深度学习:计算机视觉
1、图像增广
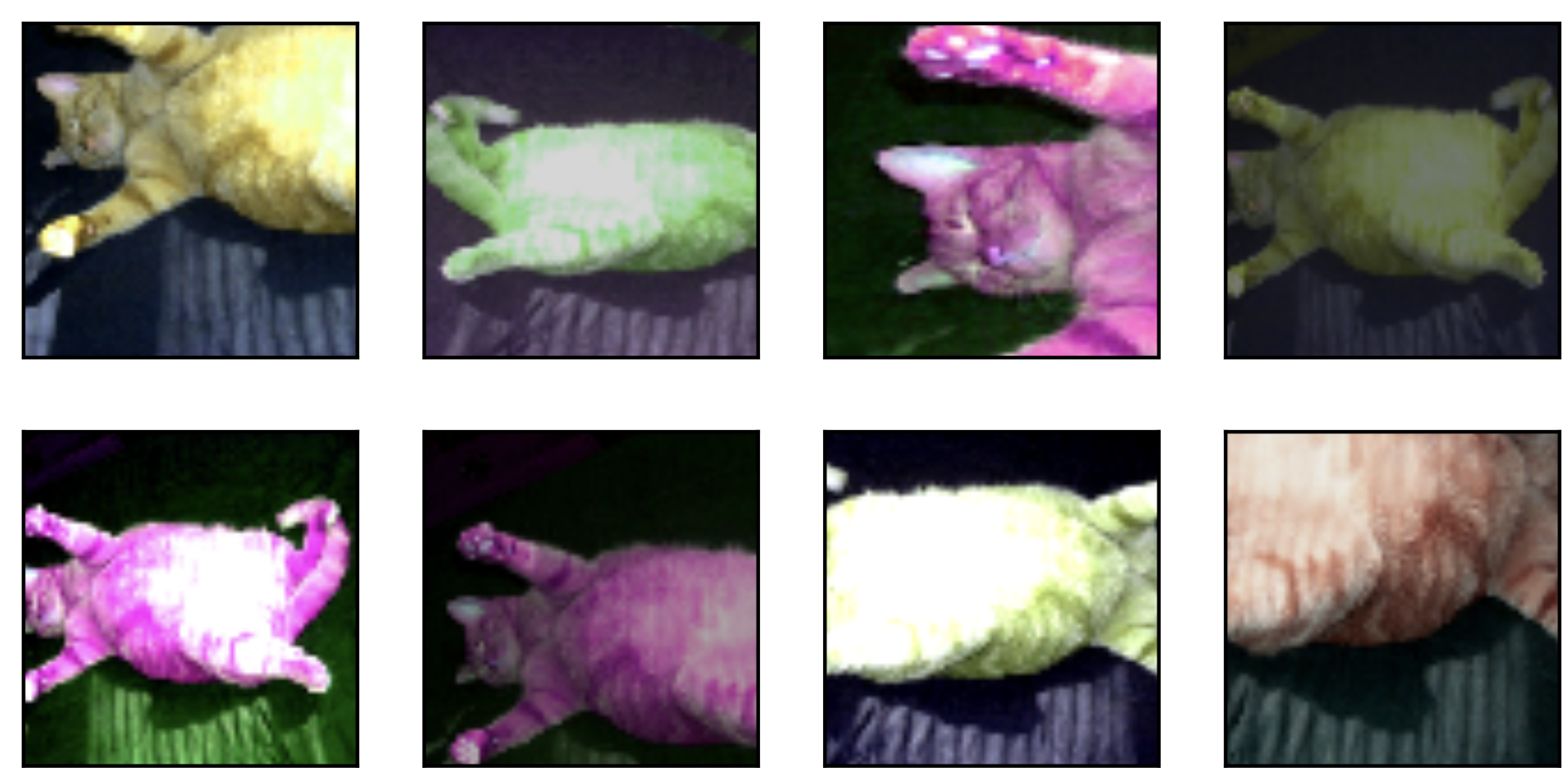
图像增广(image augmentation)技术通过对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模。
图像增广的另一种解释是,随机改变训练样本可以降低模型对某些属性的依赖,从而提高模型的泛化能力。
例如,我们可以对图像进行不同方式的裁剪,使感兴趣的物体出现在不同位置,从而减轻模型对物体出现位置的依赖性。我们也可以调整亮度、色彩等因素来降低模型对色彩的敏感度。
!!!为了在预测时得到确定的结果,我们通常只将图像增广应用在训练样本上,而不在预测时使用含随机操作的图像增广。
增广前:

增广后:
2、目标检测和边界框
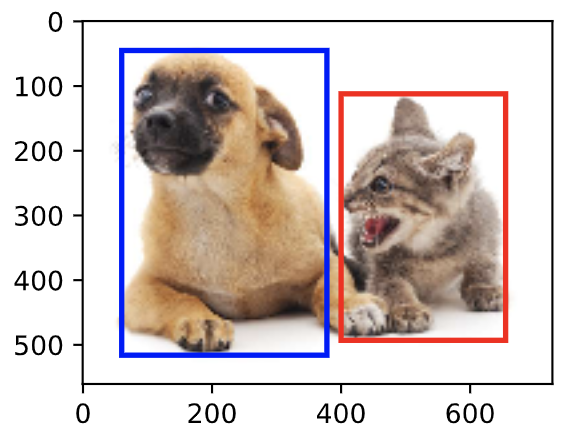
图像分类任务里,我们假设图像里只有一个主体目标,并关注如何识别该目标的类别。然而,很多时候图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。在计算机视觉里,我们将这类任务称为目标检测(object detection)或物体检测。
边界框是一个矩形框,可以由矩形左上角的xx和yy轴坐标与右下角的xx和yy轴坐标确定。
