动手学深度学习:机器翻译
《动手学深度学习》的最后一篇文章,在这篇文章里,将学习什么是编码器解码器的结构,什么是束搜索,以及注意力机制是什么,最后就是仔细地研究一下课本中最后一个机器翻译的代码实例,来综合运用上述的编码器-解码器和注意力机制!
1、编码器—解码器(seq2seq)
在自然语言处理的很多应用中,输入和输出都可以是不定长序列。以机器翻译为例,输入可以是一段不定长的英语文本序列,输出可以是一段不定长的法语文本序列,例如
- 英语输入:“They”、“are”、“watching”、“.”
- 法语输出:“Ils”、“regardent”、“.”
当输入和输出都是不定长序列时,我们可以使用编码器—解码器(encoder-decoder)或者seq2seq模型。
这两个模型本质上都用到了两个循环神经网络,分别叫做编码器和解码器。
📣编码器用来分析输入序列,解码器用来生成输出序列。
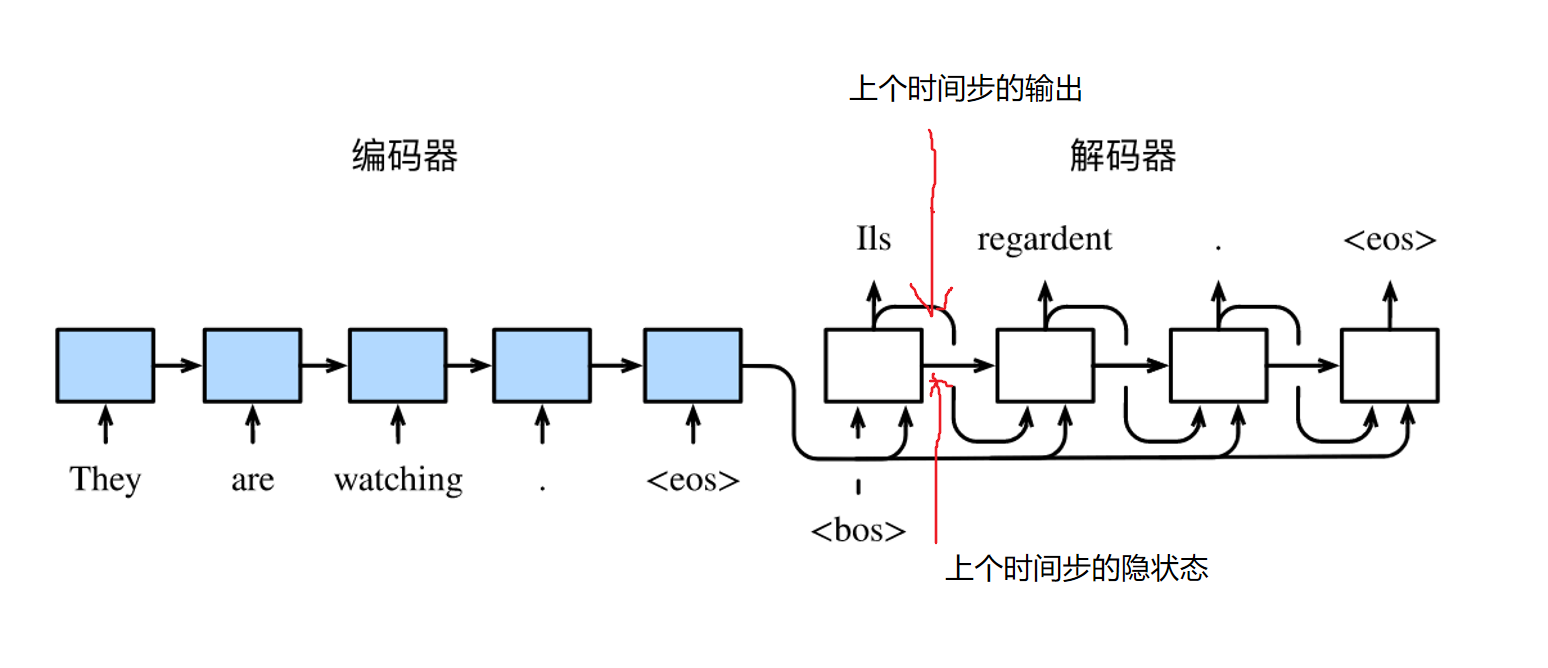
图中为使用编码器—解码器将句子由英语翻译成法语。编码器和解码器分别为循环神经网络的图解。
一言以蔽之:
-
Encoder:用来把你输入的序列进行编码表征,抽取出输入数据的特征,比如说背景变量c,以及各个隐状态
-
Decoder:把encoder编码得到的特征(背景变量,所有时间步的隐状态)作为输入的一部分,并根据这个特征表达+decoder自己部分的输入,来预测你想要的东西
-
在编码器—解码器的训练中,可以采用强制教学。
- 强制教学?
