机器学习:神经网络(下)
下面介绍一些常见的神经网络
1、其他常见神经网络
1.1RBF网络
RBF网络是一种单隐层前馈神经网络,它使用径向基函数作为隐层神经元激活函数,而输出层则是对隐层神经元输出的线性组合。径向基函数,是某种沿径向对称的标量函数,通常定义为样本到数据中心之间欧氏距离的单调函数。具有足够多隐层神经元的RBF网络能以任意精度逼近任意连续函数。
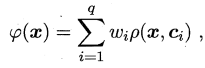
其中q为隐层神经元个数,p(x,c)是径向基函数,通常定义为样本x到数据中心c的距离的单调函数。
已经证明,具有足够多隐层神经元的径向基网络能够以任意精度逼近任意连续函数。
训练RBF网络:
- (1)确定神经元中心C的常用方式包括聚类、随机采样等;
- (2)利用BP算法来确定参数。
1.2ART网络
竞争型学习是神经网络中一种常用的无监督学习策略,在使用该策略时,网络的输出网络元相互竞争,每个时刻仅有一个竞争获取的神经元被激活,其他神经元的状态被抑制。这种机制亦称“胜者通吃”原则。
ART自适应谐振网络是竞争性学习的重要代表,由比较层、识别层、识别阈值和重置模块构成。
- 比较层:接收数据并传递给识别层
- 识别层:每个识别层神经元对应一个模式类,在训练过程中可动态增加新的模式类。接受到样本之后,最简单的竞争方式是计算输入向量与每个神经元所对应模式的距离,距离小的获胜。同时,连接权会更新,是的在以后接收到相似样本时该模式类会计算出更大的相似度。若识别度不大于阈值,则重置模块会在识别层增加一个新的神经元,代表向量即为当前输入。
在接收到比较层的输入信号后,识别层神经元之间相互竞争以产生获胜神经元。
竞争的最简单方式是,计算输入向量与每个识别层神经元所对应的模式类的代表向量之间的距离,距离最小者胜。
获胜神经元将向其他识别层神经元发送信号,抑制其激活。若输入向量与获胜神经元所对应的代表向量之间的相似度大于识别阈值,则当前输入样本将被归为该代表向量所属类别;若相似度不大于识别阈值,则重置模块将在识别层增设一个新的神经元,其代表向量就设置为当前输入向量。
优点:缓解了可塑性-稳定性窘境,在学习新知识的同时保持对旧知识的记忆。这使得ART网络可进行增量学习或在线学习。
1.3 SOM网络
SOM(自组织映射)网络是一种竞争学习型的无监督神经网络,它能将高维输入数据映射到低维空间,同时保持输入数据在高维空间的拓扑结构,即将高维空间中相似的样本点映射到网络输出层的邻近神经元。
SOM的训练目标就是为每个输出层神经元找到合适的权向量,以达到保持拓扑结构的目的。
SOM的训练过程:在接收到一个训练样本后,每个输出层神经元会计算该样本与自身携带的权向量之间的距离,距离最近的神经元成为竞争获胜者,称为最佳匹配单元。然后,最佳匹配单元及其临近神经元的权向量将被调整,以使得这些权向量与当前输入样本的距离缩小。
1.4 级联相关网络
结构自适应网络将网络结构也当作学习的目标之一,并希望能在训练过程中找到最符合数据特点的网络结构。级联相关网络是结构自适应网络的重要代表。
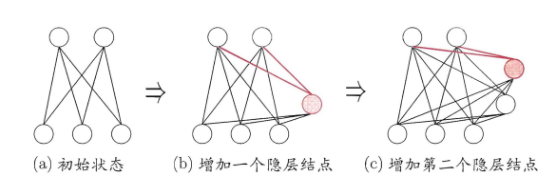
级联相关网络有两个主要成分:“级联”和“相关”。级联是指建立层次连接的层级结构。在开始训练时,网络只有输入层和输出层,处于最小拓扑结构;随着训练的进行,新的隐层神经元逐渐加入,从而创建起层级结构。当新的隐层神经元加入时,其输入端连接权值实冻结固定的。相关是指通过最大化新神经元的输出与网络误差之间的相关性来训练相关的参数。
1.5 Elman网络
递归神经网络允许网络中出现环形结构,从而可让一些神经元的输出反馈回来作为输入信号。
这样的结构与信息反馈过程,使得网络在t时刻的输出状态不仅与t时刻的输入有关,还与t-1时刻的网络状态有关,从而能处理与时间有关的动态变化。Elman网络是最常用的递归网络之一。
1.5 Bolyzmann机
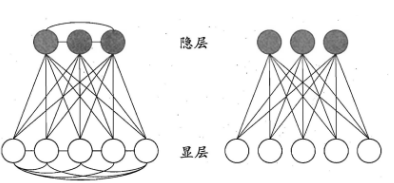
神经网络中有一类模型是为网络状态定义一个“能量”,能量最小化时网络达到理想状态,而网络的训练就是在最小化这个能量函数。Bolyzmann机就是一种“基于能量的模型”。分为两层:显层与隐层。显层用于输入和输出,隐层被理解为数据的内在表达。其中神经元都是布尔型,只能取0、1。Boltzmann 机的训练过程就是将每个训练样本视为一个状态向量,使其出现的概率尽可能大。受限Boltzmann机常用对比散度算法进行训练。
2、深度学习
经典的深度学习模型就是很深层的神经网络。多隐层神经网络难以直接用经典算法进行训练,因为误差在多隐层内逆传播时,往往会“发散”而不能收敛到稳定状态。
无监督逐层训练是多隐层网络训练的有效手段,其基本思想是每次训练一层隐结点,训练时将上一层隐结点的输出作为输入,而本层隐结点的输出作为下一层隐结点的输入,这称为“预训练”;在预训练全部完成后,再对整个网络进行“微调”训练。
“预训练+微调”的做法可视为将大量参数分组,对每组先找到局部看来比较好的设置,然后再基于这些局部较优的结果联合起来进行全局寻优。另一种节省训练开销的策略是“权共享”,即让一组神经元使用相同的连接权。这个策略在卷积神经网络(CNN)中发挥了重要作用。
以CNN进行手写数字识别任务为例所示,网络输入是一个32*32的手写数字图像,输出是其识别结果,CNN复合多个“卷积层”和“采样层”对输入信号进行加工,然后在连接层实现与输出目标之间的映射。每个卷积层都包含多个特征映射,每个特征映射是一个由多个神经元构成的“平面”,通过一种卷积滤波器提取输入的一种特征。采样层亦称为“汇合”层,其作用是基于局部相关性原理进行亚采样,从而在减少数据量的同时保留有用信息。CNN可用BP算法进行训练,但在训练中,无论是卷积层还是采样层,其每一组神经元都是用相同的连接权,从而大幅减少了需要训练的参数数目。
通过多层处理,逐渐将初始的“低层”特征表示转化为“高层”特征表示后,用“简单模型”即可完成复杂的分类等学习任务。由此可将深度学习理解为进行“特征学习”或“表示学习”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号