python将pdf文件转word
pdf转word
前言
今天有朋友让我帮忙将pdf转为word,我首先想到的就是python,经过一顿搜索,最终决定采用pdf2docx的方案,然而实际操作的时候踩了坑,所以就先找了在线工具给搞了,但是我是一个有坑必填(有征服欲🤪)的coder,于是在帮完朋友的忙之后,又去捣鼓pdf2docx这个工具,当然最后顺利填坑,解决了问题,下面让我们一起来看看吧。
pdf2docx
pdf2docx是一个开源的三方库,它可以将pdf文件转为word,目前仅支持文字版的pdf,扫描版的pdf转了之后依然还是图片。
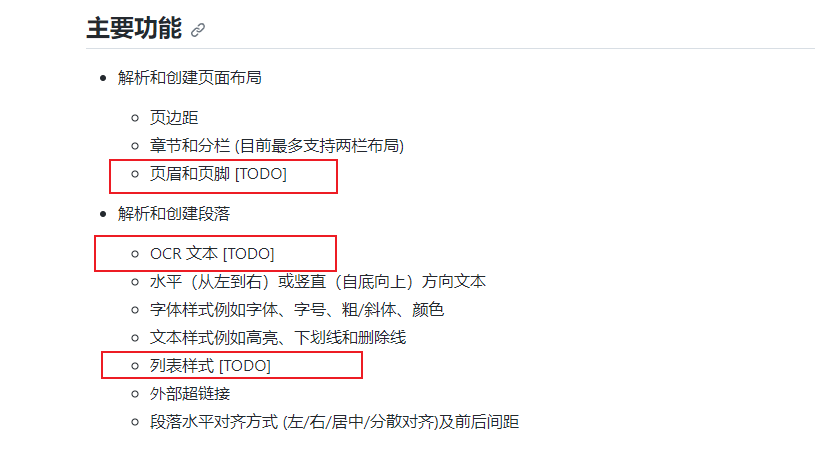
环境准备
安装pdf20docx
pip install pdf2docx -i https://pypi.tuna.tsinghua.edu.cn/simple
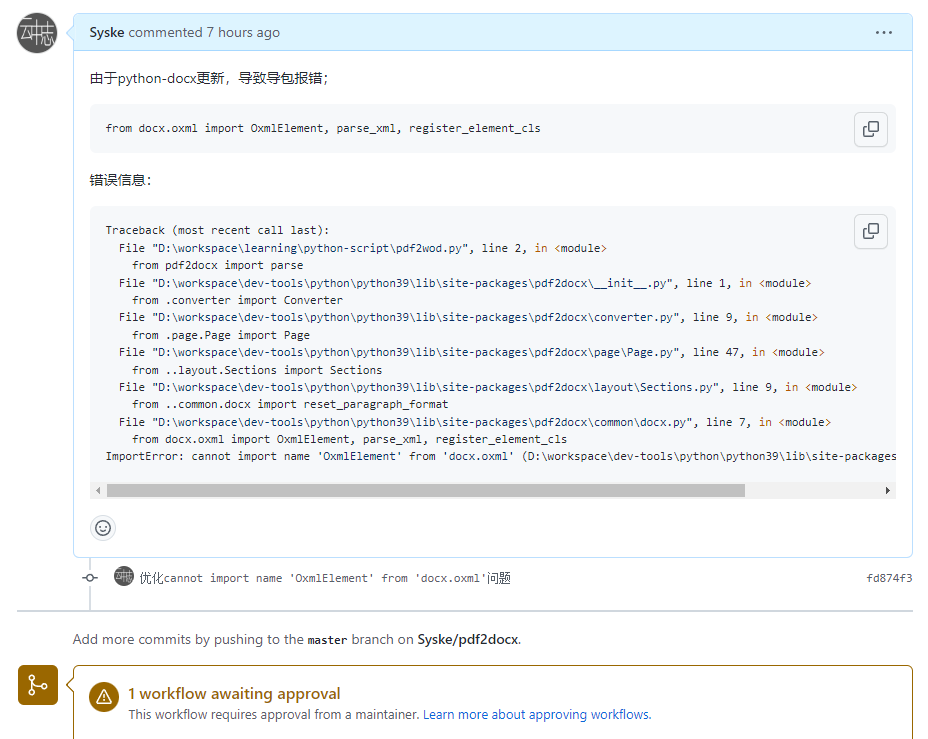
这里有个坑,pdf2docx依赖了python-docx,然鹅,最新的python-docx的包路径发生了变化,导致在pdf2docx导包时会报错:
Traceback (most recent call last):
File "D:\workspace\learning\python-script\pdf2wod.py", line 2, in <module>
from pdf2docx import parse
File "D:\workspace\dev-tools\python\python39\lib\site-packages\pdf2docx\__init__.py", line 1, in <module>
from .converter import Converter
File "D:\workspace\dev-tools\python\python39\lib\site-packages\pdf2docx\converter.py", line 9, in <module>
from .page.Page import Page
File "D:\workspace\dev-tools\python\python39\lib\site-packages\pdf2docx\page\Page.py", line 47, in <module>
from ..layout.Sections import Sections
File "D:\workspace\dev-tools\python\python39\lib\site-packages\pdf2docx\layout\Sections.py", line 9, in <module>
from ..common.docx import reset_paragraph_format
File "D:\workspace\dev-tools\python\python39\lib\site-packages\pdf2docx\common\docx.py", line 7, in <module>
from docx.oxml import OxmlElement, parse_xml, register_element_cls
ImportError: cannot import name 'OxmlElement' from 'docx.oxml' (D:\workspace\dev-tools\python\python39\lib\site-packages\docx\oxml\__init__.py)
报错截图:

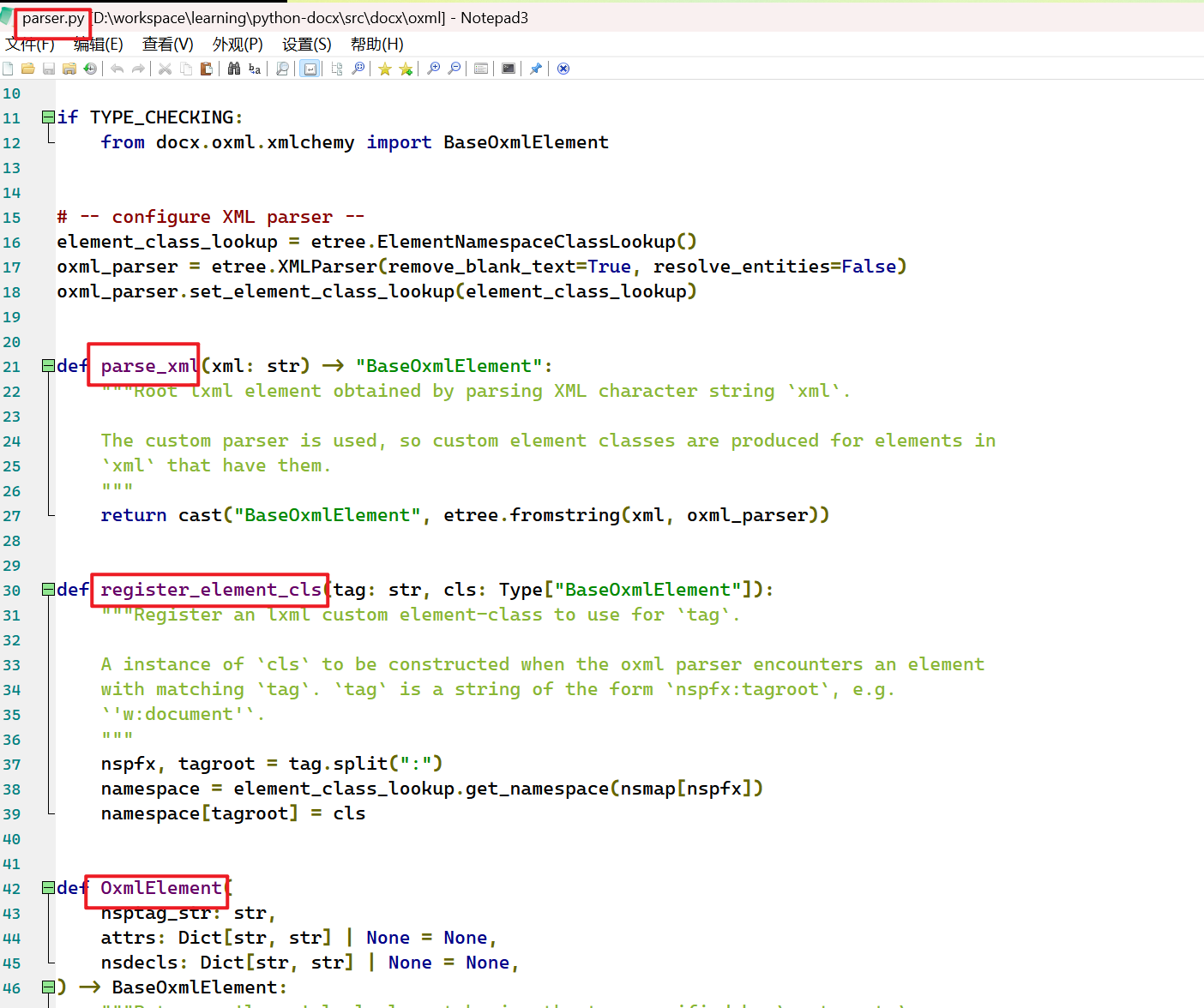
最终解决方法时,修改报错文件的源码:


搜了很多文档都么解决问题,最终我还专门下载了python-docx的源码,然后很幸运地找到了问题:

我也给pdf2docx提了pr,不知道是否会被通过合并:
编写代码
# 导入pdf2docx模块
from pdf2docx import parse
pdf_file = 'myfile.pdf'
docx_file = 'myfile.docx'
# convert pdf to docx
parse(pdf_file, docx_file)
经过测试,效果还不错:

刚开始我以为扫描的pdf也可以转,控制台的警告是不是忘改了,文档可能也没更新
转word之后的效果看着效果还不错,然而当我把修改word文件的时候,发现这个pdf每个文字都是个小图片,怪不得标点符号看着这么奇怪:

而且扫描的pdf转word会比较慢
结语
今天的内容没有什么好总结的,下面我分享一些比较常用的python代码:
pdf文件合并:
需要安装PyPDF2库
import PyPDF2
local = './'
pdf_files = ['1.pdf', '2.pdf']
output_pdf = PyPDF2.PdfWriter()
for pdf_file in pdf_files:
# 循环读取需要合并pdf文件
with open(local+pdf_file, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
# 遍历每个pdf的每一页
for page_num in range(len(pdf_reader.pages)):
page = pdf_reader.pages[page_num]
if pdf_file == '1.pdf':
# 旋转90度
page.rotate(90)
output_pdf.add_page(page)
with open(local+'装修图2.pdf', 'wb') as file:
output_pdf.write(file)
pdf转图片,每页一个图片
需要安装pymupdf库
# coding=utf-8
#安装库 pip install pymupdf
import fitz
import os
def convert_pdf2img(file_relative_path):
"""
file_relative_path : 文件相对路径
"""
page_num = 1
filename = file_relative_path.split('.')[-2]
if not os.path.exists(filename):
os.makedirs(filename)
pdf = fitz.open(file_relative_path)
for page in pdf:
rotate = int(0)
# 每个尺寸的缩放系数为2,这将为我们生成分辨率提高4的图像。
# 此处若是不做设置,默认图片大小为:792X612, dpi=96
zoom_x = 2 # (2-->1584x1224)
zoom_y = 2
mat = fitz.Matrix(zoom_x, zoom_y)
pixmap = page.get_pixmap(matrix=mat, alpha=False)
pixmap.pil_save(f"{filename}/{page_num}.png")
print(f"{filename}.pdf 第{page_num}页保存图片完成")
page_num = page_num + 1
if __name__ =="__main__":
# 文件夹中文件名
file_list = os.listdir('./')
for file in file_list:
#print(file)
if os.path.isfile(file) and file.endswith('.pdf'):
convert_pdf2img(file)
csv转excel
需要安装openpyxl库
import os, csv, sys, openpyxl
from openpyxl import load_workbook
from openpyxl import Workbook
from openpyxl.utils import get_column_letter
#Open an xlsx for reading
wb = load_workbook('Test.xlsx')
ws = wb.get_sheet_by_name("Sheet1")
dest_filename = "Test_NEW.xlsx"
csv_filename = "hsay_20221104.csv"
#Copy in csv
f = open(csv_filename, encoding='utf-8')
reader = csv.reader(f)
for row_index, row in enumerate(reader):
for column_index, cell in enumerate(row):
column_letter = get_column_letter((column_index + 1))
ws.cell(row_index + 1, (column_index + 1)).value = cell
print(f'line:{row_index+1}')
wb.save(filename = dest_filename)
print("new Cashflow created")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号