- 就是把无论Decoder的t-1时间步的预测是什么,正确与否,下一时间步t,都把t-1步正确的标签当作输入啦。
强制把正确答案给你学习
具体的encoder和decoder部分将在最后的机器翻译代码中看到。
2、束搜索
2.2 贪婪搜索
在学习束搜索之前,先看看什么是贪婪搜索:
说起贪婪二字,什么是贪婪?即每一步都只选择当下最优的选择...
哈哈哈,是的,这个算法的缺点就是,有时候只顾眼前最优,最后的结果却不一定是最好的喔。
没有什么是一个例子解决不了的:
假设输出词典里面有“A”“B”“C”和“<eos>”这4个词。
图10.9中每个时间步下的4个数字分别代表了该时间步生成“A”“B”“C”和“<eos>”这4个词的条件概率。
在每个时间步,贪婪搜索选取条件概率最大的词。因此,图10.9中将生成输出序列“A”“B”“C”“<eos>”。
该输出序列的条件概率是0.5×0.4×0.4×0.6=0.048。

2.2 穷举搜索
暴力解法,emm,只要你算力足够,没有什么是穷举算法不能解决的啦。
穷举搜索:穷举所有可能的输出序列,输出条件概率最大的序列。
虽然穷举搜索可以得到最优输出序列,但它的计算开销很容易过大
2.3 束搜索
束搜索(beam search 是对贪婪搜索的一个改进算法。
-
它有一个束宽(beam size)超参数。我们将它设为k。
-
在时间步1时,选取当前时间步条件概率最大的k个词,分别组成k个候选输出序列的首词。
-
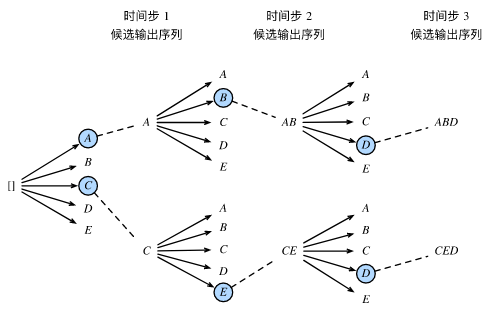
在之后的每个时间步,基于上个时间步的kk个候选输出序列,从k∣Y∣(|Y|代表词典大小)个可能的输出序列中选取条件概率最大的k个,作为该时间步的候选输出序列。
-