3、锚框
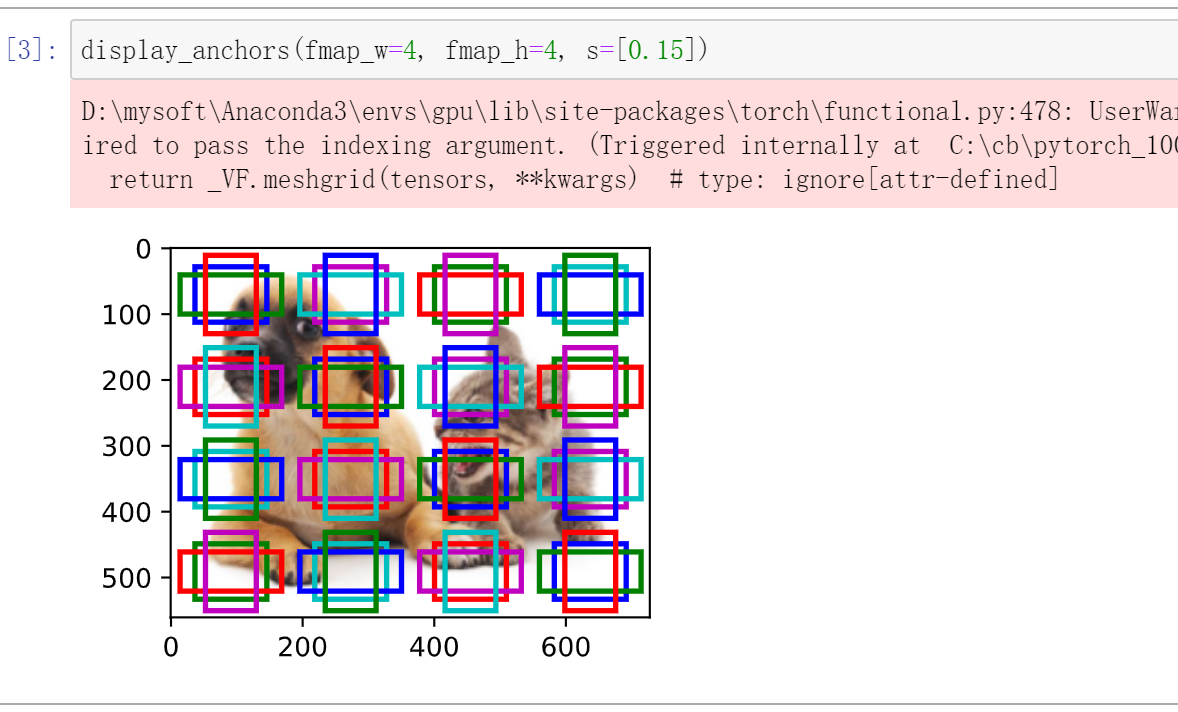
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边缘从而更准确地预测目标的真实边界框(ground-truth bounding box)。不同的模型使用的区域采样方法可能不同。这里我们介绍其中的一种方法:它以每个像素为中心生成多个大小和宽高比(aspect ratio)不同的边界框。这些边界框被称为锚框(anchor box)。
- 以每个像素为中心,生成多个大小和宽高比不同的锚框。
- 交并比是两个边界框相交面积与相并面积之比。
- 在训练集中,为每个锚框标注两类标签:一是锚框所含目标的类别;二是真实边界框相对锚框的偏移量。
- 预测时,可以使用非极大值抑制来移除相似的预测边界框,从而令结果简洁。
4、多尺度目标检测
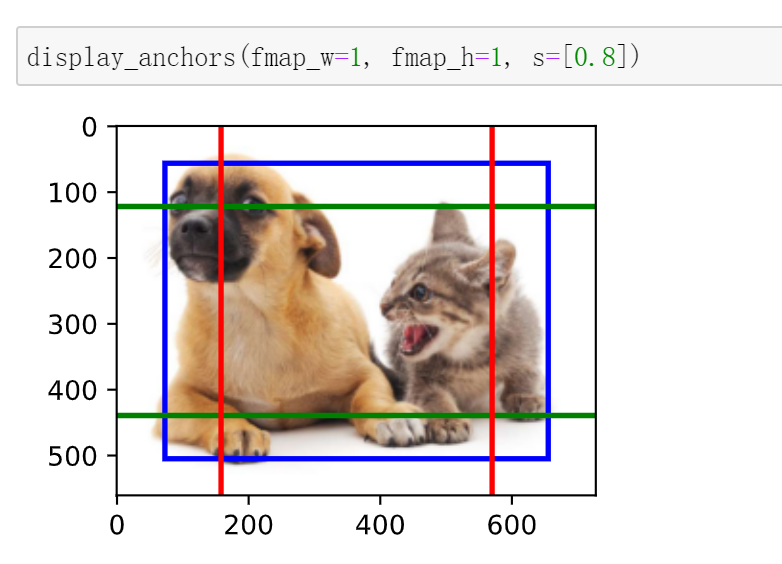
- 在多个尺度下,我们可以生成不同尺寸的锚框来检测不同尺寸的目标。
- 通过定义特征图的形状,我们可以决定任何图像上均匀采样的锚框的中心。
- 我们使用输入图像在某个感受野区域内的信息,来预测输入图像上与该区域位置相近的锚框类别和偏移量。
- 我们可以通过深入学习,在多个层次上的图像分层表示进行多尺度目标检测。
