做题记录
用来记录在做题时遇到的一些有意思/看了题解才做出来的题。
Reachability from the Capital
首先,如果一个点本来就可以被 点到达,那么可以直接在图中删去。
考虑剩下的点。
我们对每个点求出其能到达那些点,然后按能到达的点的数量从大到小排序,再依次删去这些点(每次删完要把这个点能到达的点删去,因为其已经和 联通),统计答案。
删去一个点不用真的把它干掉,打个标记即可。
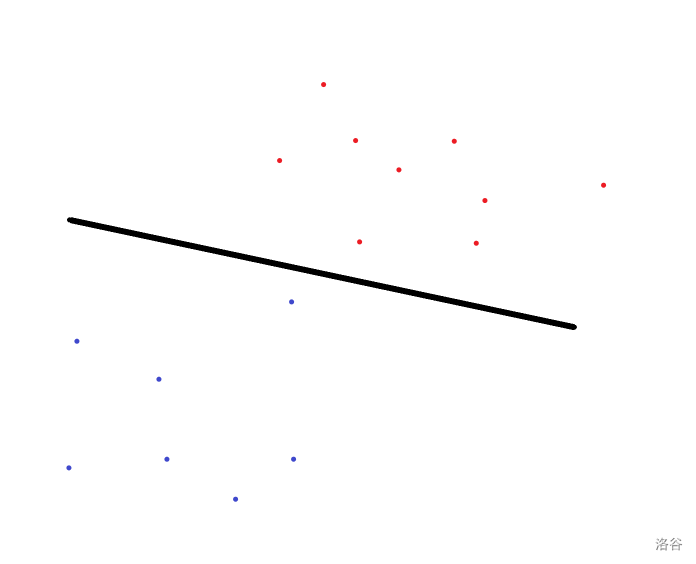
Tree with Small Distances
又是一道不会做的图(树)上问题,看来找时间得补补。
考虑贪心的去选择一个点连边。
很自然的可以想到选择离根最远的那个点,然后连边。
但思考后可以发现这样并不是最优的,如图。
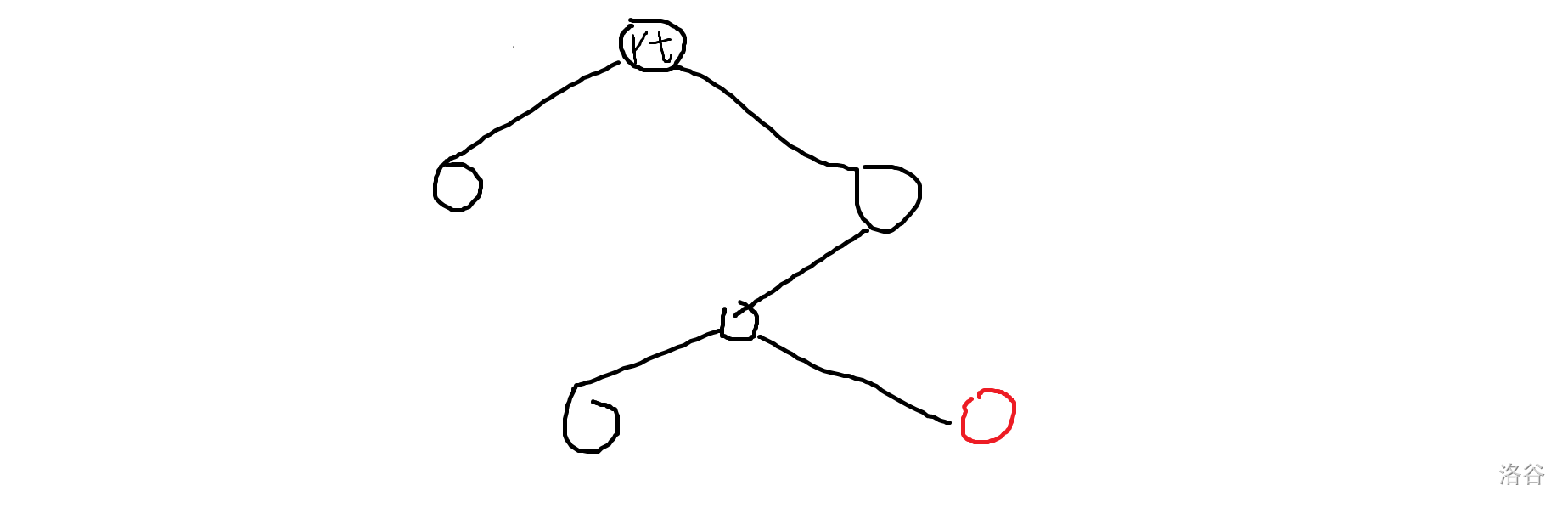
红色节点是我们要连接的点。
如果我们连接了 和红色节点,那么我们就要连两条边,方案如下(蓝色是新连的边):
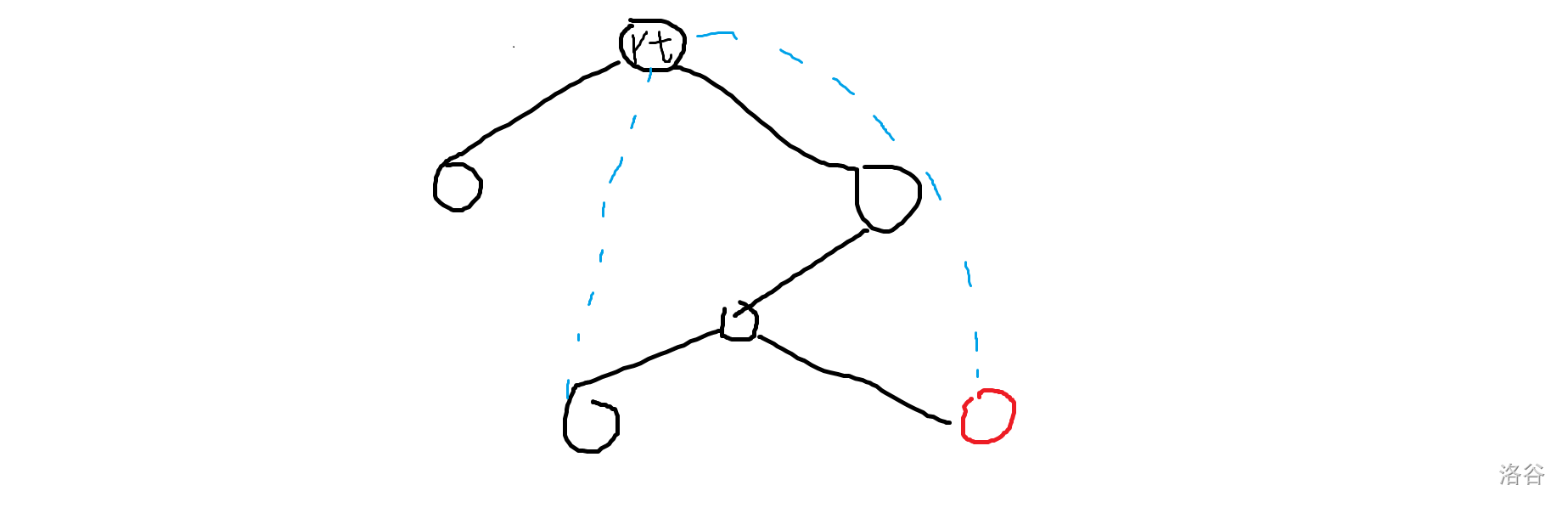
然而可以发现,如果我们连接红色节点的父亲节点显然只要一条边。
那么我们就可以找到一个离红色节点最远的点,使得这个点与红色节点的距离不超过 (因为到达那个节点还要走一条边)。
那么就有两种方法连接,要么连接其父亲节点,要么连接儿子节点。
但由于我们是按深度从大到小选择,所以其儿子一定是合法的了。
所以我们直接连接父亲节点就好了。
在连接完节点后要把其和与其相邻的点标记,不再操作(因为这些点已经合法)。
Fake Plastic Trees
干脆改成图树选讲得了
对于每一个点,显然有一种最优的策略,那就是我们让这个点的 值最大(前提条件是操作次数要最少)。
因为这样能给其祖先节点带来更多的选择方式。
那么考虑一个点其能获得的在操作次数最少的情况下是多少。
首先,其子节点的 的和是肯定可以得到的,然后分类讨论一下两种情况:
-
:对于这种情况,显然需要对该节点额外进行一次操作,那么答案增加,且将 改为 (反正都花代价了,为什么不选一个最好的呢?)
