机器学习:决策树(下)
前面机器学习:决策树(上)已经学习了构造决策树的基本流程、三个常见算法、以及划分属性的方法,下面将学习如何优化一个决策树
1、剪枝处理
剪枝(pruning)是决策树学习算法应对过拟合的主要手段。因为决策树模型太强大了,很可能把训练集学得太好以致于把训练集本身的特性也给学习了(特别是属性数多于样本数的情况),所以去除掉一些分支是有必要的。
怎么判断剪枝有没有用呢?具体来说就是判断剪枝后模型的泛化性能有没有提升?这就涉及到第二章模型评估与选择的内容了。不过这里不用做比较检验,我们需要做的首先是选定一种评估方法划分训练集和测试集,然后选定一种性能度量用来衡量剪枝前后的模型在测试集上的效果。
预剪枝
预剪枝(prepruning)是在决策树生成的过程中,对每个节点在划分前先进行估计,若当前节点的划分不能带来决策树泛化性能提升(比方说,划分后在测试集上错得更多了 / 划分前后在测试集上效果相同),就停止划分并将当前节点标记为叶节点。
后剪枝
后剪枝(postpruning)是先从训练集生成一颗完整的决策树,然后自底向上地逐个考察非叶节点,若将该节点对应的子树替换为叶节点能带来决策树泛化性能的提升,则将该子树替换为叶节点。实际任务中,即使没有提升,只要不是性能下降,一般也会剪枝,因为根据奥卡姆剃刀准则,简单的模型更好。
特别地,只有一层划分(即只有根节点一个非叶节点)的决策树称为决策树桩(decision stump)。
优缺点
预剪枝是一种贪心策略,因为它在决策树生成时就杜绝了很多分支展开的机会,所以不但降低了过拟合的风险,同时也显著减少了模型的训练时间开销和测试时间开销。但是!这种贪心策略有可能导致欠拟合,因为有可能当前划分不能提升模型的泛化性能,但其展开的后续划分却会显著提升泛化性能。在预剪枝中这种可能被杜绝了。
后剪枝是种比较保守的策略,欠拟合的风险很小,泛化性能往往优于预剪枝的决策树。但是由于后剪枝是在生成了完整决策树后,自底向上对所有非叶节点进行考察,所以训练时间开销要比未剪枝决策树和预剪枝决策树都大得多。
2、连续与缺失值
2.1连续值处理
前面线性模型已经谈到了离散属性连续化,而决策树模型需要的则是连续属性离散化,因为决策树每次判定只能做有限次划分。最简单的一种离散化策略是C4.5算法采用的二分法(bi-partition)。
基本思想为:给定样本集D与连续属性\(\alpha\),二分法试图找到一个划分点 \(t\)将样本集D在属性\(\alpha\)上分为≤ t与>t。
- 首先将\(\alpha\)的所有取值按升序排列,所有相邻属性的均值作为候选划分点(n − 1,n为\(\alpha\)所有的取值数目)。
- 计算每一个划分点划分集合\(D\)(即划分为两个分支)后的信息增益。
- 选择最大信息增益的划分点作为最优划分点。
2.2缺失值处理
在前面的讨论中,我们都是假定样本属性的值都不是缺失的,但现实情况下还是存在一些样本是缺失的。例如由于测试成本,隐私保护等等。
如果缺失属性样本较多的话,并且不做任何处理,简单的放弃不完整样本的话,显然对数据信息是极其浪费的。样本不能放弃,但是属性缺失我们不得不放弃,因为本身就缺失,我们不可能凭空随便插入一个值,所以我们只能在划分过程中进行处理,减小划分误差。总的来说需要我们考虑的问题有两个:
(1)如何在属性值缺失的情况下进行划分属性选择?

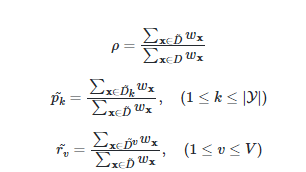
注意,根节点中的权重初始化为1。
(2)给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?

假设有一个包含缺失值的属性被计算出是最优划分属性,那么我们就要按该属性的不同取值划分数据集了。缺失该属性值的样本怎么划分呢?答案是按概率划分,这样的样本会被同时划入所有子节点,并且其权重更新为对应的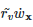
可以把无缺失值的决策树建模想象为各样本权值恒为1的情形,它们只对自己所属的属性值子集作贡献。而样本含缺失值时,它会以不同的概率对所有属性值子集作贡献。
3、多变量决策树
前面提到的决策树都是单变量决策树(univariate decision tree), 即在每个节点处做判定时都只用到一个属性。它有一个特点,就是形成的分类边界都是轴平行(axis-parallel)的。
如果把属性都当作坐标空间中的坐标轴,由于我们建模时假设样本的各属性之间是没有关联的,所以各坐标轴是相互垂直的。而决策数每次只取一个确定的属性值来划分,就等同于画一个垂直于该属性坐标轴的超平面(只有两个属性时就是一条线),它与其他坐标轴都是平行的,这就是轴平行。最终由多个与坐标轴平行的超平面组成分类边界。
这样有一个弊端就是,如果真实分类边界特别复杂,就需要画出很多超平面(线),在预测时就需要继续大量的属性测试(遍历决策树)才能得到结果,预测时间开销很大。
多变量决策树(multivariate decision tree),顾名思义,它不再是选择单个最优划分属性作为节点,而是试图寻找一个最优的多属性的线性组合作为节点,它的每个非叶节点都是一个线性分类器。多变量决策树的决策边界能够斜着走,甚至绕曲线走,从而用更少的分支更好地逼近复杂的真实边界。
4、参考文献
《机器学习》周志华

 浙公网安备 33010602011771号
浙公网安备 33010602011771号