最终,我们从各个时间步的候选输出序列中筛选出包含特殊符号“
”的序列,并将它们中所有特殊符号“ ”后面的子序列舍弃,得到最终候选输出序列的集合。
下图很清楚的可以看出:当k=2时,束搜索的一个过程~
需要特别注意:时间步2以及后面的时间步的候选序列,是从计算出的10个条件概率中取最大的2个!!
3、注意力机制
先拿咱们人来说,
人也有注意力机制,其实就是让你在某一时刻将注意力放到某些事物上,而忽略另外的一些事物,这就是注意力机制(Attention Mechanism)。
在深度学习领域,模型往往需要接收和处理大量的数据,然而在特定的某个时刻,往往只有少部分的某些数据是重要的,这种情况就非常适合Attention机制发光发热。
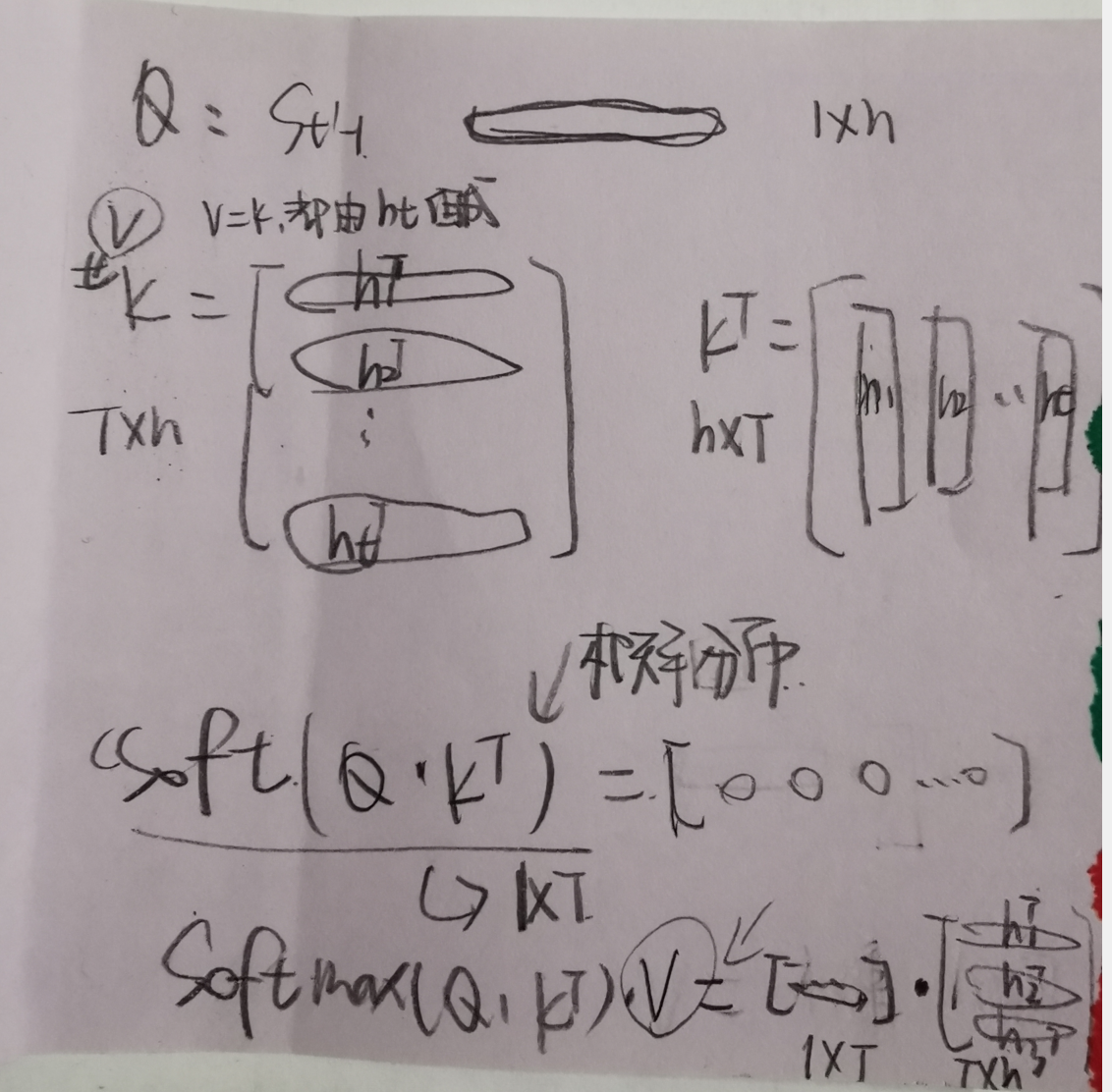
注意力机制,可以在解码器的每个时间步使用不同的背景变量 ,并对输入序列中不同时间步编码的信息分配不同的注意力。

4、机器翻译
机器翻译是指将一段文本从一种语言自动翻译到另一种语言。因为一段文本序列在不同语言中的长度不一定相同,
下面以机器翻译为例来学习编码器—解码器和注意力机制的应用!
需要代码的UU可以戳下面:
ps:只要把数据集的路径改成你自己的路径,就可以完美运行!
点击查看代码
import collections
import os
import io
import math
import torch
from torch import nn
import torch.nn.functional as F
import torchtext.vocab as Vocab
import torch.utils.data as Data
import sys
sys.path.append("..")
