机器学习:线性模型(下)
线性模型(上)记录了线性模型寻求最优解的原理,下面学习线性模型遇到的多分类问题、类别不平衡问题:
1、多分类学习
一对一(OvO):N个类别两两配对,将多分类问题转化为N(N-1)/2个二分类问题。
一对余(OvR):假设有N个类别,每次把一个类作为正类,其他类作为反类,将多分类问题转化为(N-1)个二分类问题。
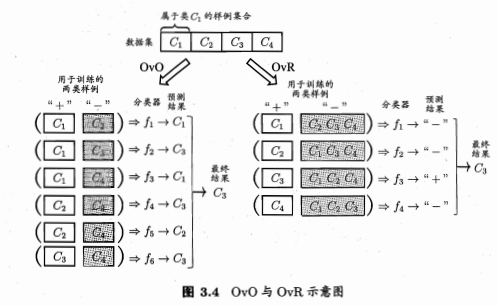
多对多(MvM):每次选择若干类为正类,若干个为反类。常用方法为“纠错输出码”(Error Correcting Output Codes, ECOC)。
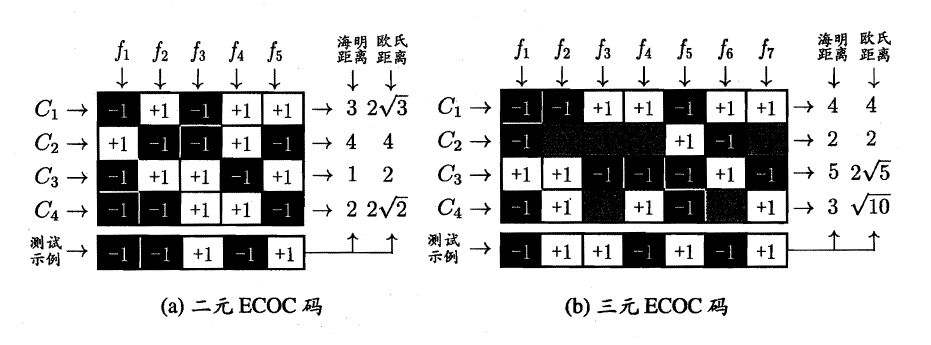
“纠错输出码” (Error Correcting Output Codes, 简称 ECOC)是将编码的思想引入类别拆分,并尽可能在解码过程中具有容错性,ECOC工作过程主要分为两步
-
编码:对N个类别做M次划分,每次划分将一部分类别划为正类,一部分划为反类,从而形成一个二分类训练集;这样一共产生M个训练集,可训练出M个分类器.
-
解码: M个分类器分别对测试样本进行预测,这些预测标记组成一个编码,将这个预测编码与每个类别各自的编码进行比较,返回其中距离最小的类别作为最终预测结果.
2、类别不平衡
(1)问题描述
数据集正样本和负样本的数量相差很多,如:998个负样本,2个正样本。学习算法可能会学习到一个永远为正或负的分类器模型,但这样的模型没有应用价值。
(2)解决方法(以“负样本很多正样本很少”为例)
欠采样:去除一些负样本,使正反样本数量接近。
过采样:增加一些正样本,使正反样本数量接近。
阈值移动:在分类器预测正负概率比时,乘上负样本与正样本数量之比。(正负概率比>1,则预测结果为正例)
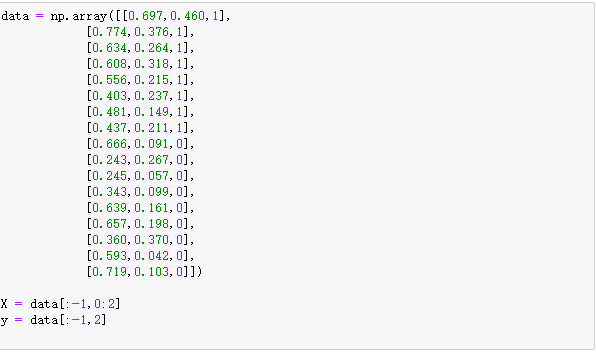
3、课后题

4、参考文献
《机器学习》-周志华

 浙公网安备 33010602011771号
浙公网安备 33010602011771号