Pandas:实战案例(上)
1、实战思想
1.1链式方法
pandas 的链式编写方法是利用 pandas 的面向对象特性,下一个方法或者操作对上一个对象应用相关方法的过程。
用法
(
df.<method1> # 短注释
.<method1> # 短注释
# 长注释
.<method2>
.<...>
..<methodN>
)
优点:
思路清晰,便于编码设计
代码流畅,与注释结合便于阅读
减少变量传递,代码更加紧凑
少变量传递,减少内存占用
方便注释不执行的代码行,方便调试
不破坏源数据,源数据依然没变,再继续使用
方便封闭,可以快速定义一个方法,供如 pipe 调用
(
pd.concat(pd.read_csv('data1.csv'), pd.read_csv('data2.csv'))
.fillna(...)
.append(...)
.set_index('...')
.query('some_condition')
.assign(new_column = pd.cut(...))
.eval('...')
.pivot_table(...)
.pipe(fun) # 应用管道方法
.rename(...) # 修改轴名
.loc[lambda x: ...] # 筛选
.mask(df.A>=2,1) # 修改数据
.plot # 绘图
.line(...)
)
1.2 代码思路
- 明确需求
- 确定分析方案
- 代码设计
- 代码实施
- 得出结论
- 迭代复盘
1.3 分析方法
- 统计描述
- 相关分析
- 对比分析
- 漏斗方法
- 假设
- 机器学习
1.4 分析工具
简单的分层方法
- 操作数据层
- 数据明细层
- 数据服务层
- 数据集市层
2、数据处理案例
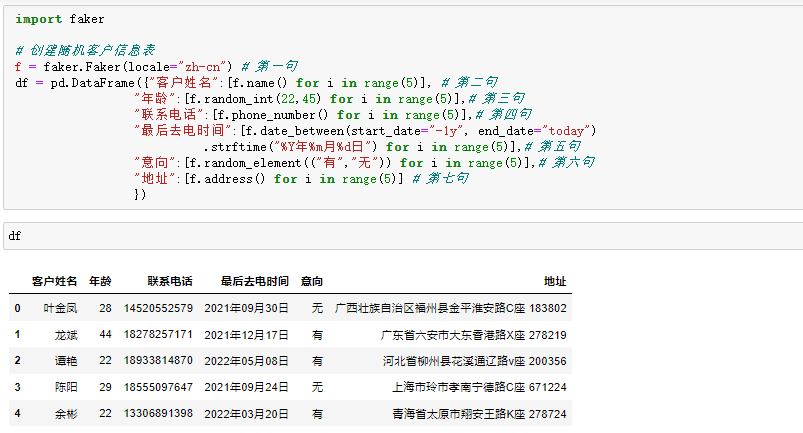
2.1 剧组表格道具
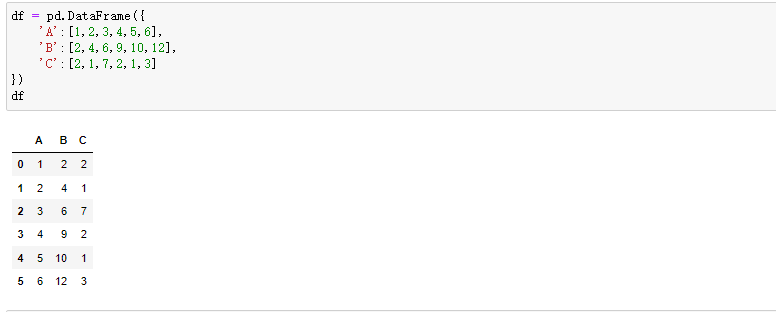
2.2 相关性最强的两个变量

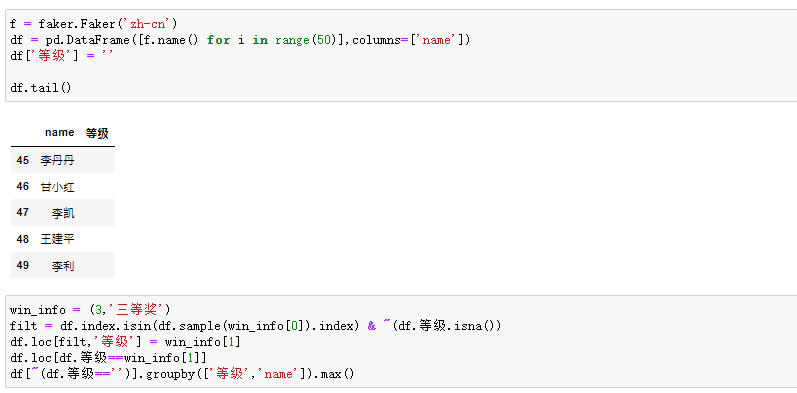
2.3 编写年会抽奖程序


 浙公网安备 33010602011771号
浙公网安备 33010602011771号