浅谈分治思想和分治思想的应用
发现自己暑假过的一道分治题不会做了,然后最近又讲了一些新的分治算法,所以就爬回来写博客了。。。(所以为什么普及算法能整出省选的技巧啊!!!!)
基础分治:
首先我们考虑一个 \(2\times 2\) 的矩阵的填补情况。
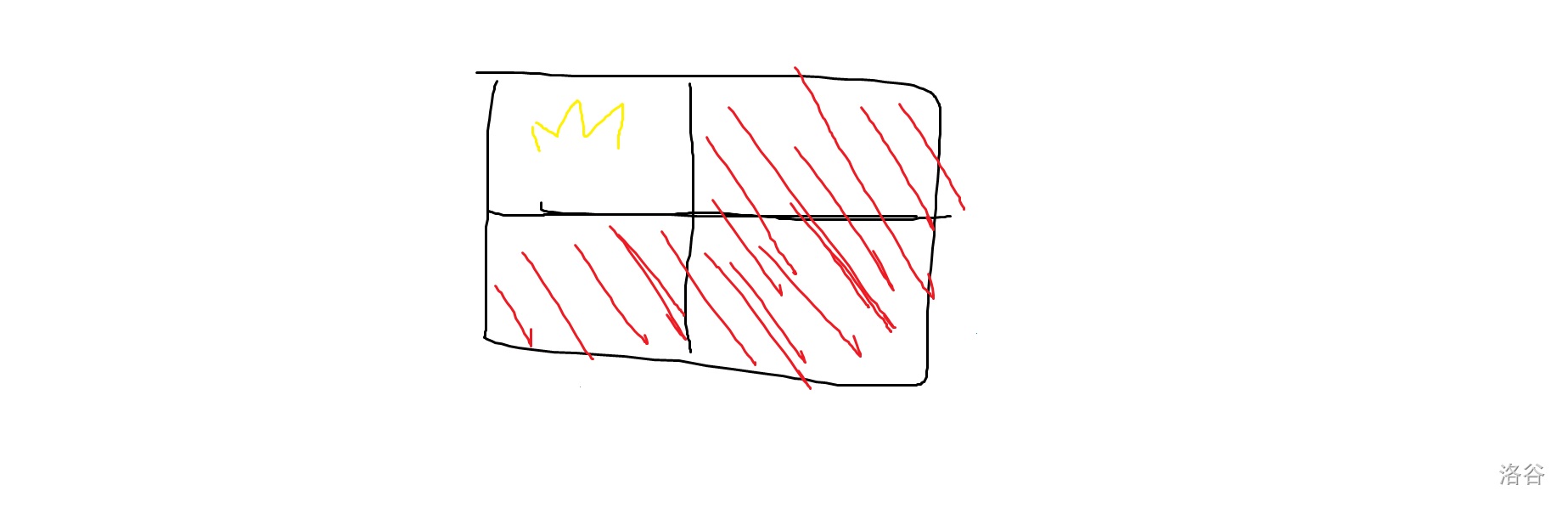
(皇冠那个地方是公主也就是障碍)应该没人看不出来那个是皇冠吧
然后考虑 \(4\times 4\) 时的状况:
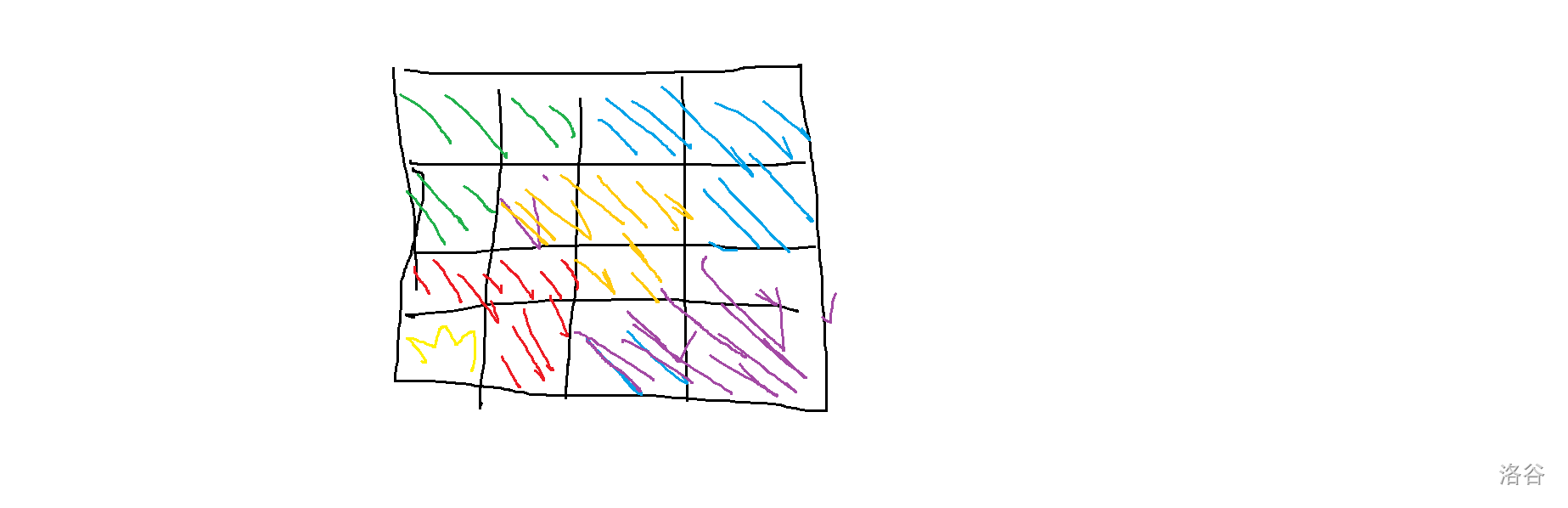
然后我们就可以发现一个技巧:
我们可以把整个矩形分成 \(4\) 个部分,含障碍的部分直接填满,剩下 \(3\) 个部分把缺口放在分割的中心点,然后就可以多用一个矩形填满了。
PS:在实现的时候可以把障碍的位置记录下来。
对于那些没有障碍的格子可以把最 左/右 上/下 角的位置填进去(代表那些位置已经填过了,也就是障碍物)。
code:
#include <bits/stdc++.h>
using namespace std;
int n, ex, ey;
void S(int x, int y, int a, int b, int l) {
if (l == 1) {
return;
}
int sl = l / 2;
if (a < x + sl && b < y + sl) {
cout << x + sl << " " << y + sl << " 1\n";
S(x, y, a, b, sl);
S(x, y + sl, x + sl - 1, y + sl, sl);