-
:对于这种情况,我们需要判断其值有没有超过 如果超过了就设为 。
水の数列
一个很妙的题,还是写一下吧。
(由于该问题需要化简,所以就从题目背景中的题来讲吧)
问题 1:
贪心水题,题目中有做法了。
问题 2:
考虑到值域只有 ,那么枚举 然后暴力给区间打标记。
但这样就变成 了(离散化后是 ,但 有 没影响)。
考虑如何快速的维护区间。
不难想到,我们从小往大枚举 ,然后把与 相同的数在序列中标记,那么每次我们都会加入一些数。
然后用并查集维护,将区间看作一个集合。
因为要求平方和,所以还要维护并查集每个节点的子树大小。
每次合并计算代价。
代价的增量( 数组存的是子树大小, 是合并后的父亲节点, 是合并后的子节点):
虽然没必要化简但还是化简一下吧
时间复杂度:(当然可以加个按秩合并)
问题 3:
我们在并查集的过程中另外用一个变量计算段数,然后找到段数在 到 中的最大值即可(具体维护方法就是每次将一个数标记为可行就加 1,合并两个集合就减 1)。
时间复杂度:
问题 4:
有 组询问,所以开桶把每个段数的最大答案存下来。
然后维护区间 RMQ。(由于要输出方案,所以要把 与代价捆绑)
用 ST 表 / 线段树会被卡空间。
由于 很小,直接用莫队或分块。
时间复杂度:
问题 5:
不能离线了,所以不能用莫队。
但还是可以用分块。
时间复杂度:
[yLOI2019] 梅深不见冬
贪心好题。
考虑对于每个节点计算代价。
有个显然的贪心策略:当前节点的子节点在当前节点放了数时就可以全部取消掉了。
那么我们就得到了答案的第一种来源:当前节点的权值加上其所有子节点的权值。
然后考虑最大值出现在给子节点放数的时候。
由于前面放的子节点的数当前还不能取消,所以第 个儿子在放置过程中的最高代价是:
然后我们考虑如何安排子节点的顺序。
假设我们已经确定了前 个节点的顺序,考虑接下来 和 那个节点更优。
这样不好分析,所以我们设 要优于 (很多题目都是这样证明的)。
令 ,那么当 优于 时,以下不等式成立:
所以我们把子节点按照 从大到小排序,依次计算即可。
[六省联考 2017] 组合数问题
很好的矩阵乘法题。
首先众所周知组合数是可以用递推来求的。
设 ,则有:
边界条件为 。
这题中要我们求的是,所以相当于求 ,所以设 表示 ,则有:
那么答案就是 。
但是考虑到 很大,直接递推显然超时,但 和 很小,所以直接矩阵乘法优化一下就好了。
为了方便,可以把矩阵的下标从 偏移成 。
Squirrel Migration
首先有一个 trick:如果要让距离和最大,那么以重心为根,每个点都只会往重心的另外一个子树中的点匹配。
证明:
- 每个点是否可向外匹配:
根据重心的定义,每个子树大小都是小于等于 的,所以除了该子树中的点剩下的点数量是大于等于 ,所以一定是可行的。
2.如果不这样进行匹配是否不会更劣
如果有点向同一个子树内的点匹配,可以让每对中的一个点向另外一对中的一个点匹配,这样答案至少会增加 ,所以不这样匹配一定更劣。
那么我们就可以把所有子树的大小拿出来做 dp 了。
直接 dp 显然不好写,考虑容斥。
设 表示前 个子树有 个点向自己子树内匹配,那么有转移方程:
其中 是当前子树大小。
那么根据二项式反演,答案就是:
其中 是子树个数。
Sequence of Substrings
看到这题首先有个很显然的 dp: 表示当前最后一个区间为 ,最多选了多少区间。那么有转移:
这样是 的,无法通过。
我们先不考虑优化复杂度,而是先优化一下 dp 的方式。
我们可以把所有串都拿出来,然后按照字典序排序。这样对于每个字符串,我们找到其前面一个不等于它的串,并且这个串在原串的位置也要在它前面,然后进行转移。这时我们可以用线段树维护每个串结尾的位置对应的 dp 最大值,优化转移。
此时转移的复杂度已经较低了(虽然仍然无法通过),我们考虑优化这个排序。
排序本身很难优化(最多也只能用二分+hash优化到 ),所以我们考虑用某些东西替代排序。