from d2l import torch as d2l
PAD, BOS, EOS = '<pad>', '<bos>', '<eos>'
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 将一个序列中所有的词记录在all_tokens中以便之后构造词典,然后在该序列后面添加PAD直到序列
# 长度变为max_seq_len,然后将序列保存在all_seqs中
def process_one_seq(seq_tokens, all_tokens, all_seqs, max_seq_len):
all_tokens.extend(seq_tokens)
seq_tokens += [EOS] + [PAD] * (max_seq_len - len(seq_tokens) - 1)
all_seqs.append(seq_tokens)
# 使用所有的词来构造词典。并将所有序列中的词变换为词索引后构造Tensor
def build_data(all_tokens, all_seqs):
counter = collections.Counter(all_tokens)
counter['PAD']=1
counter['BOS']=1
counter['EOS']=1
vocab = Vocab.Vocab(counter)
indices = [[vocab.__getitem__(w) for w in seq] for seq in all_seqs]
return vocab, torch.tensor(indices)
def read_data(max_seq_len):
# in和out分别是input和output的缩写
in_tokens, out_tokens, in_seqs, out_seqs = [], [], [], []
with io.open(r'D:\DataSet\data\fr-en-small.txt') as f:
lines = f.readlines()
for line in lines:
in_seq, out_seq = line.rstrip().split('\t')
in_seq_tokens, out_seq_tokens = in_seq.split(' '), out_seq.split(' ')
if max(len(in_seq_tokens), len(out_seq_tokens)) > max_seq_len - 1:
continue # 如果加上EOS后长于max_seq_len,则忽略掉此样本
process_one_seq(in_seq_tokens, in_tokens, in_seqs, max_seq_len)
process_one_seq(out_seq_tokens, out_tokens, out_seqs, max_seq_len)
in_vocab, in_data = build_data(in_tokens, in_seqs)
out_vocab, out_data = build_data(out_tokens, out_seqs)
return in_vocab, out_vocab, Data.TensorDataset(in_data, out_data)
max_seq_len = 7
in_vocab, out_vocab, dataset = read_data(max_seq_len)
class Encoder(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
drop_prob=0, **kwargs):
super(Encoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=drop_prob)
def forward(self, inputs, state):
# 输入形状是(批量大小, 时间步数)。将输出互换样本维和时间步维
embedding = self.embedding(inputs.long()).permute(1, 0, 2) # (seq_len, batch, input_size)
return self.rnn(embedding, state)
def begin_state(self):
return None # 隐藏态初始化为None时PyTorch会自动初始化为0
def attention_model(input_size, attention_size):
model = nn.Sequential(nn.Linear(input_size,
attention_size, bias=False),
nn.Tanh(),
nn.Linear(attention_size, 1, bias=False))
return model
def attention_forward(model, enc_states, dec_state):
"""
enc_states: (时间步数, 批量大小, 隐藏单元个数)
dec_state: (批量大小, 隐藏单元个数)
"""
# 将解码器隐藏状态广播到和编码器隐藏状态形状相同后进行连结
dec_states = dec_state.unsqueeze(dim=0).expand_as(enc_states)
enc_and_dec_states = torch.cat((enc_states, dec_states), dim=2)
e = model(enc_and_dec_states) # 形状为(时间步数, 批量大小, 1)
alpha = F.softmax(e, dim=0) # 在时间步维度做softmax运算
return (alpha * enc_states).sum(dim=0) # 返回背景变量
class Decoder(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
attention_size, drop_prob=0):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.attention = attention_model(2*num_hiddens, attention_size)
# GRU的输入包含attention输出的c和实际输入, 所以尺寸是 num_hiddens+embed_size
self.rnn = nn.GRU(num_hiddens + embed_size, num_hiddens,
num_layers, dropout=drop_prob)
self.out = nn.Linear(num_hiddens, vocab_size)
def forward(self, cur_input, state, enc_states):
"""
cur_input shape: (batch, )
state shape: (num_layers, batch, num_hiddens)
"""
# 使用注意力机制计算背景向量
c = attention_forward(self.attention, enc_states, state[-1])
# 将嵌入后的输入和背景向量在特征维连结, (批量大小, num_hiddens+embed_size)
input_and_c = torch.cat((self.embedding(cur_input), c), dim=1)
# 为输入和背景向量的连结增加时间步维,时间步个数为1
output, state = self.rnn(input_and_c.unsqueeze(0), state)
# 移除时间步维,输出形状为(批量大小, 输出词典大小)
output = self.out(output).squeeze(dim=0)
return output, state
def begin_state(self, enc_state):
# 直接将编码器最终时间步的隐藏状态作为解码器的初始隐藏状态
return enc_state
def batch_loss(encoder, decoder, X, Y, loss):
batch_size = X.shape[0]
enc_state = encoder.begin_state()
enc_outputs, enc_state = encoder(X, enc_state)
# 初始化解码器的隐藏状态
dec_state = decoder.begin_state(enc_state)
# 解码器在最初时间步的输入是BOS
dec_input = torch.tensor([out_vocab.__getitem__(BOS)] * batch_size)
# 我们将使用掩码变量mask来忽略掉标签为填充项PAD的损失
mask, num_not_pad_tokens = torch.ones(batch_size,), 0
l = torch.tensor([0.0])
for y in Y.permute(1,0): # Y shape: (batch, seq_len)
dec_output, dec_state = decoder(dec_input, dec_state, enc_outputs)
l = l + (mask * loss(dec_output, y)).sum()
dec_input = y # 使用强制教学
num_not_pad_tokens += mask.sum().item()
# EOS后面全是PAD. 下面一行保证一旦遇到EOS接下来的循环中mask就一直是0
mask = mask * (y != out_vocab.__getitem__(EOS)).float()
return l / num_not_pad_tokens
def train(encoder, decoder, dataset, lr, batch_size, num_epochs):
enc_optimizer = torch.optim.Adam(encoder.parameters(), lr=lr)
dec_optimizer = torch.optim.Adam(decoder.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction='none')
data_iter = Data.DataLoader(dataset, batch_size, shuffle=True)
for epoch in range(num_epochs):
l_sum = 0.0
for X, Y in data_iter:
enc_optimizer.zero_grad()
dec_optimizer.zero_grad()
l = batch_loss(encoder, decoder, X, Y, loss)
l.backward()
enc_optimizer.step()
dec_optimizer.step()
l_sum += l.item()
if (epoch + 1) % 10 == 0:
print("epoch %d, loss %.3f" % (epoch + 1, l_sum / len(data_iter)))
