centos7 安装hadoop-3.2.1
实验环境

环境准备
1.下载hadoop,官网地址:https://hadoop.apache.org/releases.html
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
2.关闭selinux ,防火墙,hostname,hosts,ntp,配置ssh互信
关闭selinux(4台)
setenforce 0 #临时关闭
cat /etc/selinux/config|grep 'SELINUX=disabled' #永久关闭 SELINUX=disabled
关闭防火墙(4台)
systemctl stop firewalld #关闭防火墙 systemctl disable firewalld #禁止开机启动
修改hostsname (4台)
hostnamectl set-hostname master #其他节点修改成work1~3
添加解析(4台)
[root@master sbin]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 10.23.215.209 master 10.23.215.217 slave1 10.23.215.218 slave2 10.23.215.219 slave3
安装ntp(4台)
[root@master ~]# yum install ntp -y #安装ntp [root@master sbin]# crontab -e #设置同步时间 0 * * * * /usr/sbin/ntpdate cn.pool.ntp.org
设置ssh互信
ssh-keygen #一路回车,生成秘钥
将公钥拷贝到其他worker节点
ssh-copy-id root@worker1 #将公钥拷贝到worker1~3 ssh-copy-id root@worker2 ssh-copy-id root@worker3
hadoop安装
安装java(4台)
tar zxvf jdk-8u231-linux-x64.tar.gz -C /usr/local/
修改/etc/profile 添加java相关信息(4台)
JAVA_HOME=/usr/local/jdk1.8.0_231 JAVA_BIN=/usr/local/jdk1.8.0_231/bin JRE_HOME=/usr/local/jdk1.8.0_231/jre CLASSPATH=/usr/local/jdk1.8.0_231/jre/lib:/usr/local/jdk1.8.0_231/lib:/usr/local/jdk1.8.0_231/jre/lib/charsets.jar PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
更新配置(4台)
source /etc/profile
创建hadoop部署目录
mkdir -p /data/hadoop/{data,tmp,namenode,src}
解压安装hadoop
tar zxvf hadoop-3.2.1.tar.gz -C /data/hadoop/src/
修改hadoop配置信息
cd /data/hadoop/src/hadoop-3.2.1/etc/hadoop vi hadoop-env.sh #添加java_home export JAVA_HOME=/usr/local/jdk1.8.0_231
vi yarn-env.sh export JAVA_HOME=/usr/local/jdk1.8.0_231
vi workers worker1 worker2 worker3
vi core-site.xml <value>hdfs://10.23.215.209:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/data/hadoop/tmp</value> </property> </configuration>
vi hdfs-site.xml <configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/data/hadoop/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/data/hadoop/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>
vi yarn-site.xml <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices. mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8035</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> </configuration>
修改启动脚本 添加如下内容,3.2版本用root用户启动会有报错
cd /data/hadoop/src/hadoop-3.2.1/sbin vi start-dfs.sh HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
vi stop-dfs.sh #!/usr/bin/env bash HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
[root@master sbin]# vi start-yarn.sh #!/usr/bin/env bash YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
vi stop-yarn.sh #!/usr/bin/env bash YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
添加hadoop环境变量
vi /etc/profile HADOOP_HOME=/data/hadoop/src/hadoop-3.2.1/ export PATH=$PATH:$HADOOP_HOME/bin
更新环境变量
source /etc/profile
将hadoop目录拷贝到worker节点上
scp -r /data/hadoop/ root@10.23.215.217:/data scp -r /data/ hadoop/ root@10.23.215.218:/data scp -r /data/hadoop/ root@10.23.215.219:/data
初始化hadoop集群
[root@master /]# hadoop namenode -format WARNING: Use of this script to execute namenode is deprecated. WARNING: Attempting to execute replacement "hdfs namenode" instead. 2020-01-06 15:07:17,864 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = master/10.23.215.209 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 3.2.1 。。。。。。。。 。。。。。。。。 2020-01-06 15:07:18,996 INFO util.GSet: VM type = 64-bit 2020-01-06 15:07:18,997 INFO util.GSet: 0.029999999329447746% max memory 843 MB = 259.0 KB 2020-01-06 15:07:18,997 INFO util.GSet: capacity = 2^15 = 32768 entries 2020-01-06 15:07:19,064 INFO namenode.FSImage: Allocated new BlockPoolId: BP-432712560-10.23.215.209-1578294439046 2020-01-06 15:07:19,085 INFO common.Storage: Storage directory /data/hadoop/namenode has been successfully formatted. 