S(x + sl, y, x + sl, y + sl, sl);
S(x + sl, y + sl, x + sl, y + sl, sl);
} else if (a < x + sl && b >= y + sl) {
cout << x + sl << " " << y + sl - 1 << " 2\n";
S(x, y, x + sl - 1, y + sl - 1, sl);
S(x, y + sl, a, b, sl);
S(x + sl, y, x + sl, y + sl, sl);
S(x + sl, y + sl, x + sl, y + sl, sl);
} else if (a >= x + sl && b < y + sl) {
cout << x + sl - 1 << " " << y + sl << " 3\n";
S(x, y, x + sl - 1, y + sl - 1, sl);
S(x, y + sl, x + sl - 1, y + sl, sl);
S(x + sl, y, a, b, sl);
S(x + sl, y + sl, x + sl, y + sl, sl);
} else {
cout << x + sl - 1 << " " << y + sl - 1 << " 4\n";
S(x, y, x + sl - 1, y + sl - 1, sl);
S(x, y + sl, x + sl - 1, y + sl, sl);
S(x + sl, y, x + sl, y + sl, sl);
S(x + sl, y + sl, a, b, sl);
}
}
int main() {
cin >> n >> ex >> ey;
n = 1 << n;
S(1, 1, ex, ey, n);
return 0;
}
基础分治感觉这一道题够了(毕竟这个很基础)。
接下来的算法就有点难度了(可能需要一些 tg 组算法(比如线段树来优化))。
CDQ 分治:
先从一道简单题开始。
考虑把序列划分为两个部分:

然后逆序对的贡献就只会有这三种情况(设我们选的分界点为 \(m\),产生贡献的前面那个数为 \(i\),后面那个数为 \(j\)):
- \(i\le m\) 且 \(j \le m\):
- \(m<i\) 且 \(m<j\)
- \(i\le m\) 但 \(m<j\)
可能不太好理解,画个图就好了:
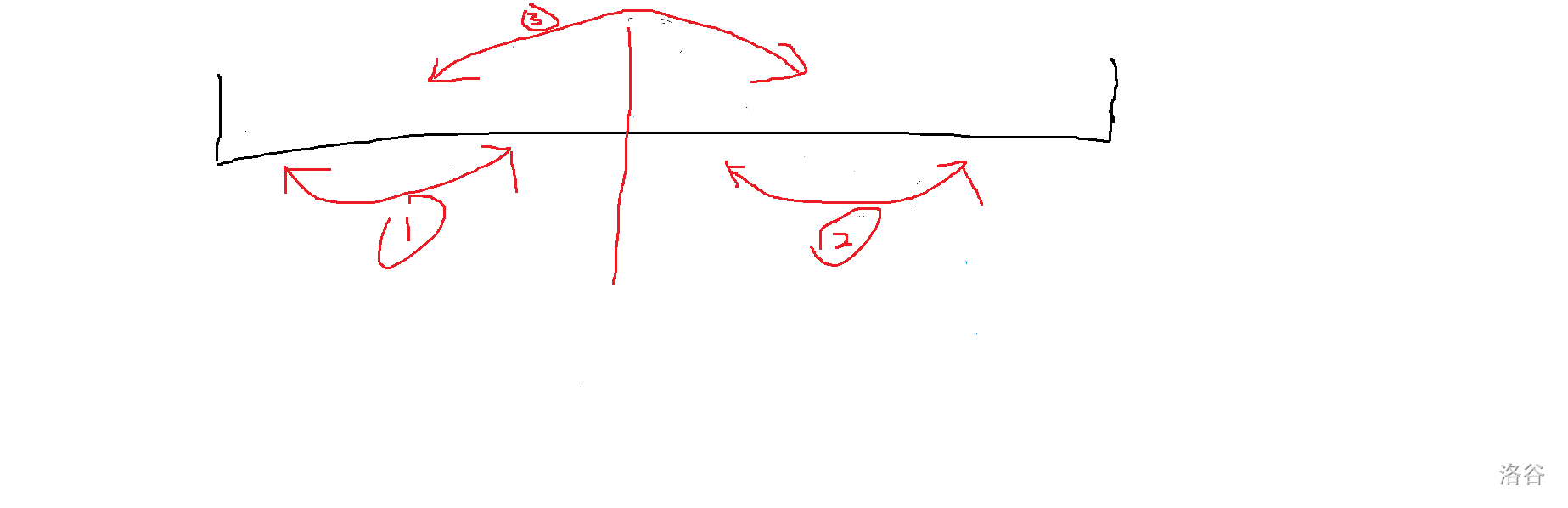
然后考虑去处理这些贡献。
对于第 \(1\) 种和第 \(2\) 种,我们显然可以递归下去处理,考虑第 \(3\) 种。
那么我们将分割出来的两个序列排好序。
然后做一个双指针,枚举左边的每一个数,然后右边的指针移动,找到最大的右边的数使得那个数小于左边的数。
右边的指针指向了第几个位置贡献就会是多少。
然后我们就得到了一个时间复杂度为 \(\operatorname{O}(n\log^2 n)\) 的算法。
这时肯定有人问:普通归并不是 \(\operatorname{O}(n\log n)\) 的吗?这个 \(\log^2 n\) 是那来的?
我们分析一下算法的复杂度来源:
首先,我们每次把区间长度缩小一半,所以递归一定会有 \(\log n\) 层。
对于每一层,我们要对这一层的数进行排序,因为每一层只有 \(n\) 个数,所以时间复杂度是 \(\operatorname{O}(n\log n)\) 的,那么总时间复杂度 \(\operatorname{O}(n\log^2 n)\)。
然后我们可以发现归并排序快就快在其在双指针的过程中合并了两个序列,省掉了排序操作。(但其实在后面的题中是很难快速合并两个序列的,所以这个优化用处不大(目前来说))。
code:
这个应该不需要吧
有时间补。
然后我们开始正式进入一些提高到省选的分治。
CDQ 分治求三维偏序:
首先肯定按 \(a\) 进行一个排序,然后 \(a\) 就可以变为一个下标,那么我们的目的就是求 \(j<i\) 且 \(b_j\le b_i\) 且 \(c_j\le c_i\) 的 \(i\) 和 \(j\) 的个数。
然后和前面的题一样,先划分成两个部分,分别处理。
然后把两边分别按 \(b\) 排序,枚举右边的位置,然后用双指针找到左边最大的小于右边的值的位置。
那么现在的问题就是左边的数中有多少个数的 \(c\) 值小于等于右边的数的 \(c\) 值。
不难发现我们可以在双指针的过程中把 \(c\) 存到一个线段树 / 树状数组里。
由于要输出的是偏序数为 \(i\) 的数有多少个所以我们统计答案时开数组把每个编号的数加上对应的贡献即可。
但是这样会出现一个问题,就是如果有多个一样的数那么答案就会出错。
那么我们先把数组去重,然后对于每个 \((a,b,c)\) 赋上一个值(这个值就是 \((a,b,c)\) 在去重前出现的次数)。
然后每次在数据结构上加上这个数对的权值即可。
还有一个细节:我们清空数据结构时不要直接全部清空(那样会 TLE),可以用模拟计算代价时的循环,然后把增加的操作变成减少。
剩下的一些细节可以看代码。
code:
#include <bits/stdc++.h>
using namespace std;
const int kMaxN = 2e5 + 5, kMaxV = 2e5 + 5;
struct A {
int x, y, z, id;
bool operator<(const A &a) const {
return x == a.x ? (y == a.y ? z < a.z : y < a.y) : x < a.x;
}
} a[kMaxN], b[kMaxN], c[kMaxN];
struct T {
int x, y, z;
bool operator<(const T &a) const {
return x == a.x ? (y == a.y ? z < a.z : y < a.y) : x < a.x;
}
};
int w[kMaxV], s[kMaxN], ans[kMaxN], n, k;
map<T, int> mp;
bool P(A x, A y) {
return x.y < y.y;
}
// 树状数组
void U(int x, int y) {
for (int i = x; i <= k; w[i] += y, i += i & -i) {
}
}
int Q(int x) {
int ans = 0;
for (int i = x; i >= 1; ans += w[i], i -= i & -i) {
}
return ans;
}
// cdq,启动!
void S(int l, int r) {
if (l != r) {
int mid = l + r >> 1;
S(l, mid), S(mid + 1, r);
for (int i = l; i <= r; i++) {
b[i] = a[i];
}
sort(b + l, b + mid + 1, P); // 分别排序
sort(b + mid + 1, b + r + 1, P);
int p = l;
for (int i = mid + 1, j = l; i <= r; i++) {
for (; j <= mid && b[j].y <= b[i].y; U(b[j].z, mp[{b[j].x, b[j].y, b[j].z}]), j++) { // 双指针增加
}
p = j;
s[b[i].id] += Q(b[i].z); // 统计答案
}
for (int i = l; i < p; i++) {
U(b[i].z, -mp[{b[i].x, b[i].y, b[i].z}]); // 清空
}
}
}
int main() {
ios ::sync_with_stdio(0), cin.tie(0), cout.tie(0);
cin >> n >> k;
for (int i = 1; i <= n; i++) {
cin >> a[i].x >> a[i].y >> a[i].z;
a[i].id = i, c[i] = a[i];
mp[{c[i].x, c[i].y, c[i].z}]++;
}
// 去重begin
sort(c + 1, c + n + 1);
int _n;
a[_n = 1] = c[1];
for (int i = 2; i <= n; i++) {
if (c[i].x != c[i - 1].x || c[i].y != c[i - 1].y || c[i].z != c[i - 1].z) {
a[++_n] = c[i];
}
}
// 去重end
S(1, _n);
for (int i = 1; i <= _n; i++) {
mp[{a[i].x, a[i].y, a[i].z}] += s[a[i].id]; // 给每个数对权值增加其偏序个数(方便后面统计)
}
for (int i = 1; i <= n; i++) {
ans[s[c[i].id] = mp[{c[i].x, c[i].y, c[i].z}] - 1]++; // 统计答案
}
for (int i = 0; i < n; i++) {
cout << ans[i] << "\n";
}
return 0;
}
CDQ 分治优化 dp:
相信 \(n^2\) 做法各位巨佬都会,唯一提一下计算概率。
对于每个位置,计算以其为结尾和以其为开头的 \(LDS\) 长度。
然后设以其为结尾的 \(LDS\) 方案数为 \(x\),以其为起点的方案数是 \(y\),\(LDS\) 总共的方案数为 \(sum\),那么概率就是:
然后考虑用 CDQ 分治优化。
首先仍然把序列分成两部分。
但由于 \(dp\) 需要有拓扑序,所以我们先递归处理左边的转移,再处理左右交集的转移,最后递归处理右边的转移。
考虑处理中间的转移。
把数按照 \(a\) 从大到小排序,然后和处理三维偏序一样的,用双指针去扫。
此时要维护一个双关键字线段树。
先比较 \(LDS\) 长度,如果相等就合并,否则选泽 \(LDS\) 大的哪一个.
然后前后分别做一遍就好了。
code(巨丑的代码):
#include <bits/stdc++.h>
using namespace std;
using LL = long double; // 答案可能超过 long long!!!!!(别问我为啥用 LL,问就是懒的改)
using Pii = pair<LL, LL>;
const int kMaxN = 5e4 + 5;
struct A {
LL x, y;
int id;
bool operator<(const A &a) const {
return x > a.x;
}
} a[kMaxN], b[kMaxN], w[kMaxN << 2];
LL f[2][kMaxN][2], c[kMaxN];
int tot, n;
// 0:最大值,1:方案
// 线段树 begin
void U(int u, int l, int r, int x, A y, int op) {
if (l > x || r < x) {
return;
} else if (l == x && l == r) {
if (!op) {
if (y.x == w[u].x) {
w[u].y += y.y;
} else if (y.x > w[u].x) {
w[u] = y;
}
} else {
w[u] = {0, 0};
}
} else {
int mid = l + r >> 1;
U(u << 1, l, mid, x, y, op);
U(u << 1 | 1, mid + 1, r, x, y, op);
if (w[u << 1].x == w[u << 1 | 1].x) {
w[u].x = w[u << 1].x, w[u].y = w[u << 1].y + w[u << 1 | 1].y;
} else {
w[u] = w[u << 1].x > w[u << 1 | 1].x ? w[u << 1] : w[u << 1 | 1];
}
}
}
A Q(int u, int l, int r, int L, int R) { // 查最大值
if (l > R || r < L) {
return {0, 0, 0};
} else if (L <= l && r <= R) {
return w[u];
} else {
int mid = l + r >> 1;
A x = Q(u << 1, l, mid, L, R), y = Q(u << 1 | 1, mid + 1, r, L, R);
if (x.x == y.x) {
x.y += y.y;
} else {
x = x.x > y.x ? x : y;
}
return x;
}
}
// cdq begin
void S(int l, int r, int op) { // 正着做
if (l == r) { // 边界情况
if (f[op][a[l].id][0] <= 1) {
f[op][a[l].id][0] = f[op][a[l].id][1] = 1;
}
} else {
int mid = l + r >> 1, t = l;
S(l, mid, op); // 先处理左边,由于 dp 要拓扑序,所以先左再合并两边最后右
for (int i = l; i <= r; i++) {
b[i] = a[i];
}
sort(b + l, b + mid + 1);
sort(b + mid + 1, b + r + 1);
for (int i = mid + 1, j = l; i <= r; i++) {
for (; b[j].x >= b[i].x && j <= mid; U(1, 1, n, b[j].y, {f[op][b[j].id][0], f[op][b[j].id][1]}, 0), j++) { // 双指针
}
t = j;
A s = Q(1, 1, n, b[i].y, n);
if (s.x + 1 == f[op][b[i].id][0]) {
f[op][b[i].id][1] += s.y;
} else if (s.x + 1 > f[op][b[i].id][0]) {
f[op][b[i].id][0] = s.x + 1, f[op][b[i].id][1] = s.y;
}
}
for (int i = l; i < t; i++) {
U(1, 1, n, b[i].y, {}, 1); // 清空(用 memset 可能会 T)
}
S(mid + 1, r, op);
}
}
bool P(A x, A y) {
return x.x < y.x;
}
void C(int l, int r, int op) { // 反着做
if (l == r) {
if (f[op][a[l].id][0] <= 1) {
f[op][a[l].id][0] = f[op][a[l].id][1] = 1;
}
} else {
int mid = l + r >> 1, t = l;
C(l, mid, op);
for (int i = l; i <= r; i++) {
b[i] = a[i];
}
sort(b + l, b + mid + 1, P);
sort(b + mid + 1, b + r + 1, P);
for (int i = mid + 1, j = l; i <= r; i++) {
for (; b[j].x <= b[i].x && j <= mid; U(1, 1, n, b[j].y, {f[op][b[j].id][0], f[op][b[j].id][1]}, 0), j++) {
}
t = j;
A s = Q(1, 1, n, 1, b[i].y);
if (s.x + 1 == f[op][b[i].id][0]) {
f[op][b[i].id][1] += s.y;
} else if (s.x + 1 > f[op][b[i].id][0]) {
f[op][b[i].id][0] = s.x + 1, f[op][b[i].id][1] = s.y;
}
}
for (int i = l; i < t; i++) {
U(1, 1, n, b[i].y, {}, 1);
}
C(mid + 1, r, op);
}
}
void I(int op) {
for (int i = 1; i <= n; i++) {
c[++tot] = op ? a[i].y : a[i].x;
}
sort(c + 1, c + tot + 1);
tot = unique(c + 1, c + tot + 1) - c - 1;
for (int i = 1; i <= n; i++) {
(op ? a[i].y : a[i].x) = lower_bound(c + 1, c + tot + 1, op ? a[i].y : a[i].x) - c;
}
tot = 0;
}
int main() {
cin >> n;
for (int i = 1; i <= n * 4; i++) {
w[i] = {};
}
for (int i = 1; i <= n; i++) {
cin >> a[i].x >> a[i].y;
a[i].id = i;
}
I(0), I(1);
S(1, n, 0);
reverse(a + 1, a + n + 1); // reverse后反着就相当于正着做 LIS
C(1, n, 1);
reverse(a + 1, a + n + 1);
LL ans[2] = {};
for (int i = 1; i <= n; i++) {
if (ans[0] == f[0][i][0]) {
ans[1] += f[0][i][1];
} else if (f[0][i][0] > ans[0]) {
ans[0] = f[0][i][0], ans[1] = f[0][i][1];
}
}
cout << ans[0] << "\n";
for (int i = 1; i <= n; i++) {
