机器学习:模型评估与选择
模型评估与选择
1、经验误差与过拟合
错误率:分类错误的样本数占样本总数的比例。
精度=1-错误率。
误差:学习器的实际预测输出与样本的真实输出之间的差异。
训练误差/经验误差:学习器在训练集上的误差。
泛化误差:在新样本上的误差。
2、评估方法
⭐留出法:直接将数据集划分为两个互斥的集合。
- 需要注意的是:训练/测试集的划分要尽可能保持数据分布的一致性,以避免由于分布的差异引入额外的偏差,常见的做法是采取分层抽样。
- 同时,由于划分的随机性,单次的留出法结果往往不够稳定,一般要采用若干次随机划分,重复实验取平均值的做法。
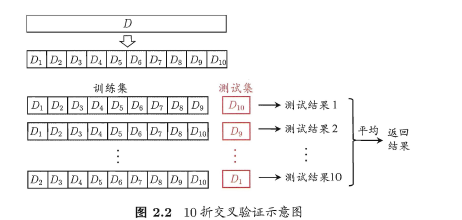
⭐交叉验证法:先将数据集划分为k个大小相似的互斥子集(从数据集中分层采样得到)。每用k-1个子集的并集作为训练集,余下的子集作为测试集,从而进行k次训练和测试,最终返回k个测试结果的均值。k最常用的取值是10。
- 与留出法类似,将数据集D划分为K个子集的过程具有随机性,因此K折交叉验证通常也要重复p次,称为p次k折交叉验证,常见的是10次10折交叉验证,即进行了100次训练/测试。
- 特殊地当划分的k个子集的每个子集中只有一个样本时,称为“留一法”,显然,留一法的评估结果比较准确,但对计算机的消耗也是巨大的。
自助法:给定包含m个样本的数据集D,又放回的重复抽样m次,得到与原始数据集大小相同的样本数据集D'
- 但由于自助法产生的数据集(随机抽样)改变了初始数据集的分布,因此引入了估计偏差。在初始数据集足够时,留出法和交叉验证法更加常用。
验证集:模型评估与选择中用于评估测试的数据集。(同一算法不同模型对比)
测试集:对比不同算法的泛化性能。(不同算法对比)
3、性能度量
在回归任务中,即预测连续值的问题,最常用的性能度量是“均方误差”(mean squared error)
在分类任务中,即预测离散值的问题,最常用的是错误率和精度.
- 错误率是分类错误的样本数占样本总数的比例
- 精度则是分类正确的样本数占样本总数的比例
3.1 查全率、查准率
错误率和精度虽然常用,但不能满足所有的需求,例如:在推荐系统中,我们只关心推送给用户的内容用户是否感兴趣(即查准率/精确率),或者说所有用户感兴趣的内容我们推送出来了多少(即查全率/召回率)。因此,使用查准/查全率更适合描述这类问题。

3.2 ROC和AUC
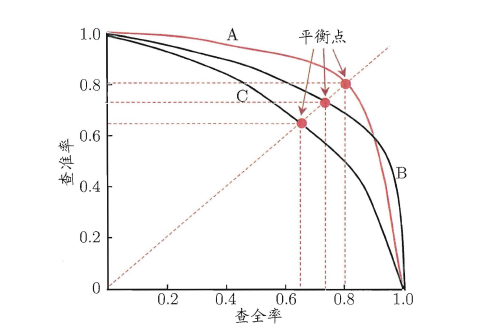
“P-R曲线”正是描述查准/查全率变化的曲线,
- P-R曲线定义如下:根据学习器的预测结果(一般为一个实值或概率)对测试样本进行排序,将最可能是“正例”的样本排在前面,最不可能是“正例”的排在后面,按此顺序逐个把样本作为“正例”进行预测,每次计算出当前的P值和R值,如下图所示:
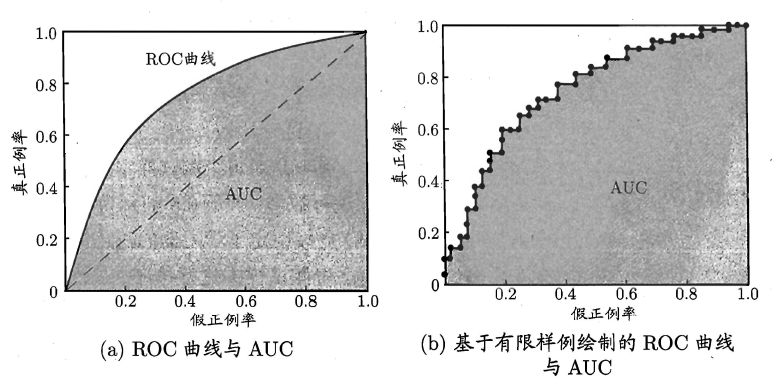
ROC曲线与P-R曲线十分类似,都是按照排序的顺序逐一按照正例预测,不同的是ROC曲线以“真正例率”(True Positive Rate,简称TPR)为横轴,纵轴为“假正例率”(False Positive Rate,简称FPR),ROC偏重研究基于测试样本评估值的排序好坏。

4、 方差与偏差
以回归任务为例子:
偏差:期望输出与真是标记的差别。刻画了学习算法本身的拟合能力。
方差:同样训练集的变动造成学习性能的变化。刻画了数据扰动所造成的影响。
噪声:当前任务上任何学习算法所能达到的期望泛化误差的下限。刻画的学习本身的难度。
泛化误差可分解为偏差、方差和噪声之和。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号