2020-01-06 15:07:19,145 INFO namenode.FSImageFormatProtobuf: Saving image file /data/hadoop/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 2020-01-06 15:07:19,358 INFO namenode.FSImageFormatProtobuf: Image file /data/hadoop/namenode/current/fsimage.ckpt_0000000000000000000 of size 399 bytes saved in 0 seconds . 2020-01-06 15:07:19,374 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2020-01-06 15:07:19,384 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown. 2020-01-06 15:07:19,384 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at master/10.23.215.209 ************************************************************/
启动hadoop集群
[root@master sbin]# /data/hadoop/src/hadoop-3.2.1/sbin/start-all.sh Starting namenodes on [master] Last login: Mon Jan 6 15:15:44 CST 2020 on pts/0 Starting datanodes Last login: Mon Jan 6 15:16:06 CST 2020 on pts/0 Starting secondary namenodes [master] Last login: Mon Jan 6 15:16:08 CST 2020 on pts/0 Starting resourcemanager Last login: Mon Jan 6 15:16:13 CST 2020 on pts/0 Starting nodemanagers Last login: Mon Jan 6 15:16:19 CST 2020 on pts/0
测试集群
#上传一个文件到集群 [root@master package]# ls iftop-0.17.tar.gz [root@master package]# hadoop fs -put iftop-0.17.tar.gz / #上传 2020-01-06 15:17:39,420 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false [root@master package]# [root@master package]# hadoop fs -ls / #查询 Found 1 items -rw-r--r-- 3 root supergroup 160381 2020-01-06 15:17 /iftop-0.17.tar.gz
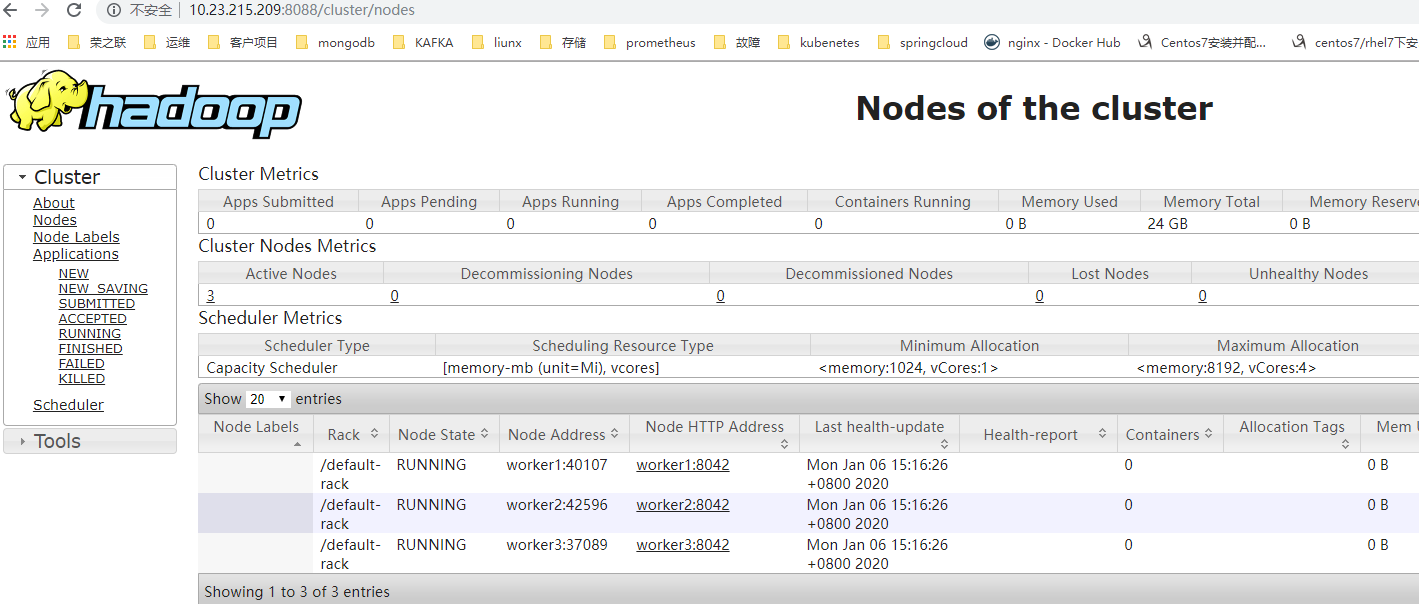
执行hadoop job
cd /data/hadoop/src/hadoop-3.2.1/share/hadoop/mapreduce/ hadoop jar ./hadoop-mapreduce-examples-3.2.1.jar pi 5 10
[root@master mapreduce]# hadoop jar ./hadoop-mapreduce-examples-3.2.1.jar pi 5 10 Number of Maps = 5 Samples per Map = 10 2020-01-06 15:35:58,954 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false Wrote input for Map #0 2020-01-06 15:35:59,228 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false Wrote input for Map #1 2020-01-06 15:35:59,277 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false Wrote input for Map #2 2020-01-06 15:35:59,323 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false Wrote input for Map #3 2020-01-06 15:35:59,377 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false Wrote input for Map #4 .............. .............. .............. 2020-01-06 15:36:02,811 INFO mapreduce.Job: Counters: 36 File System Counters FILE: Number of bytes read=1914940 FILE: Number of bytes written=5034452 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=2360 HDFS: Number of bytes written=3755 HDFS: Number of read operations=89 HDFS: Number of large read operations=0 HDFS: Number of write operations=45 HDFS: Number of bytes read erasure-coded=0 Map-Reduce Framework Map input records=5 Map output records=10 Map output bytes=90 Map output materialized bytes=140 Input split bytes=745 Combine input records=0 Combine output records=0 Reduce input groups=2 Reduce shuffle bytes=140 Reduce input records=10 Reduce output records=0 Spilled Records=20 Shuffled Maps =5 Failed Shuffles=0 Merged Map outputs=5 GC time elapsed (ms)=15 Total committed heap usage (bytes)=3067084800 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=590 File Output Format Counters Bytes Written=97 Job Finished in 3.401 seconds Estimated value of Pi is 3.28000000000000000000

 浙公网安备 33010602011771号
浙公网安备 33010602011771号