if (f[0][i][0] + f[1][i][0] == ans[0] + 1) {
printf("%.5Lf ", 1.0 * f[0][i][1] / ans[1] * f[1][i][1]); // 计算代价
} else {
printf("%.5Lf ", (long double)0);
}
}
return 0;
}
cdq 分治练习题:
整体二分:
本题可以使用树套树秒掉,但可这里做为整体二分练习题。
首先考虑不带修。
那么可以对于每个询问二分答案,然后计算区间内有多少个数小于当前二分的 \(x\),时间复杂度 \(\operatorname{O}(nm\log V)\),显然无法通过。
那么我们现在就是要加速查询区间小于当前数的过程,显然可以用主席树,但这里给出另一种解法。
我们不妨把询问离线下来,然后暴力枚举答案。
对于每个位置,我们设当前位置为 1 就是该数小于当前枚举的答案。
然后就是维护单点加和区间查,写一颗树状数组即可。
然后可以发现不用枚举答案,可以直接二分。
对值域进行离散化,然后把每个值出现的位置记录下来,然后在二分时把值域区间 \([l,mid]\) 中的数全部加一即可。
然后每个询问进行查询,如果区间内小于 \(mid\) 的个数小于等于 \(x\) 就递归向左二分,否则减去左边小于等于 \(mid\) 的个数,向右递归。
然后考虑加入修改。
有个常见的技巧:把一个修改视为删除原来的元素,再加上新的元素。
然后在二分过程中按照输入时间轴进行修改。
如果修改后的数小于等于 \(mid\) 就把这个修改操作向左递归,否则向右递归。
时间复杂度:\(\operatorname{O}(n\log^2n)\)
code:
#include <bits/stdc++.h>
using namespace std;
const int kMaxN = 2e5 + 5;
struct A {
int op, l, r, x, id;
};
int a[kMaxN], b[kMaxN], ans[kMaxN], w[kMaxN], vis[kMaxN], tot, n, q;
char c;
void U(int x, int y) {
for (int i = x; i <= n; w[i] += y, i += i & -i) {
}
}
int Q(int x) {
int ans = 0;
for (int i = x; i >= 1; ans += w[i], i -= i & -i) {
}
return ans;
}
void S(int l, int r, vector<A> v) {
if (l == r || !v.size()) {
for (A i : v) {
!i.op && (ans[i.id] = l);
}
return;
} else {
int mid = l + r >> 1;
vector<A> al, ar;
for (A &i : v) {
if (i.op) {
if (i.r <= mid) {
U(i.l, i.op), al.push_back(i);
} else {
ar.push_back(i);
}
} else {
int x = Q(i.r) - Q(i.l - 1);
if (i.x <= x) {
al.push_back(i);
} else {
i.x -= x;
ar.push_back(i);
}
}
}
for (A &i : v) {
(i.op && i.r <= mid) && (U(i.l, -i.op), 1);
}
S(l, mid, al), S(mid + 1, r, ar);
}
}
int main() {
cin >> n >> q;
vector<A> v;
for (int i = 1; i <= n; i++) {
cin >> a[i];
v.push_back({1, i, a[i]});
b[++tot] = a[i];
}
for (int l, r, x, i = 1; i <= q; i++) {
cin >> c >> l >> r;
if (c == 'Q') {
cin >> x;
v.push_back({0, l, r, x, i});
vis[i] = 1;
} else {
v.push_back({-1, l, a[l]}), v.push_back({1, l, r});
a[l] = r;
b[++tot] = r;
}
}
sort(b + 1, b + tot + 1);
tot = unique(b + 1, b + tot + 1) - b - 1;
for (A &i : v) {
i.op && (i.r = lower_bound(b + 1, b + tot + 1, i.r) - b);
}
for (int i = 1; i <= n; i++) {
a[i] = lower_bound(b + 1, b + tot + 1, a[i]) - b;
}
S(1, tot, v);
for (int i = 1; i <= q; i++) {
vis[i] && (cout << b[ans[i]] << "\n");
}
return 0;
}
猫树分治:
离线:
首先考虑暴力做法。
直接把区间取出来,然后做背包。
时间复杂度 \(\operatorname{O}(nmt)\)。
考虑进行优化。
我们可以采用分治的思想。
首先把区间放到线段树上面去然后就不好做了。
我们考虑为什么不好做了。
因为一个区间在线段树上被划分成了 \(\log n\) 个区间,所以在合并区间的时候也要做背包, 时间复杂度为 \(\operatorname{O}(mt^2\log n)\)。甚至和直接暴力的运算量差不多。
考虑和整体二分一样把询问分治。那么按照什么条件分治呢?
