConsumerRebalanceListener { void onPartitionsRevoked(Collection<TopicPartition> partitions); void onPartitionsAssigned(Collection<TopicPartition> partitions); }
ConsumerRebalanceListener中有两个方法:
- onPartitionsRevoked:是在再均衡开始前、消费者停止读取消息之后调用,可以在此处暂存分区的消费位移或者调用commitSync同步提交消费位移。
- onPartitionsAssigned:在重新分配分区之后、消费者开始读取消息前调用,可以在此处seek方法重置消费位移到之前暂存的位移处,如此便能避免重复消费的问题。
引用:


