机器学习:半监督学习
1、一些定义
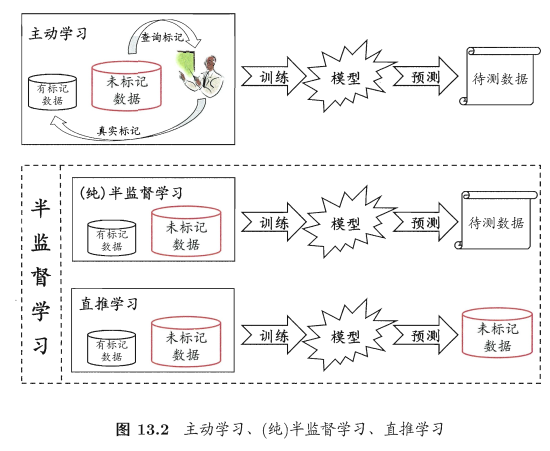
1.1主动学习
先使用有标记的样本数据集训练出一个学习器,再基于该学习器对未标记的样本进行预测,
从中挑选出不确定性高或分类置信度低的样本来咨询专家并进行打标,
最后使用扩充后的训练集重新训练学习器,这样便能大幅度降低标记成本,这便是主动学习(active learning),
目标是:使用尽量少的查询(query)来获得尽量好的性能。
ps:主动学习引入了额外的专家知识, 通过与外界的交互来将部分未标记样本转变为有标记样本
1.2一些假设
要利用未标记样本,必然要做一些将未标记样本所揭示的数据分布信息与类别标记相联系的假设:
- “聚类假设”(cluster assumption),即假设数据存在簇结构,同一个簇的样本属于同一个类别。
- “流形假设” (manifold assumption),即假设数据分布在一个流形结构上,邻近的样本拥有相似的输出值.
“邻近”程度常用“相似”程度来刻画,因此,流形假设可看作聚类假设的推广,但流形假设对输出值没有限制,因此比聚类假设的适用范围更广,可用于更多类型的学习任务,事实上,无论聚类假设还是流形假设,其本质都是“相似的样本拥有相似的输出”这个基本假设.
1.3半监督学习分类
让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能, 就是半监督学习(semi-supervised learning).
半监督学习可进一步划分为纯(pure)半监督学习和直推学习(transductive learning):
-
纯半监督学习假定训练数据中的未标记样本并非待预测的数据;是基于“开放世界”假设,希望学得模型能适用于训练过程中未观察到的数据;
-
直推学习则假定学习过程中所考虑的未标记样本恰是待预测数据,学习的目的就是在这些未标记样本上获得最优泛化性能,是基于“封闭世界”假设,仅试图对学习过程中观察到的未标记数据进行预测.
2、生成式方法
生成式方法(generative methods)是直接基于生成式模型的方法,
-
此类方法假设所有数据(无论是否有标记)都是由同一个潜在的模型“生成”的,
-
这个假设使得我们能通过潜在模型的参数将未标记数据与学习目标联系起来,而未标记数据的标记则可看作模型的缺失参数,
-
通常可基于EM算法进行极大似然估计求解.
📣
基于生成式模型的方法十分依赖于对潜在数据分布的假设,即假设的分布要能和真实分布相吻合,否则利用未标记的样本数据反倒会在错误的道路上渐行渐远,从而降低学习器的泛化性能。
基于半监督的高斯混合模型有机地整合了贝叶斯分类器与高斯混合聚类的核心思想,有效地利用了未标记样本数据隐含的分布信息,从而使得参数的估计更加准确。
3、半监督SVM
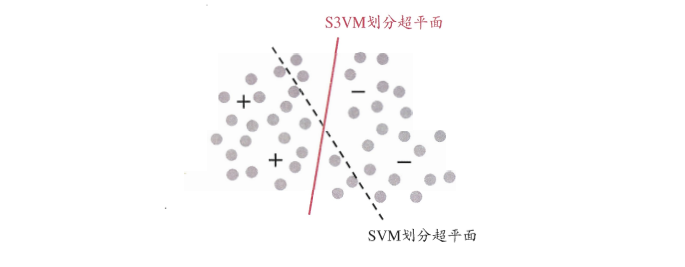
监督学习中的SVM试图找到一个划分超平面,使得两侧支持向量之间的间隔最大,即“最大划分间隔”思想。
半监督支持向量机(Semi-Supervised Support Vector Machine,简称S3VM)是支持向量机在半监督学习上的推广。
在不考虑未标记样本时,支持向量机试图找到最大间隔划分超平面,而在考虑未标记样本后,S3VM试图找到能将两类有标记样本分开,且穿过数据低密度区域的划分超平面,这里的基本假设是“低密度分隔”(low-density separation).
3.1 TSVM
TSVM (Transductive Support Vector Machine)与标准 SVM一样, TSVM是半监督支持向量机中的最著名代表,
其核心思想是:尝试为未标记样本找到合适的标记指派,使得超平面划分后的间隔最大化。
TSVM采用局部搜索的策略来进行迭代求解:
- 首先使用有标记样本集训练出一个初始SVM,
- 接着使用该学习器对未标记样本进行打标,这样所有样本都有了标记,
- 并基于这些有标记的样本重新训练SVM,
- 之后再寻找易出错样本不断调整。

4、图半监督学习
给定一个数据集,可映射为一个图,数据集中每个样本对应于图中的一个结点,若两样本之间的相似度很高,则对应结点之间存在一条边,边的“强度”正比于样本之间的相似度,可将有标记样本对应的结点想象为染过色,未标记样本对应的结点未染色,于是,半监督学习就对应于颜色在图上扩散或传播的过程。
5、基于分歧的方法
基于分歧的方法通过多个学习器之间的分歧(disagreement)/多样性(diversity来利用未标记样本数据,协同训练就是其中的一种经典方法。
‘协同训练’最初是针对于多视图(multi-view)数据而设计的,多视图数据指的是样本对象具有多个属性集,每个属性集则对应一个视图。例如:电影数据中就包含画面类属性和声音类属性,这样画面类属性的集合就对应着一个视图。
两个关于视图的重要性质:
- 相容性:使用单个视图数据训练出的学习器的输出空间是一致的。
- 互补性:不同视图所提供的信息是互补/相辅相成的。
协同训练正是很好地利用了多视图数据的“相容互补性”,
其基本的思想是:
- 首先在每个视图上基于有标记样本分别训练一个初始分类器,
- 然后让每个分类器去挑选分类置信度最高的未标记样本并赋予标记,并将带有伪标记的样本数据传给另一个分类器作为新增的有标记样本用于训练更新,
- 这个“互相学习、共同进步”的过程不断迭代进行,
- 直到两个分类器都不再发生变化,或达到预先设定的轮数为止。

6、半监督聚类
半监督聚类则是借助已有的监督信息来辅助聚类的过程。一般而言,监督信息大致有两种类型:
- 必连与勿连约束:必连指的是两个样本必属于同一个类簇,勿连则是必不属于同一个类簇。
- 标记信息:少量的样本带有真实的标记。
6.1 Constrained k-means
约束k均值(Constrained k-means) 算法是利用第一类监督信息(必连与勿连)的代表。

6.2 Constrained Seed k-means
约束种子K均值(Constrained Seed k-means)算法则是利用第一类监督信息:少量有标记的信息

参考文献
《机器学习》--周志华

 浙公网安备 33010602011771号
浙公网安备 33010602011771号