embed_size, num_hiddens, num_layers = 64, 64, 2
attention_size, drop_prob, lr, batch_size, num_epochs = 10, 0.5, 0.01, 2, 50
encoder = Encoder(len(in_vocab), embed_size, num_hiddens, num_layers,
drop_prob)
decoder = Decoder(len(out_vocab), embed_size, num_hiddens, num_layers,
attention_size, drop_prob)
train(encoder, decoder, dataset, lr, batch_size, num_epochs)
好啦下面正式开始学习:
读取和预处理数据
为了便于理解,在读代码的时候尽量给每一行都写了注释~~~
# 将一个序列中所有的词记录在all_tokens中以便之后构造词典,然后在该序列后面添加PAD直到序列
# 长度变为max_seq_len,然后将序列保存在all_seqs中
def process_one_seq(seq_tokens, all_tokens, all_seqs, max_seq_len):
all_tokens.extend(seq_tokens) #extend,在原来的数组上一次性追加多个值
seq_tokens += [EOS] + [PAD] * (max_seq_len - len(seq_tokens) - 1) #有些句子不够长,填充上‘PAD’
all_seqs.append(seq_tokens) #all_seqs存了所有的句子(已分词)
# 使用所有的词来构造词典。并将所有序列中的词变换为词索引后构造Tensor
def build_data(all_tokens, all_seqs):
counter = collections.Counter(all_tokens)
counter['PAD']=1
counter['BOS']=1
counter['EOS']=1
vocab = Vocab.Vocab(counter) #构造词典
indices = [[vocab.__getitem__(w) for w in seq] for seq in all_seqs] #把句子序列的汉字,转换成索引
return vocab, torch.tensor(indices)
def read_data(max_seq_len):
# in和out分别是input和output的缩写
in_tokens, out_tokens, in_seqs, out_seqs = [], [], [], []
with io.open(r'D:\DataSet\data\fr-en-small.txt') as f:
lines = f.readlines()
for line in lines:
in_seq, out_seq = line.rstrip().split('\t') #rstrip()对字符串处理,去除开端和结尾的\t或者\n
in_seq_tokens, out_seq_tokens = in_seq.split(' '), out_seq.split(' ') #把每一行读出的句子,按照空格进行分词
if max(len(in_seq_tokens), len(out_seq_tokens)) > max_seq_len - 1:
continue # 如果加上EOS后长于max_seq_len,则忽略掉此样本
process_one_seq(in_seq_tokens, in_tokens, in_seqs, max_seq_len) #调用函数,通过tokens序列,获得所有的tokens,和填充好的tokens序列
process_one_seq(out_seq_tokens, out_tokens, out_seqs, max_seq_len)
in_vocab, in_data = build_data(in_tokens, in_seqs) #获得词典
out_vocab, out_data = build_data(out_tokens, out_seqs)
return in_vocab, out_vocab, Data.TensorDataset(in_data, out_data) #返回词典,返回数据集,Data.TensorDataset把两个list一一配对打包,以元组list的形式返回
max_seq_len = 7
in_vocab, out_vocab, dataset = read_data(max_seq_len)
:meta:
ps:bug来了
书中代码在运行这段的时候会报错:
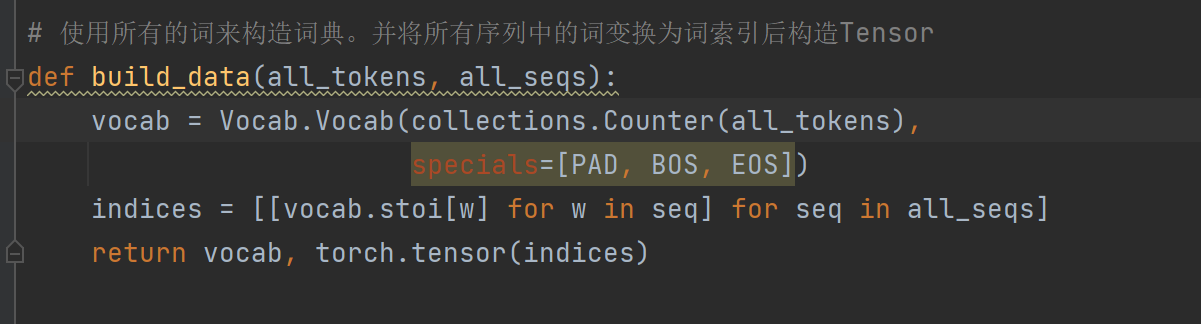
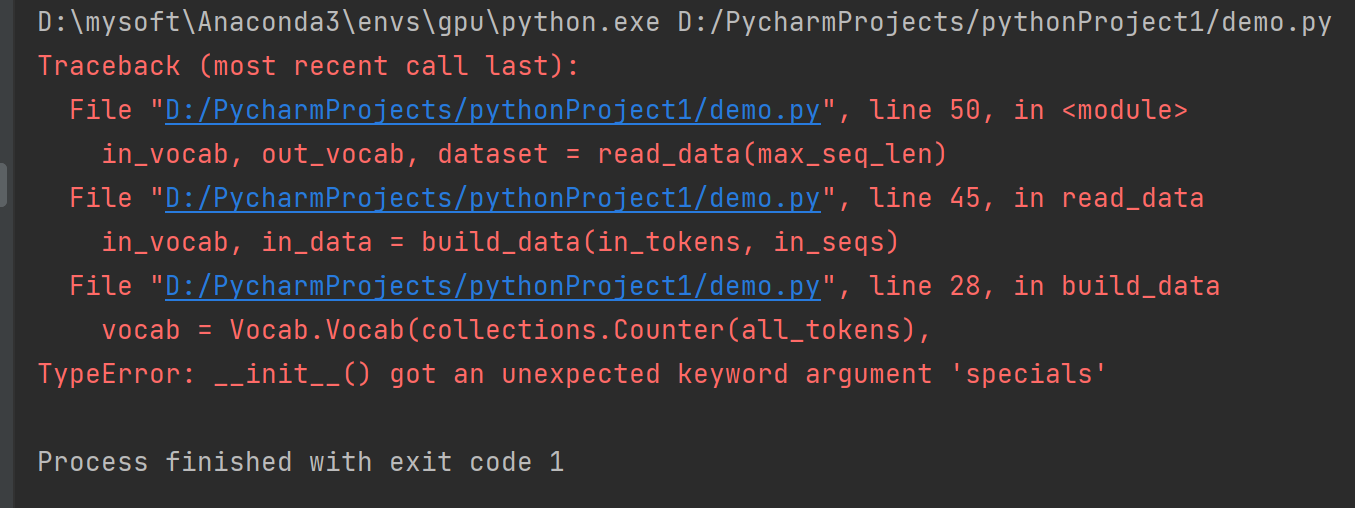
原因:版本问题,我的版本太新了,新版本Vocab没有这个specials参数啊
emm,这个参数的作用是为了把自己填充的三个词‘PAD’,‘EOS’,'BOS'加到词典里去,竟然新版没有这个specials参数,那我就自己手动添加。。。
把代码简单粗暴地改成这个就行啦。
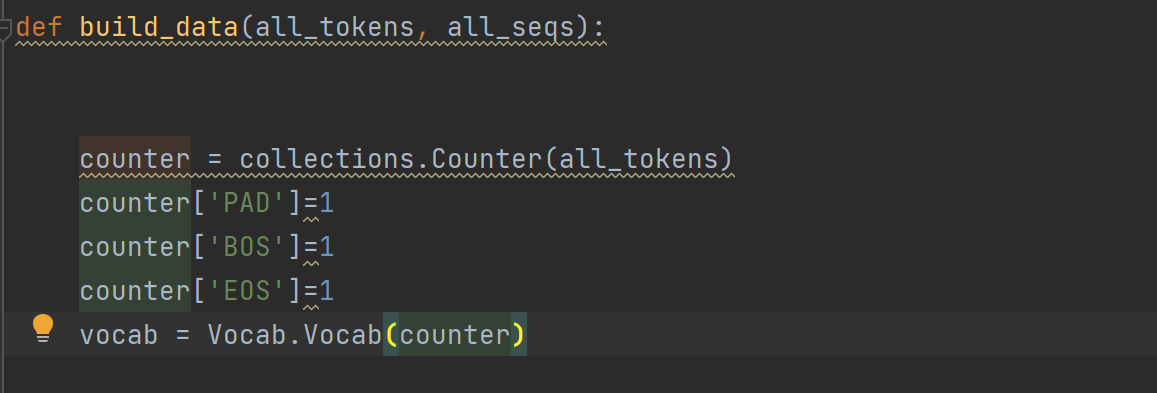
----------------------------------------------------------------------------------手动分割--------------------------------------------------
还有!!!!

