机器学习:线性模型(上)
1、线性回归
线性:
- 两个变量之间的关系是一次函数关系
回归:
- 人们在测量事物的时候因为客观条件所限,求得的都是测量值,而不是事物真实的值,为了能够得到真实值,无限次的进行测量,最后通过这些测量数据计算回归到真实值,这就是回归的由来。
线性回归问题就是试图学到一个线性模型尽可能准确地预测新样本的输出值。解决的就是通过已知的数据得到未知的结果。
有时输入的属性值并不能直接被我们的学习模型所用,需要进行相应的处理。
-
连续属性,一般都可以被学习器所用,有时会根据具体的情形作相应的预处理,例如:归一化等;
-
离散属性,可作下面的处理:
- “序关系”:可以将其转化为连续值,
- 例如:身高属性分为“高”“中等”“矮”,可转化为数值:{1, 0.5, 0}。
- “序关系”:通常将其转化为向量的形式,
- 例如:性别属性分为“男”“女”,可转化为二维向量:{(1,0),(0,1)}。
- “序关系”:可以将其转化为连续值,
线性回归试图学得:
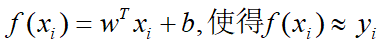
- ps:f(xi)是预测值,yi是真实标签值
如何确定w和b呢?显然在于如何衡量f(xi)与yi之间的差别。均方误差是回归任务中最常用的性能度量。
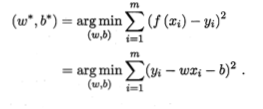
- 均方误差最小化
- 最小二乘法:
- 即试图找到一条直线,使所有样本到直线上的欧氏距离之和最小,从而求解出w,b
- 最小二乘法:
2、逻辑回归(对数几率回归)
对数几率引入了一个对数几率函数(logistic function),将预测值投影到0-1之间,从而将线性回归问题转化为二分类问题。
线性模型外面套上一层Sigmoid函数(sigmoid函数即形似S的函数),就可以解决二分类问题。求解方法与线性回归一样,用最小二乘法最小化均方误差。
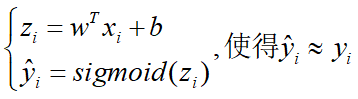
即若预测值大于零就判为正例,小于零则判为反例,预测值为临界值零则可任意判别
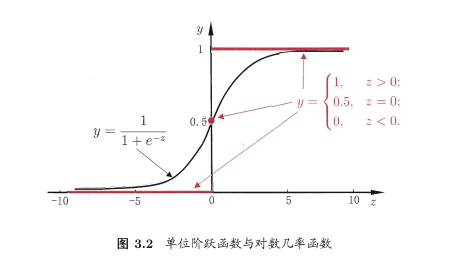
在用线性回归模型的预测结果去逼近真实标记的对数几率,因此,其对应的模型称为“对数几率回归”(logistic regression,亦称 logit regression).特别需注意到,虽然它的名字是“回归”,但实际却是一种分类学习方法。
优点:
-
这种方法有很多优点,例如它是直接对分类可能性进行建模,无需事先假设数据分布,这样就避免了假设分布不准确所带来的问题;
-
它不是仅预测出“类别”,而是可得到近似概率预测,这对许多需利用概率辅助决策的任务很有用;
-
此外,对率函数是任意阶可导的凸函数,有很好的数学性质,现有的许多数值优化算法都可直接用于求取最优解。
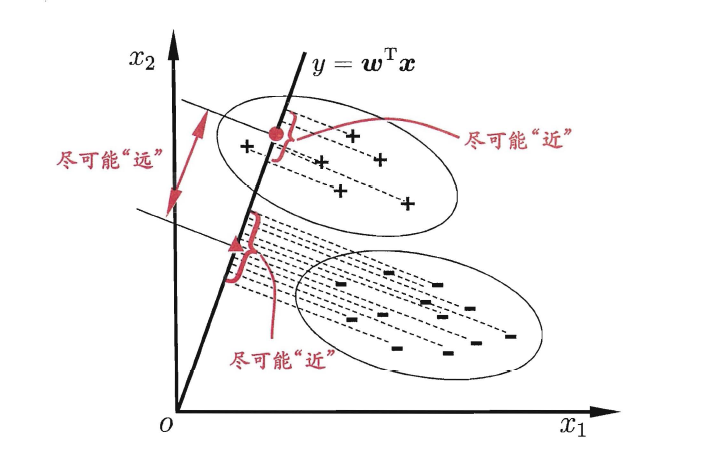
3、线性判别分析(LDA)
将数据的特征点(坐标)投影到一条直线上,使同类样本的投影点尽可能靠近,异类样本的投影点尽可能远离,从而实现分类的效果。LDA用“降维+分类”的思想,主要解决二分类问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号