不难想到我们可以用字典树!(下文中该节点对应字符串是指从根节点到当前节点路径上的字符连接)由于是 01 串,所以只有两个儿子。画个图不难发现该节点对应字符串字典序要小于左儿子的字符串的字典序,而左儿子对应字符串字典序要小于右儿子的字符串的字典序,所以我们先对当前点进行转移,然后递归处理左儿子,最后处理右儿子。
现在时间复杂度是 的了,但依旧无法通过,原因是我们现在字符串的个数就有 个。考虑如何让字符串个数减少。
结论 1:如果选择的后一个字符串比当前结尾的字符串长,那么其长度与当前结尾的字符串的长度之差不会超过 1
证明:
考虑如果有一个字符串长度比前一个字符串多 2 会怎么样。
不难发现,此时我们将这一个字符串的最后一个字符删掉该字符串也是比前一个字符串的字典序大的,而这样显然不会让答案变小(甚至可能变大)。
结论 2:一定有一种合法的选择方法使得答案最大且选择的字符串的长度均小于等于 。
证明:
在结论1的条件下,如果我们想要最长的串长度最大,那么长度选出的串的长度肯定是 每次加一,那么字符串的长度和就是 ,由于字串之间不能相交,所以 。
有了结论 2,我们就有了一个很强的优化:枚举长度小于等于 的字符串,然后进行 dp。这样时间复杂度是 的,瓶颈在于 dp 转移时的线段树优化。
CF1537F
一道结论型的图论题。
约定:
偶环:节点个数为偶数的环使得任意不相同两点之间有且仅有 2 条简单路径的环。
奇环:节点个数为奇数的环使得任意不相同两点之间有且仅有 2 条简单路径的环。
令点 的权值为 ,有 ,其中 为题目给出的。
称一个图为好的当且仅当这张图是否可以在有限步操作中,使得每个节点满足 。
基础结论:
结论 1:对于一个偶环,这个偶环是好的当且仅当将其黑白染色后所有黑点的权值和等于所有白点的权值和。
证明:
染色后每个黑点想要使自己点权变化那么左右的其中一个白点也会变化,所以黑、白点权值之和的差值不变。要使得最后权值都为 0,那么黑、白点权值之和必须相等。
对于这个结论,还有一个小推广:该结论对于所有二分图都有效,证明过程类似。
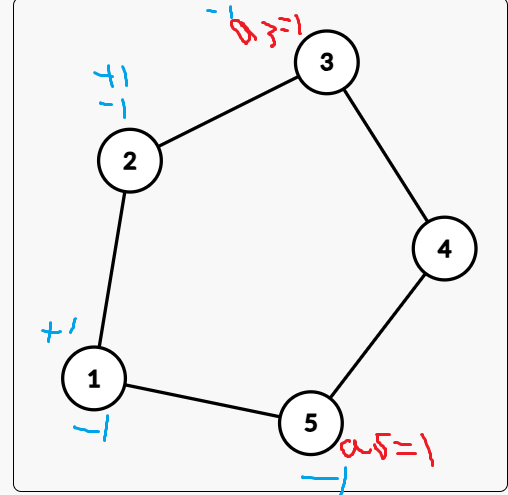
结论 2:对于一个奇环,这个奇环是好的当且仅当其点权之和是偶数。
证明:
对于一个奇环,两点间的两条路径长度一定一个是奇数一个是偶数,那么如果有两个点要同时操作,就找到长度为奇数的那条路然后一加一减即可,如图:
这个结论对奇环上挂了树同样适用。
一般性的结论
前面考虑了一个环的情况,现在考虑更一般性的,也就是两个环,或环上挂了树。
两个环有以下三种大致状态:
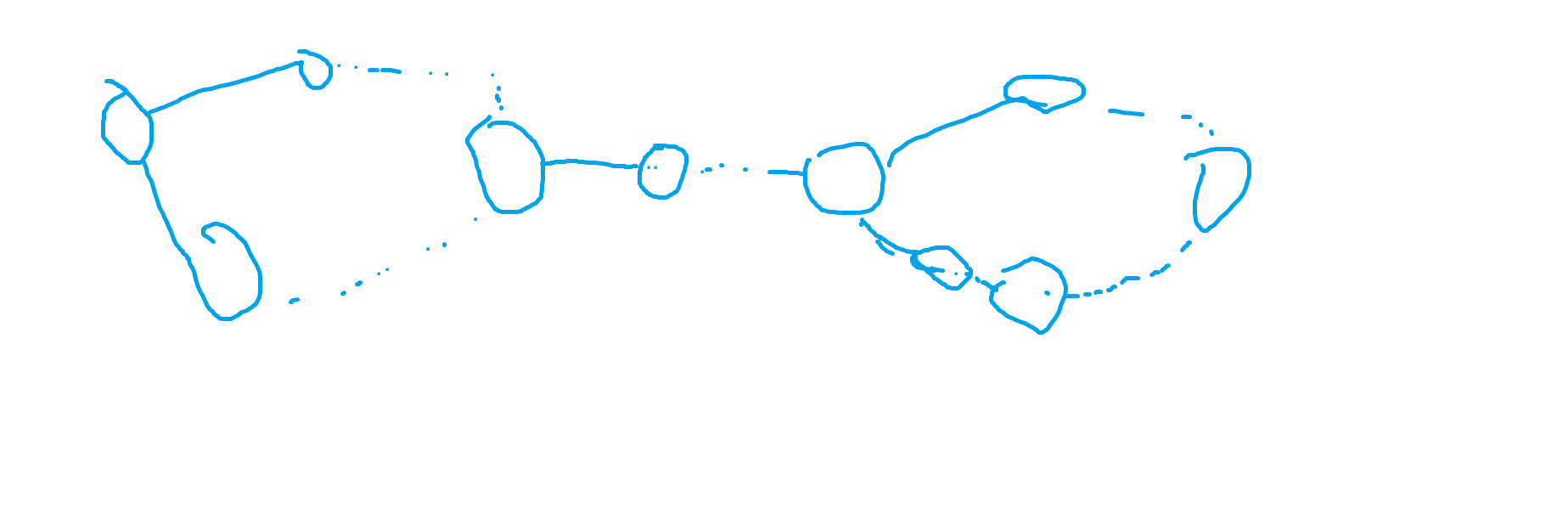
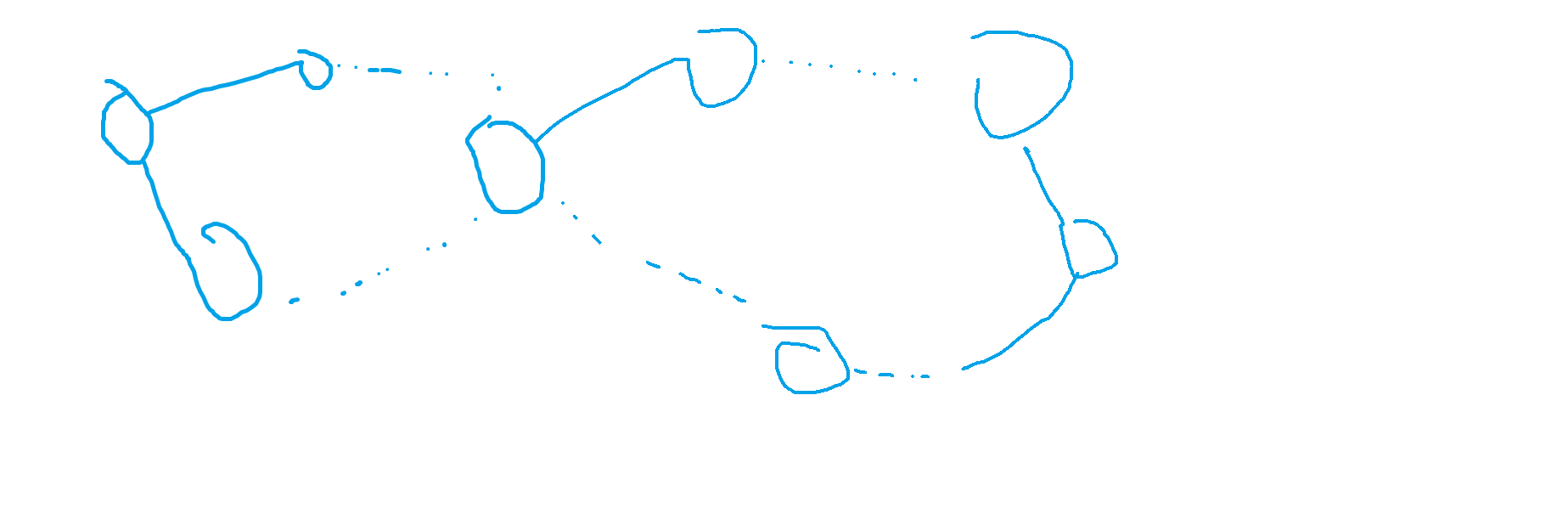
下文只考虑第三种,事实上这三种不同形态推导结论的方式是类似的。
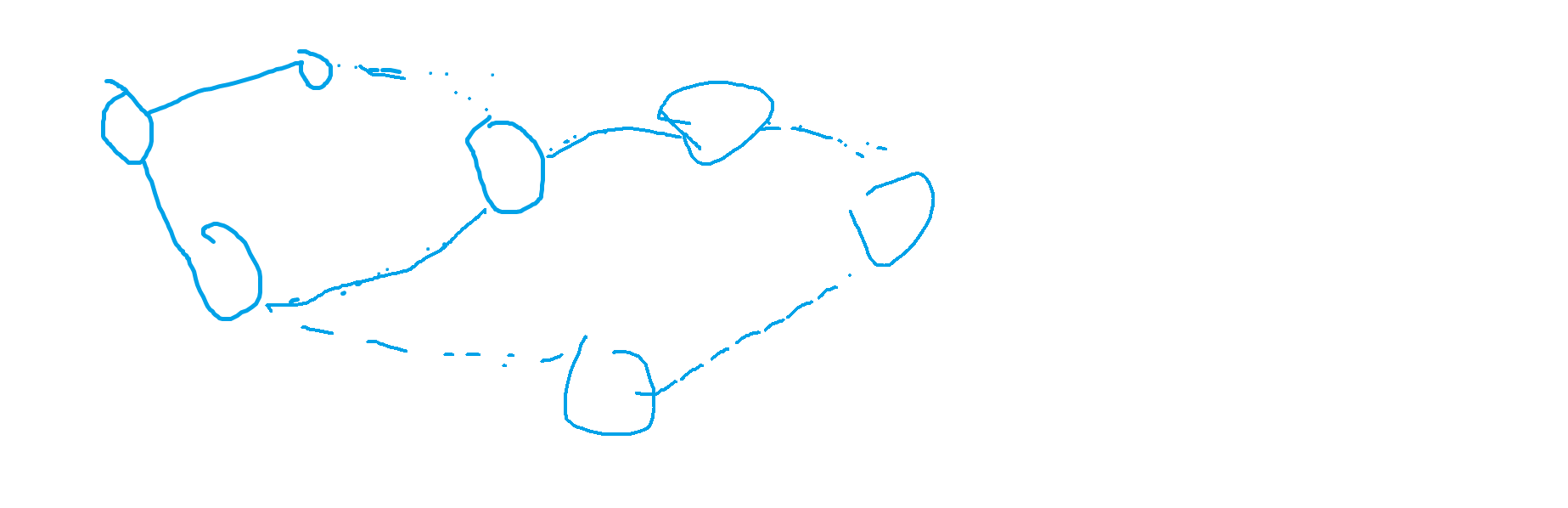
1. 两个偶环相接
如图:
由于两个偶环接在一起是一个二分图,根据基础结论 1 的小推广,该图可以视作偶环。
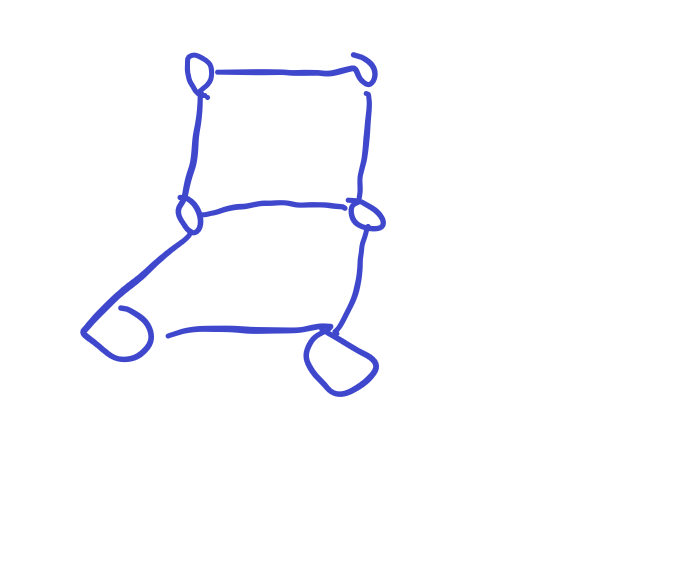
2. 偶环与奇环相接
如图:
考虑一种最基础的,这张图上只有两个点的权值为 1。
如果这两个点都在偶环上,那么可以从如下路线一加一减,得到答案:
如果都在奇环上,那么直接就是结论 2。
如果一个在偶环上,一个在奇环上,那么把中间那条边删掉对答案没有影响,所以依旧是结论 2。
综上所述,偶环与奇环相接的情况就相当于奇环。
3. 奇环与奇环相接
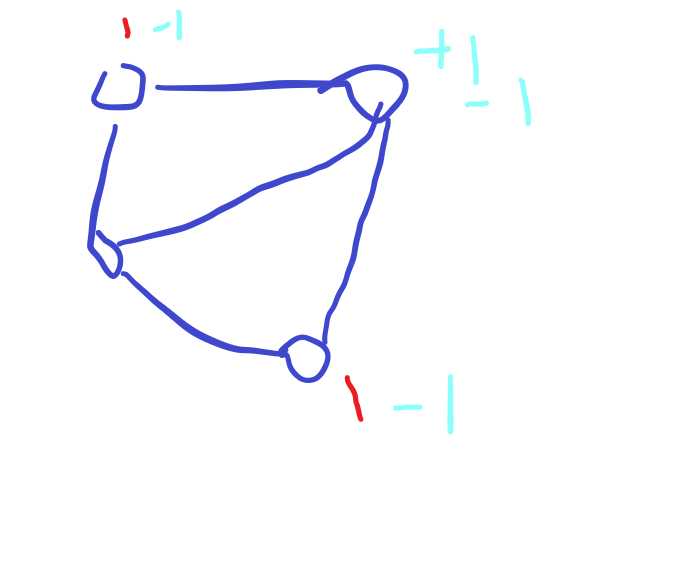
如图:
依旧考虑这张图上只有两个点的权值为 1。
如果两个点在同一个奇环上,那么就是结论 2。
否则,如下图:
由于环大小是奇数,所以将中间那条边经过一个奇环但不走中间的边的路径长度是偶数的,而经过中间的边路径长度是奇数(也就是 1),所以这两点之间一定有一条长度为奇数的路径,在这条路径上操作即可,如图:
综上所述,两个奇环相接的情况就相当于奇环。
4. 环上挂树
此时我们只要考虑奇环的情况,因为偶环在此时是二分图。
如图:

我们可以从树的叶子节点开始,不断向上进行修改,将所有权值转移至环上,然后就是结论 2。
综上所述,如果一个图中包含奇环,那么就可以视作奇环,否则视作偶环。
实现
用 Tarjan 求一个生成树,然后对于每条返祖边,看构成的环是否是奇环。或者直接黑白染色判断是否是二分图,如果是二分图就不存在奇环。
[NOIP2022] 建造军营
不难发现,只有割边被炸才会导致两个关键点无法互相到达。所以我们可以直接把边双连通分量缩在一起。
缩完之后这张图就会变成一棵树。
考虑在这棵树上做dp。
定义 表示在 的子树中没有出现关键点, 表示在 的子树中出现了至少一个关键点。
但这样很容易重复,所以我们钦定 这条边一定不选。令 表示第 个边双内有多少条边, 表示有多少点, 表示这棵子树里有多少原图的边(包括边双内的),这样答案就是 。(因为其它的边随便选不选)。
考虑转移,首先 很好转移,转移如下:
然后考虑 ,对于一个儿子 ,考虑一下两种情况:
- 之前的儿子和 都没有出现关键点
有:
- 之前的儿子或 中出现了关键点
有:
两种转移合并一下就好了,总时间复杂度为 ,预处理逆元可以做到线性。
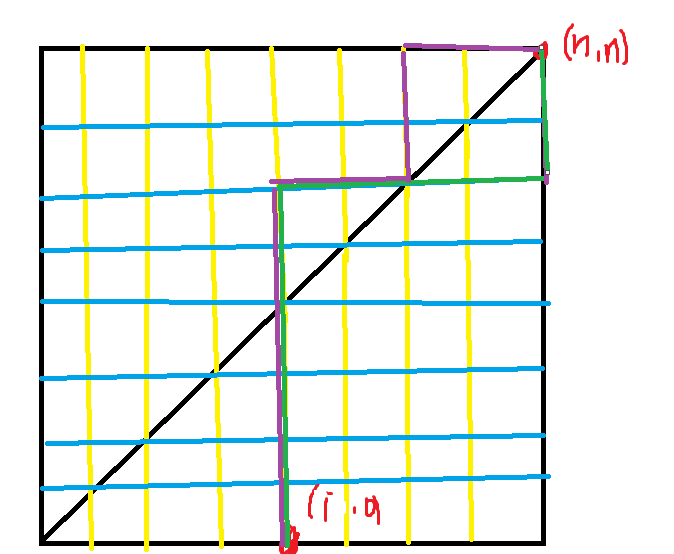
[CTSC2018] 暴力写挂
令 为 的距离,。
首先这个答案代价很难计算,所以考虑进行一个式子的推:
推成这样我们就可以开始考虑继续解题了。
首先我们对第一棵树做点分治,令当前根节点为 ,定义 中 ,那么我们就可以枚举 ,然后找到两个 使得无论在那一棵树上以当前枚举的点为根它们都不在同一个子树内。
这个问题可以用 dp 解决。设 表示 这棵树中 子树内最大的 对应的 , 表示 这棵树中与 不在第一棵树的同一个子树中 最大的对应的 。转移的时候枚举当前的两个状态和当前儿子的两个状态即可。
但这样复杂度是 的,无法通过。
但不难发现,其实我们所有 dp 中有用的点数量加起来是 级别的,所以可以用虚树对这个过程进行优化。
总时间复杂度 ,瓶颈在于建虚树,不过对 排序的时候可以使用 stable_sort降低常数。
Nauuo and Pictures (hard version)
考虑 dp。
设 表示对于第 张图片,现在进行了 次操作,其中 次是将某数加一,权值的期望值。 转移是简单的。
这样时间复杂度是 的,考虑优化。
考虑将每个照片拆成 个同类的且权值为 的照片,那么现在照片就只有两种: 等于 或 等于 。
那么就可以将 那一位去掉。 设 表示进行 次加一操作, 次减一后的期望代价,有转移:
这样时间复杂度是 ,可以通过本题,但预处理逆元可以做到 。
Anticube
首先有个想法:对每个 分解质因数,然后用 找到与之冲突的数,取两者中间出现最多的数。
但这样是 的,无法通过。(不过好像可以 BSGS?
考虑优化:首先可以先将 内的质因数先除掉,这样是可以实现的。
那么剩下的数就一定是一下几种形式:, 和 。
首先考虑剩下的是 ,那么直接开根就行。
如果剩下的是 ,那么想要与它凑成完全立方数就只能含有 ,但 都是大于 的整数
,所以 ,直接将答案加一,不要放进 。
剩下 同理。
那么这样我们就以 解决了这道题。
PS:为了防止类似 abs((__int128)x) 之类的悲剧发生,这边建议手写 的开根。(虽然这题没有涉及 __int128,但有精度问题的函数少用)。
Minimum Sum of Maximums P
首先考虑把这个奇怪的贡献拆一下,可以拆成:。
为了避免一些奇怪的边界,我们在序列左右插入一个极大值,最后减去即可。
考虑到 是固定的,所以我们要最小化 。
设区间左边那个固定点值为 ,右边那个值为 ,若 ,那么直接将这段数从小到大排序一定不会更劣。类似的,如果 ,那么可以直接从大到小排,证明显然。
对于一段区间,设该区间的最大值为 ,最小值为 ,那么该区间的代价是:
(其中 和 是这段区间左右固定的数的值)
那么我们现在的任务就是分配每一段的最小值和最大值。
结论:对于两段编号为 的区间,这两段区间的值域要么完全包含,要么没有相交。
直接反证是比较简单的。
那么我们就可以设计状态,设 表示当前值域区间为 ,已经固定了的区间集合为 ,那么有转移:
-
没有值域恰好为 的区间:
-
将两段拼起来,设 集合为 的段的长度和,有:。
-
正好有 的区间:,其中 是第 段值域为 时的代价。
这样时间复杂度是 的,瓶颈在第二个转移。
[ABC305Ex] Shojin
首先考虑如果只能分一段,怎样排列是最优的:
首先如果 ,那么肯定是将 放在最后面。
接着设现在有两个数 ,,且 放在前面比 放在前面优,此时满足什么性质。
可以得到 放在前面的代是:, 放在前面的代是:。
那么此时有:
化简一下:
最终得到:
因为已经判掉了 ,所以可以直接除。
接着考虑计算答案。设 表示前 个数分成了 段代价的最小值,有转移:
其中 是区间 的代价。
这样复杂度是 的,无法通过。
考虑优化。首先先把 全部删掉,因为这些数的贡献都是 ,最后加上即可。
这时可以发现,我们选择的每一段的长度最多是 级别的。因为此时所有的 ,且,所以如果选择了长度为 的区间,那么这个区间的值至少是 。
那么就可以处理所有长度小于等于 的区间的代价,每次转移时也只枚举最近的 个位置,暴力转移即可。
此时时间复杂度降到了
那么现在优化方向只能放到第二维上了。
一种显然的方法是二分最少需要多少段,然后用 wqs 二分去限制段的数量,进行 dp。时间复杂度 ,也许可以通过(?
但实际上我们并不需要二分最少需要多少段。直接用 wqs 二分。对于一个代价 ,每增加一段代价增加 。如果代价为 时最后的答案小于等于 ,那么就往大的数找,否则往小的数找。要注意如果转移的值相同要优先选段数最大的(这样能让最终实际的代价最小),然后如果二分出的 对应的 比 小,就可以进行调整,将段数减少 并且让 增加 。
最后特判一下所有 都等于 的情况。
[北大集训 2021] 简单数据结构
大大大大大ds。
首先考虑考虑最开始所有的 都为 时怎么做。
那么此时 是单调不降的,用线段树维护区间和区间最大值并支持对 加上 ,每次 checkmin 就是把一段后缀赋值成某一个数,至于后缀位置就是从后往前最后一个大于操作给出的 的位置,在线段树上二分即可。
接着考虑如果 最开始不等于 怎么办。
不难发现,那些受到操作 影响的数一定是递增的,而没有受到操作 影响的数可以被表示成 (其中 是操作 的次数),所以考虑把这 个数分成受到操作 影响和没有受到操作 影响两个部分,设没有被影响的集合为 ,被影响的集合为 ,用线段树维护即可。
那么现在的问题是如何在 的时候把 中的一些元素快速的丢到 里去。
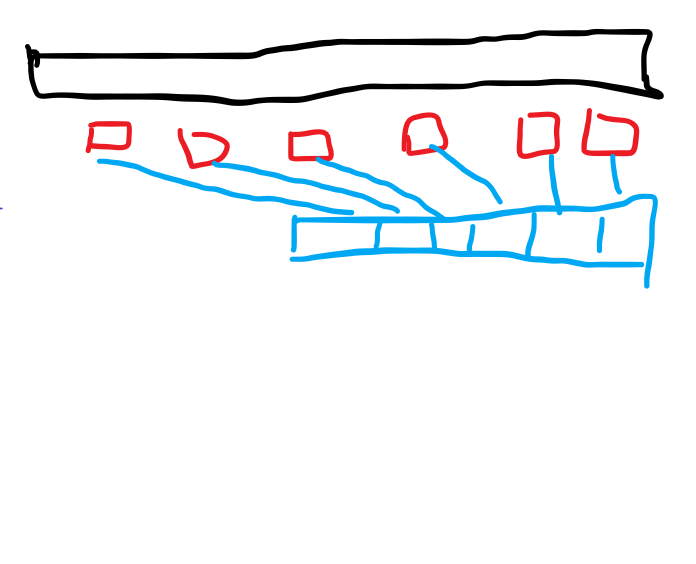
考虑哪些要从集合 丢到 中的数满足什么性质。令当前操作 此时为 ,不难发现这些数要满足 ,移项可以得到 。这相当于要将一个半平面内的数从 丢到 ,如图:
这些红色的点就是需要移除的。
考虑分块凸包。把每个数看作一个点 ,然后分成 个块。每个块内建立一个下凸壳,每次暴力在凸壳上找到一个点使得 ( 在本题中是当前操作 的个数的相反数, 是 checkmin 时题目给出的 ),然后把这个点删掉。删掉后可以直接暴力重构凸壳。这样子每次删掉一个点复杂度是 的(因为已经满足 递增了,不需要排序),一个点只会被删 次,所以这部分的时间复杂度是 的。删除的时候可以双指针做(每次删点不要重新从凸壳的第一个点开始遍历,直接从被删除的点的前一个开始),但其实直接从头遍历好像复杂度也是对的(?
