jvm | 基于栈的解释器执行过程
一段简单的算术代码:
1 public class Demo {
2 public static void main(String[] args) {
3 int a = 1;
4 int b = 2;
5 int c = (a + b) * 5;
6 }
7 }
通过javac编译,得到Demo.class。通过javap可以看到main()方法的字节码是:
Code:
stack=2, locals=4, args_size=1
0: iconst_1
1: istore_1
2: iconst_2
3: istore_2
4: iload_1
5: iload_2
6: iadd
7: iconst_5
8: imul
9: istore_3
10: return
javap提示这段代码需要深度为2的操作数栈和4个Slot(下图有误,下标为0的应该是this)的局部变量空间
下面是解释器的执行过程:
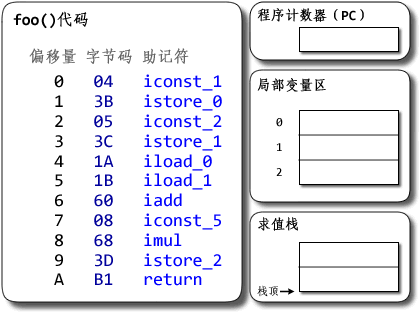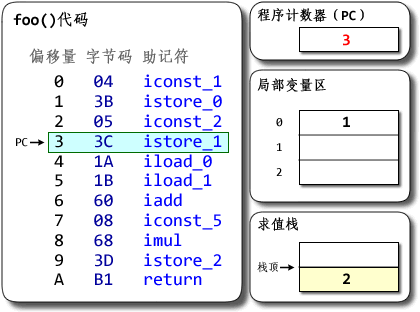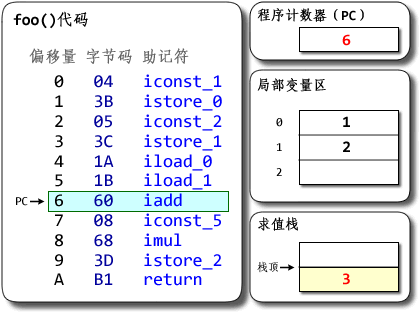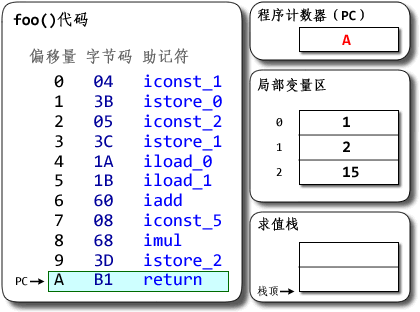
首先执行偏移地址为0的指令,iconst_1指令的作用是将int型1推送至操作数栈顶,
然后执行偏移地址为1的指令,istore_1指令的作用是将栈顶int型数值存入第二个本地(局部)变量(上图有误,第一个本地变量应是this)
。。。
然后执行偏移地址为4的指令,iload_1的作用是将第二个int型本地变量推送至栈顶
。。。
然后执行偏移量为6的指令,iadd的作用是将栈顶两int型数值相加并将结果压入栈顶
。。。
然后imul指令同理
然后return,程序结束。。。
然而jvm实际的运作过程真是这样吗?答案是并不是这样,因为上面的执行过程仅仅是一种概念模型,
实际情况会和上面描述的概念模型差距非常大,这种差距产生的原因是虚拟机中解析器和即时编译器都会对字节码进行优化
当然优化的手段是花样繁多的。。。
不过,我们能通过上面的运行过程看出栈结构指令集的一般运行过程,这就够了。。。
详情请看:java虚拟机字节码指令表