首先有一个很明显的性质:对于任意一个区间,只要该区间的长度大于 \(1\),那么在线段树的某一层一定会被那个节点所对应的区间的中点分成两个部分。
那么我们就很自然的可以想到一个做法。
先把所有询问离线下来,然后建立线段树,并遍历这棵线段树。
在遍历的过程中,把询问记录下来。
如果该询问区间全在左边的部分或全在右边就递归处理。
那如果该区间两边都涉及到了呢?
我们可以对这个区间做两遍背包,一遍从 \(mid\) 开始往 \(l\) 做,一遍从 \(mid\) 开始往 \(r\) 做,然后我们对于每个区间,枚举我们在左边选择重量为多少的代价,右边的重量就是 \(t\) 减去左边的重量。(合并的过程就相当于做一个 \(n=2\) 的分组背包)。
然后特判一下长度为 \(1\) 的区间就好了。
最后分析一下时间复杂度:对于每个区间,我们要进行一次答案枚举,每个区间枚举时间是 \(\operatorname{O}(t)\) 的,所以该部分复杂度为 \(\operatorname{O}(mt)\)。
对每个区间我们要做一次背包,对于每个位置来说每次做背包的时间复杂度是 \(\operatorname{O}(t)\),而有 \(n\) 个位置,每个位置会被计算 \(\log n\) 次,总时间复杂度 \(\operatorname{O}(nt\log n+mt)\)。
code(思路清楚了实现还是很简单的):
#include <bits/stdc++.h>
using namespace std;
using LL = long long;
const int kMaxN = 4e4 + 5, kMaxM = 2e5 + 5, kMaxT = 205;
struct Q {
int l, r, x, id;
};
LL a[kMaxN], b[kMaxN], f[kMaxN][kMaxT], ans[kMaxM], n, m;
vector<Q> v;
void F(int l, int r, int op) {
fill(f[l], f[r + 1], 0);
if (op == -1) {
for (int i = r; i >= l; i--) {
for (int j = kMaxT - 1; j >= 0; j--) {
f[i][j] = f[min(r, i + 1)][j];
(j >= a[i]) && (f[i][j] = max(f[i][j], f[min(r, i + 1)][j - a[i]] + b[i]));
}
}
} else {
for (int i = l; i <= r; i++) {
for (int j = kMaxT - 1; j >= 0; j--) {
f[i][j] = f[max(l, i - 1)][j];
(j >= a[i]) && (f[i][j] = max(f[i][j], f[max(l, i - 1)][j - a[i]] + b[i]));
}
}
}
}
void S(vector<Q> v, int l, int r) {
if (v.size()) {
int mid = l + r >> 1;
vector<Q> vl, vr;
for (Q i : v) {
if (i.l == i.r) {
ans[i.id] = a[i.l] <= i.x ? b[i.l] : 0;
} else {
(i.r <= mid) && (vl.push_back(i), 1);
(i.l > mid) && (vr.push_back(i), 1);
}
}
S(vl, l, mid), S(vr, mid + 1, r);
F(l, mid, -1), F(mid + 1, r, 1);
for (Q i : v) {
if (i.l <= mid && i.r > mid) {
for (int j = 0; j <= i.x; j++) {
ans[i.id] = max(ans[i.id], f[i.l][j] + f[i.r][i.x - j]);
}
}
}
}
}
int main() {
cin >> n >> m;
for (int i = 1; i <= n; i++) {
cin >> a[i];
}
for (int i = 1; i <= n; i++) {
cin >> b[i];
}
for (int i = 1, l, r, x; i <= m; i++) {
cin >> l >> r >> x;
v.push_back({l, r, x, i});
}
S(v, 1, n);
for (int i = 1; i <= m; i++) {
cout << ans[i] << "\n";
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号