def display_anchors(fmap_w, fmap_h, s):
d2l.set_figsize()
# 前两个维度上的值不影响输出
fmap = torch.zeros((1, 10, fmap_h, fmap_w))
anchors = d2l.multibox_prior(fmap, sizes=s, ratios=[1, 2, 0.5])
bbox_scale = torch.tensor((w, h, w, h))
d2l.show_bboxes(d2l.plt.imshow(img).axes,
anchors[0] * bbox_scale)

5、单发多框检测
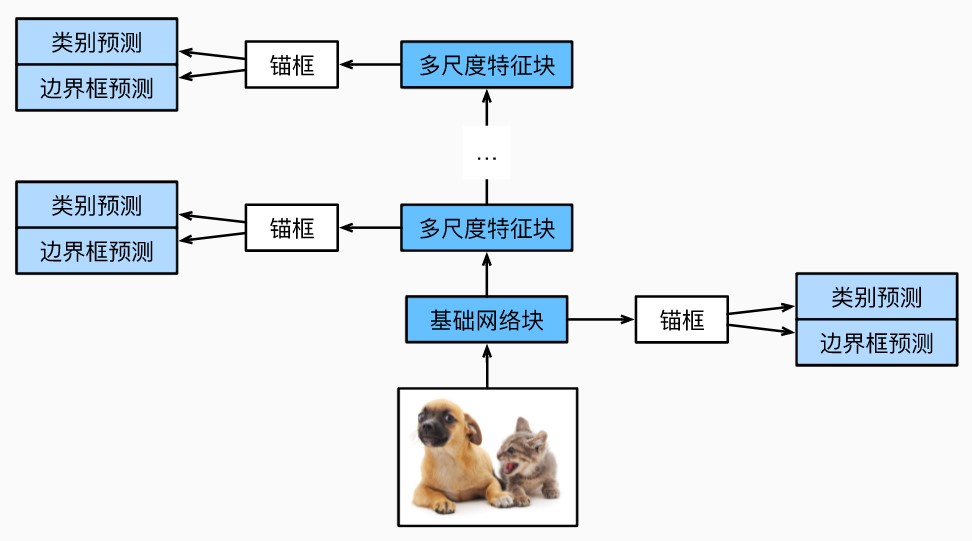
单发多框检测模型的设计如下图所示。 此模型主要由基础网络组成,其后是几个多尺度特征块。
基本网络用于从输入图像中提取特征,因此它可以使用深度卷积神经网络。
单发多框检测论文中选用了在分类层之前截断的VGG,现在也常用ResNet替代。
我们可以设计基础网络,使它输出的高和宽较大。 这样一来,基于该特征图生成的锚框数量较多,可以用来检测尺寸较小的目标。
接下来的每个多尺度特征块将上一层提供的特征图的高和宽缩小(如减半),并使特征图中每个单元在输入图像上的感受野变得更广阔。
6、区域卷积神经网络
R-CNN首先从输入图像中选取若干(例如2000个)提议区域(如锚框也是一种选取方法),并标注它们的类别和边界框(如偏移量)。
然后,用卷积神经网络对每个提议区域进行前向传播以抽取其特征。 接下来,我们用每个提议区域的特征来预测类别和边界框。
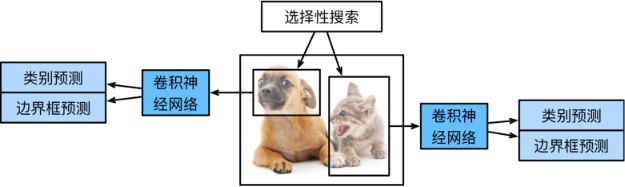
R-CNN包括以下四个步骤:
-
对输入图像使用选择性搜索来选取多个高质量的提议区域 [Uijlings et al., 2013]。这些提议区域通常是在多个尺度下选取的,并具有不同的形状和大小。每个提议区域都将被标注类别和真实边界框。
-
选择一个预训练的卷积神经网络,并将其在输出层之前截断。将每个提议区域变形为网络需要的输入尺寸,并通过前向传播输出抽取的提议区域特征。
-
将每个提议区域的特征连同其标注的类别作为一个样本。训练多个支持向量机对目标分类,其中每个支持向量机用来判断样本是否属于某一个类别。
-
将每个提议区域的特征连同其标注的边界框作为一个样本,训练线性回归模型来预测真实边界框。
7、风格迁移

8、参考文献
《动手学深度学习》
《吴恩达深度学习视频》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号