由于 中不一定包含所有数,所以线段树要记录每个位置上的数有没有加入 ,记录的信息只记录已经加入了 的那些数。集合 可以用树状数组维护,因为只要维护第 个位置是否存在 中,然后每次找到在分块凸包中被删除的数单点修改。
总时间复杂度
代码比较复杂,细节比较多,要稍微注意一下线段树下传 tag 时加法和赋值的顺序以及对区间最大值和区间和的影响。
P5064 [Ynoi2014] 等这场战争结束之后
个人感觉比较友好(?的一道 Ynoi。
首先操作 2 非常难受,所以直接根据操作建一棵树,那么就可以通过遍历这个树来完成回退操作了。
维护连通块可以使用并查集,而查询区间第若干大可以用分块。分块记录某个块内以某个点为根有多少点,合并两个联通块时直接暴力把分块的每个块加上,撤回时同理。
这样空间是 的,无法通过,考虑优化。
由于该算法常数较小,所以时间上有很大的余地,所以可以调大块长始块数变少。实测 最好。
此时只有 24 分,但是记录块内信息的数组的值不会很大,所以可以直接用 short。
这样有 88 分,最后用 inline 优化一下,然后选择一个较好的语言即可通过。
最后注意一下并查集因为要撤回所以不能路径压缩,要启发式合并。
DZY Loves Math

进行一个式子的推:
令 。
函数可以通过线性筛进行预处理,考虑怎么处理 函数。考虑线性筛在筛质数时筛的方式是每次找到最小质因子,所以记录当前的最小质因子和最小质因子的次数和 的值,转移时更新即可。然后枚举每个 不为 0 的数,更新其每个倍数的值。
最后对 进行整除分块,时间复杂度 ,不过预处理只要考虑 不为 0 的数,所以跑不满。
[AGC064C] Erase and Divide Game
首先考虑数的数量很少可以一个个加入该怎么处理。考虑删除一个所有的奇数或偶数并且将剩下数除以 2 会产生什么影响。考虑将一个数从最低位向最高位插入 trie 树中。那么每一次操作对应的影响就是向左儿子/右儿子走一步。所以将每个数都插到 trie 中,那么一个人输了就是到达了一个空子树。在 trie 上做 dp 即可。
考虑区间长度很长的情况下该怎么优化。考虑将区间 分解成若干个 的区间,那么每个区间内的所有数插入到 trie 中对应的就是一个大小为 的完美二叉树,下面接着一条链。而链的数量暴力插入是可以接受的,考虑优化掉完美二叉树的插入。
考虑建 棵 trie,第 棵 trie 表示这个完美二叉树的大小 。那么长度为 的区间就插入第 棵 trie 中。
考虑在这 棵 trie 上进行 dp。设 表示在这 个 trie 上第 个 trie 上当前这个位置为 。转移时将每个点向左儿子或右儿子移动即可。
实现时对于第 棵 trie 先构建一条长度为 的链。
时间复杂度按照实现方式为 到 。
[AGC063C] Add Mod Operations
首先考虑如何判断无解。对于一对 ,如果 且 那么就一定无解,否则一定有解。
对于 都相同的一对数,可以只考虑一个位置,所以可以对原数组去重。然后按照 排序。
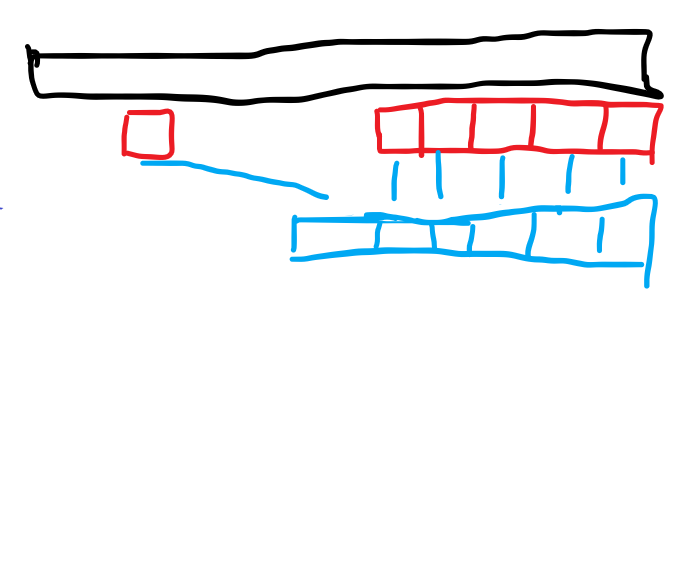
考虑选择了一对 进行操作会对序列产生什么影响。将所有数放在数轴上,如图(借用了 at 的官方题解的图):

相当于是把从 到 这条线段移动到了整体的前面。
通过若干次平移可以得到如下形式:
如上图,有 ,所以现在的目标是构造出 ,使得所有的 。
首先有 是等于 的,这显然不符合要求,所以最后可以进行一次 , 的操作,那么现在要让所有的 。
考虑到 ,所以 。然后考虑第一次操作要减去 这一段,所以 。
[AGC064D] Red and Blue Chips
神仙找性质数数。感觉题解有些地方没太写清楚,这里稍微补充一些。
考虑校验答案序列的合法性。首先 R 和 B 的数量显然要和原串一致,接着考虑反向进行操作,在原串中从后往前遍历,维护当前字符串集合。
从第 位开始,如果第 R,那么直接将当前的所有字符串中找到任意一个开头为 R 的字符串将开头的字符移除(如果找不到 R 开头的串就说明该答案串不合法)。否则如果 B,那么可以将当前的字符串集合中在原串中的任意一个串分成两个以 B 结尾的分裂前的串的前缀和后缀,塞入当前的字符串集合中。
考虑模拟对原串为
RBBRRB,答案串为RRBRBB进行如上操作。时,原串分裂成
RRBRB和B,由于原串以B为后缀,删除B。时,
R,将RRBRB开头的R删去,此时字符串为RBRB。时,
R,将一个RBRB最开头的R删去,答案串变为BRB时,
B,对字符串分裂成B和RB,由于原串以RB为后缀,所以删除RB中的B,变为R。时,
B,删除B,此时还剩下RB。时,
R,删除字符串R此时,集合为空,说明该答案串合法。
分析一下我们操作的过程,每次遇到 R 的操作显然删除任意一个开头的 R 都是一样的,但遇到 B 的时候分裂的方式会影响最终的结果。由于可以任意进行分裂,而不合法情况是由开头的 R 决定的,所以分裂时会选择可以分裂出的 R 最多的方案。
令 表示答案串中第 个极长 R 连续段的长度, 表示答案串中有多少极长R 连续段, 表示将原串 后第 个极长 R 连续段的长度, 表示原串中的极长 R 连续段个数。于是在同满足如下条件时合法:
-
-
-
将 从大到小排序,有:。
这个式子当时想了很久才想明白,所以稍微解释一下。
要从大到小排序是因为每次分裂时可以选择让 R 的数量尽量的多,但是由于开头的一段最开始就可以取出,所以 不参与排序。 是因为每次分裂后开头的 R 数量只有 个,而此时在操作中已经删除了 个 R,所以如果答案序列要合法必须要满足当前所有分裂出来的字符串开头的 R 的数量足够进行操作。
那么现在问题就转化为了对 数组计数(下文中的 数组如果没有特殊说明指的都是去掉 后的数组)。
首先对排序后的 数组计数是简单的。但是因为可能会有相同的值,所以不能直接乘上 。假设去掉 后有 种数,第 种数有 个,那么这个排序后序列所对应的方案数为:
由于 是固定,所以考虑对系数进行计算。
设 表示当前最小值为 ,已经确定了 个数,所有数的和为 ,所有满足该条件的系数之和。
拓扑序为 从大到小(因为 要从大到小排序)。
假设原串中 R 的个数为 ,有转移:
其中在从小到大枚举 的过程中如果出现 就要退出循环不再进行转移(具体实现可以参考代码)。
这样做看起来时间复杂度是 的,但是 只有 对,而 的对数大概为 ,这是调和级数,所以只有 对。
因此总时间复杂度为 。
[AGC062B] Split and Insert
考虑倒序进行处理,即把题目给出的的排列 变为 ,那么一次操作就成了从当前序列中取出 个数插入到序列的最后面。
考虑到数据范围很小,所以大概率可以 dp。设 表示操作了 次, 这段值域对应的位置已经排好序。有两种转移:
- 当前时刻不进行操作,那么直接从前一时刻继承,有:
- 当前时刻会进行操作。由于只能选出一个子序列插到最后,所以当前这段排好序的区间只能从两个已经排好序的区间通过操作合并,有:
初始时对于每一对 ,满足 到 的数的位置有序,有 。
总时间复杂度为 。
Beautiful Bracket Sequence (hard version)
一个序列的深度是子序列的最大值,所以考虑如何去确定这个最大值。
假设没有 ?,可以设 ,不难发现 ,,而 从 到 一定是在一直加一,所以找到 的 就是最佳决策点。所以如果序列中一共有 个右括号,那么 一定有 。所以只需要统计 这个序列中的右括号个数即可得到该序列的深度。
所以我们可以在右括号和左括号之间统计贡献。对于 ?,其只有在选择右括号时会产生贡献,并且所有右括号的数量之和要小于当前位置。如果一共有 个问号,那么方案数为 。同理,如果一个位置为右括号,则贡献为 ,这两个东西可以前缀和处理,总时间复杂度 。
Move by Prime
首先考虑对于一个序列怎么计算。考虑到每次操作只能乘上或初除以一个质数,而最后如果数相等那么每个质数的出现次数一定相等。所以对于每个质数分开考虑,显然需要将每种质数的个数变成所有的该质数的出现次数的中位数。
那么对于一个序列,令质数 的出现次数的中位数为 ,代价为:
由于 数组是固定的,所以考虑每个数在系数为 和系数为 时分别会作为子序列中的一个数贡献多少次,即可计算出结果。
于是考虑贡献该如何计算,对于当前计算的一个定值 , 作为因子在这 个数中的出现次数分别为 。对 从小到大排序那么第 个位置在所有子序列中系数的贡献就是:
其中 是质因数 出现次数比 大的数选了的个数加上 的出现次数比左边小的数的数中没有出现的数。
最终枚举 ,对所有 排序,暴力算即可。不过有一些细节,比如说 的数要特殊考虑一下。
总时间复杂度 ,实际上根本跑不满。
Weak Subsequence
一道很不错的数数题。
结论一:如果存在一个长度为 的弱字串,那么一定存在一个长度为 的弱字串使得这个弱字串是由一个字符和一个长度为 的字串组成的。
考虑为什么是对的,观察下面一张图:(其中黑色是原串,红色是选出来的子序列,蓝色是子串)
那么如下这种方案显然是一样的:
所以该结论显然是正确的。
结论二:极长的弱子串的子序列和子串一定开头在整个串的开头要么结尾是整个串的结尾。
这个结论比较显然,如图:
那么往左延伸时显然子串和子序列每个位置的字符都是相同的,所以一定可以延伸到两端。
对于前缀的一段,那么最长弱子串就是最后面的从后往前第一个相同的两个字符中靠前的那个字符的位置加上一。后缀同理。
跟据鸽巢原理,最多在第 一个位置就会出现两个相同的字符。于是暴力枚举不同的位数,组合计算即可。
至于如何计算,可以容斥。用最长弱子串长度 的串的数量减去长度 的串的数量。
剩下的直接分类讨论前面第一次相等的位置的前缀与后面第一次相等的位置的后缀是否重叠,直接计算即可。
ZerOne

考虑每次操作是交换两个子串,不难发现,每次交换完所有 1 所在的位置的编号和是不变的。而所有 1 所在位置的编号和与原串相等的串可以证明一定是可以构造出来的。所以本题等价于计数位置的编号和与原串相等且 1 的数量相等的串的个数。
考虑 dp。设 表示前 个位置,填了 个 1,位置编号和为 的序列的个数。转移时分类讨论这一位填不填即可。
总时间复杂度 。
[JOI Open 2016] 销售基因链
好题!可惜做的时候一直在想 hash 做法还没想出来......