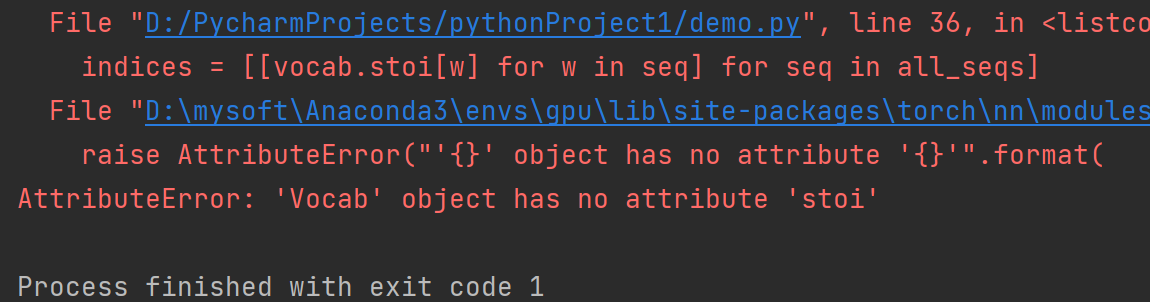
原因:版本问题,新版本吧,它没有Vocab.stoi()这个方法啊
于是百度,遂解决:


4.1 含注意力机制的编码器—解码器
Encoder
在编码器中,我们将输入语言的词索引通过词嵌入层得到词的表征,然后输入到一个多层门控循环单元中。
class Encoder(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
drop_prob=0, **kwargs):
super(Encoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=drop_prob)
def forward(self, inputs, state):
# 输入形状是(批量大小, 时间步数)。将输出互换样本维和时间步维
embedding = self.embedding(inputs.long()).permute(1, 0, 2) # (seq_len, batch, input_size)
return self.rnn(embedding, state)
def begin_state(self):
return None # 隐藏态初始化为None时PyTorch会自动初始化为0
这一段就是一个嵌入层+一个GRU层
注意力机制
def attention_model(input_size, attention_size):
model = nn.Sequential(nn.Linear(input_size,
attention_size, bias=False),
nn.Tanh(),
nn.Linear(attention_size, 1, bias=False))
return model
def attention_forward(model, enc_states, dec_state):
"""
enc_states: (时间步数, 批量大小, 隐藏单元个数)
dec_state: (批量大小, 隐藏单元个数)
"""
# 将解码器隐藏状态广播到和编码器隐藏状态形状相同后进行连结
dec_states = dec_state.unsqueeze(dim=0).expand_as(enc_states)
enc_and_dec_states = torch.cat((enc_states, dec_states), dim=2)
e = model(enc_and_dec_states) # 形状为(时间步数, 批量大小, 1)
alpha = F.softmax(e, dim=0) # 在时间步维度做softmax运算
return (alpha * enc_states).sum(dim=0) # 返回背景变量
含注意力机制的解码器
由于解码器的输入来自输出语言的词索引,我们将输入通过词嵌入层得到表征,然后和背景向量在特征维连结。
我们将连结后的结果与上一时间步的隐藏状态通过门控循环单元计算出当前时间步的输出与隐藏状态。
最后,我们将输出通过全连接层变换为有关各个输出词的预测,形状为(批量大小, 输出词典大小)。
class Decoder(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
attention_size, drop_prob=0):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.attention = attention_model(2*num_hiddens, attention_size)
# GRU的输入包含attention输出的c和实际输入, 所以尺寸是 num_hiddens+embed_size
self.rnn = nn.GRU(num_hiddens + embed_size, num_hiddens,
num_layers, dropout=drop_prob)
self.out = nn.Linear(num_hiddens, vocab_size)
def forward(self, cur_input, state, enc_states):
"""
cur_input shape: (batch, )
state shape: (num_layers, batch, num_hiddens)
"""
# 使用注意力机制计算背景向量
c = attention_forward(self.attention, enc_states, state[-1])