首先考虑没有后缀的情况。那么可以直接放在 trie 上查子树内字符串出现个数,dfs 预处理一遍就好。
考虑现在加入后缀。那么我们可以对后缀也建立一棵 trie,那么问题转化为同时出现在两棵 trie 的两个子树内的字符串个数。
考虑求出 trie 的 dfn 序,那么现在就相当于转化成了同时在两个区间内出现的字符串个数。设一个字符串 在第一个 trie 上出现的位置是 ,在第二个 trie 上出现的位置是 。那么我们可以将其设为点 。那么询问就可以转化为一个矩阵内点的数量,离线二维数点即可。
(ox) Alternative

一道很好的格路计数题。
首先我们可以注意到 o 的存在其实没有很大的意义,只要在最后将答案乘上 即可。
接着考虑先找一些性质将问题简化一下。不难发现当 时,如果 ,答案一定为 。 且 时答案为 ,那么接下来只要考虑 的情况,于是现在把右括号的数量也视为 。
考虑如果已经确定了 个左括号和 个右括号的排列情况,要将若干个 x 插入到序列中的方案数如何计数。注意到 x 插入的位置其前缀的左括号一定比右括号多至少一个,后缀的右括号一定比左括号多至少一个,那么以下这些黑线在的位置就是不合法的:
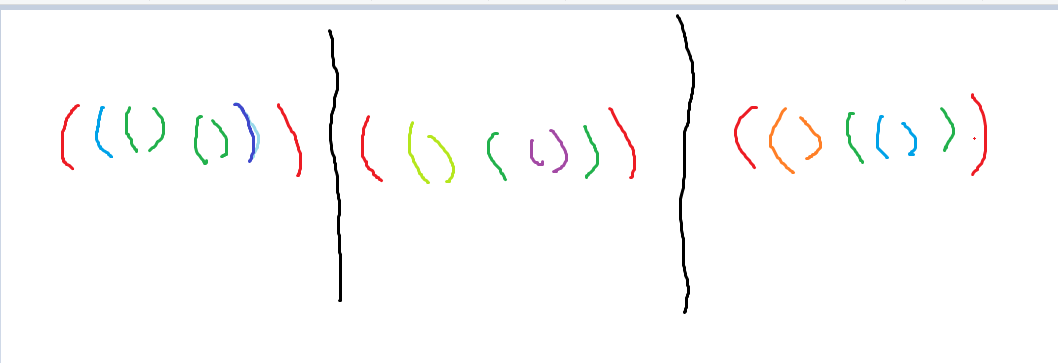
注意到这些黑线将整个括号序列分割成了若干个合法的括号匹配,假设一共分成了 个括号段,那么插入的方案数就是 。
那么就可以枚举一共分成了多少个括号段,然后计算方案。假设当前分成了 个括号段,考虑该如何计算方案数。
首先先将这个问题稍微变下形,如图:
不难证明,这三种形式是等价的。
将一个左括号视为在一个大小为 的矩阵上向右走一步,右括号为向上走一步。那么原问题就可以变为钦定了先向右走 步,然后走到点 且不越过直线 的方案数,如图:
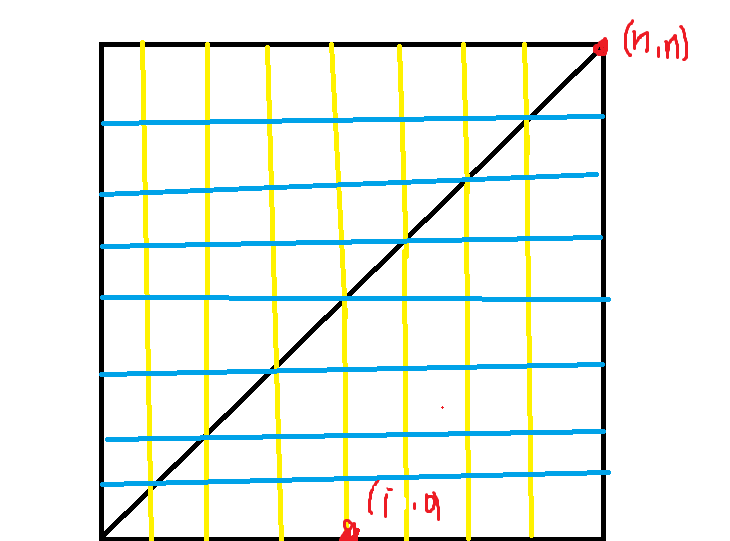
答案就是从 走到 的方案数。
考虑与从 开始走一样操作。对于一条越过了 这条直线的路径,可以在其第二次到达直线 时将其剩下的部分以 这条直线为中心翻折,比如下图绿色路径翻折成了紫色的路径:
一条合法的路径最后一定会经过点 ,所以说一条不合法的路径一定会经过点 ,所以说用 到 的方案数减去 到 的路径数即可,所以方案数如下:
那么答案式子为:
对该式子进行化简:
考虑将枚举 换为枚举
[AGC038E] Gachapon
一道很好的题,感觉和 重返现世 有点像,但推式子更为困难。
首先看到每个题目要求每个 都出现了至少 次,不难发现这是要求对于每个位置 出现了 次的期望随机次数的最大值,可以考虑使用 min-max 容斥:
那么问题就变为了对于一个集合 ,期望操作多少次使得其中某个数出现次数大于等于 。
首先如果一次操作选择的数在集合 之外那么这次操作是没有意义的。设 (下文的 都是这个含义),不难计算出选择的数在集合内的期望操作次数:
那么现在只需考虑每次操作都选入了集合内的情况,最后乘上 即可(若有 次选在了集合里那么期望就是 )。
考虑需要多少次选择才能满足条件。可以通过如下式子进行转化:
于是现在只要考虑每次操作完都不满足的概率之和即可,也就是说要计算操作出一个数组 满足 且 的概率。这个东西很好计算,公式如下:
设 ,把原式变换一下形式得到:
现在已经计算出了如果每次都选入集合的期望次数,乘上 可得到 内存在位置满足其出现了至少 次的期望操作次数(其中 ):
那么最后答案的式子就是:
考虑我们需要得到的信息:
- 容斥系数
这个东西很好处理,在后续 dp 转移时每次选择一个数就取反符号即可(详见 dp 转移式)。
也就是说我们需要记录集合中出现的数的 之和。
也就是说要记录选择了的序列的和。
剩余的贡献可以在 dp 中计算。
于是可以开始 dp 了。设 表示前 个数,我选择的这些数所选择的 的和为 ,我选择的数的 的和为 ,有转移方程:
注意一下边界条件 即可。
[AGC036D] Negative Cycle
神仙题。
发现这个东西在图上非常不好处理,考虑转化一下。
注意到题目的限制是不存在负环,于是很自然的能想到 SPFA。对于一张图,若其没有负环,则说明其差分约束有解,于是转化成了一个序列问题。
假设我们现在确定了最优的删边策略下差分约束的解为 。由于初始的 的边无法去掉,所以一定有 ,考虑其差分数组 ,那么有 。
那么对于一对数 满足 ,那么考虑其两条边能选择的情况的性质。
- 边 可选择
那么有 ,即 。
也就是说如果 就需要花费代价删除这条边。
- 边 可选择
那么有 ,即 。
也就是说如果 就需要花费代价删除这条边。
观察需要删去每条边的限制,不难发现对于差分数组的每一个 ,一定有 ,因为这样相较于 可以多满足 这个限制且不会影响别的限制,于是现在就是要确定一个长度为 的 01 序列 。
设 表示 ,且上一个为 的位置为 ,于是有转移:
其中 是这一段产生的代价,分类讨论跨过的 个数不同的区间,有二维前缀和维护一下即可。
ソリティア
先分析一下怎样的矩阵可以填满。
首先四个角的位置显然不可能满足两条条件中的任何一条,所以这四个角必须已经填满。
对于第一行和第三行的位置,其不能满足第一种条件,所以只能通过条件二填满。那么就不能存在一个长度大于等于 的连续段都是空的。
接下来考虑计数。可以考虑对每个位置分配一个数,代表其是第几个被填满的,类似于 AT_dp_t。
设 表示第 列,中间位置是第 个被填的,填的方式是上下都满了/左右都满了。
转移时分类讨论一下当前位置的填法与上一个位置的填发即可。
- 当前位置通过操作 1 填。
前一列的填法可以是任意一种,且编号不重要,那么在这一列的第一行和第三行中对于没有填的位置选择一个比当前位置的编号小的即可。
- 当前位置通过操作 2 填
那么前一列一定要先填满,所以前一列的编号要小于这一列且填法一定是第一种,而这一列的第一行和第三行的编号大小关系不重要,乘上方案数即可。
两种情况都是 的,但是可以用前缀和优化。总时间复杂度 。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)