# 将嵌入后的输入和背景向量在特征维连结, (批量大小, num_hiddens+embed_size)
input_and_c = torch.cat((self.embedding(cur_input), c), dim=1)
# 为输入和背景向量的连结增加时间步维,时间步个数为1
output, state = self.rnn(input_and_c.unsqueeze(0), state)
# 移除时间步维,输出形状为(批量大小, 输出词典大小)
output = self.out(output).squeeze(dim=0)
return output, state
def begin_state(self, enc_state):
# 直接将编码器最终时间步的隐藏状态作为解码器的初始隐藏状态
return enc_state
4.2训练模型
解码器在最初时间步的输入是特殊字符BOS。之后,解码器在某时间步的输入为样本输出序列在上一时间步的词,即强制教学。
def batch_loss(encoder, decoder, X, Y, loss):
batch_size = X.shape[0]
enc_state = encoder.begin_state()
enc_outputs, enc_state = encoder(X, enc_state)
# 初始化解码器的隐藏状态
dec_state = decoder.begin_state(enc_state)
# 解码器在最初时间步的输入是BOS
dec_input = torch.tensor([out_vocab.stoi[BOS]] * batch_size)
# 我们将使用掩码变量mask来忽略掉标签为填充项PAD的损失
mask, num_not_pad_tokens = torch.ones(batch_size,), 0
l = torch.tensor([0.0])
for y in Y.permute(1,0): # Y shape: (batch, seq_len)
dec_output, dec_state = decoder(dec_input, dec_state, enc_outputs)
l = l + (mask * loss(dec_output, y)).sum()
dec_input = y # 使用强制教学
num_not_pad_tokens += mask.sum().item()
# EOS后面全是PAD. 下面一行保证一旦遇到EOS接下来的循环中mask就一直是0
mask = mask * (y != out_vocab.stoi[EOS]).float()
return l / num_not_pad_tokens
def train(encoder, decoder, dataset, lr, batch_size, num_epochs):
enc_optimizer = torch.optim.Adam(encoder.parameters(), lr=lr)
dec_optimizer = torch.optim.Adam(decoder.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction='none')
data_iter = Data.DataLoader(dataset, batch_size, shuffle=True)
for epoch in range(num_epochs):
l_sum = 0.0
for X, Y in data_iter:
enc_optimizer.zero_grad()
dec_optimizer.zero_grad()
l = batch_loss(encoder, decoder, X, Y, loss)
l.backward()
enc_optimizer.step()
dec_optimizer.step()
l_sum += l.item()
if (epoch + 1) % 10 == 0:
print("epoch %d, loss %.3f" % (epoch + 1, l_sum / len(data_iter)))
好啦~~~这就是所有的核心模块!!!
来看看运行结果吧
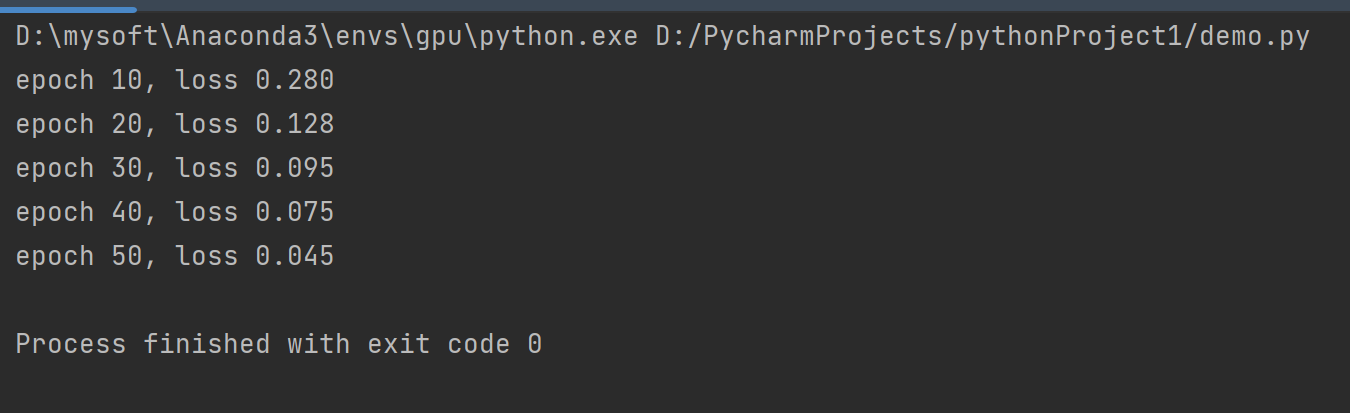
5、尾声
《动手学》这本书终于接近尾声了,不得不说,这真是一本好书。。。每一个入门者都可以在里面学到好得多!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号