Pandas:数据重塑与透视
Pandas 主要提供以下数据变形方面的操作:
透视 df.pivot / pd.pivot_table
堆叠 stacking / unstacking
数据融合 (melt)
交叉表 crosstab()
分解 pd.factorize(x, sort=True)
虚拟对象 pd.get_dummies(df)
爆炸 df.explode('values')
窗口计算 rolling() expanding()
1、数据透视
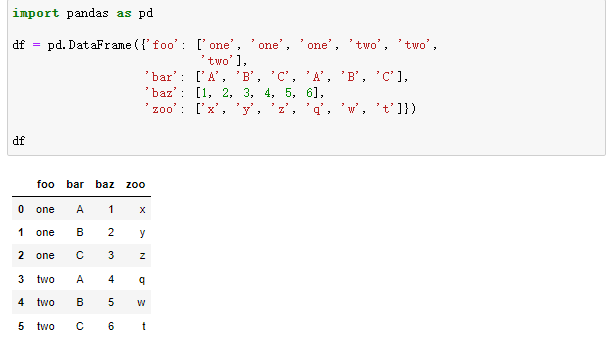
1.1整理透视操作
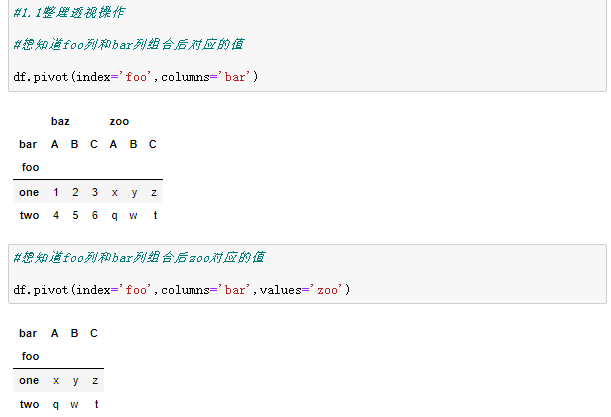
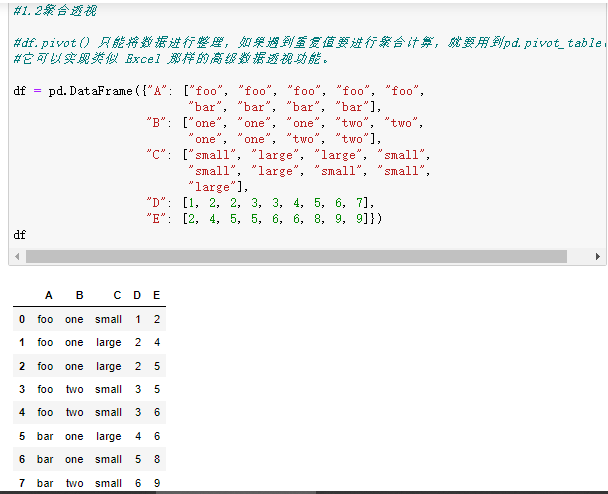
1.2聚合透视
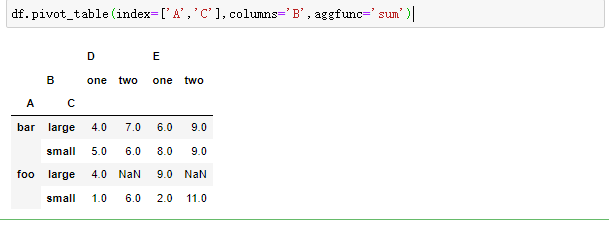
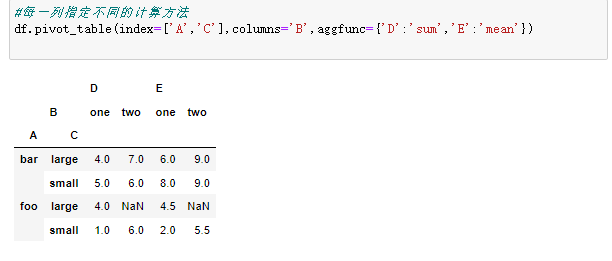
2、数据堆叠
stack:“透视”某个级别的(可能是多层的)列标签,返回带有索引的 DataFrame,该索引带有一个新的最里面的行标签。
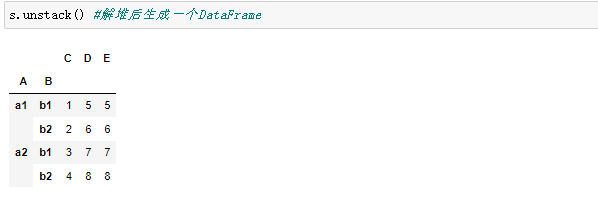
unstack:(堆栈的逆操作)将(可能是多层的)行索引的某个级别“透视”到列轴,从而生成具有新的最里面的列标签级别的重构的 DataFrame。
stack 过程将数据集的列转行,unstack 过程为行转列。
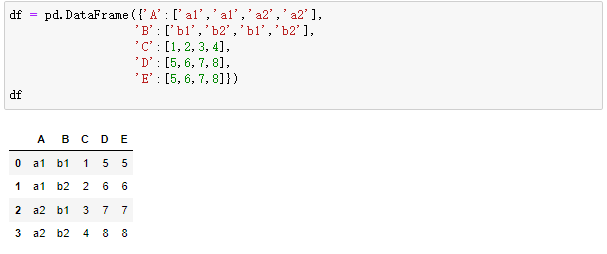
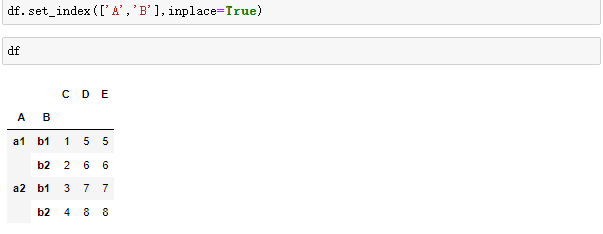
2.1堆叠操作

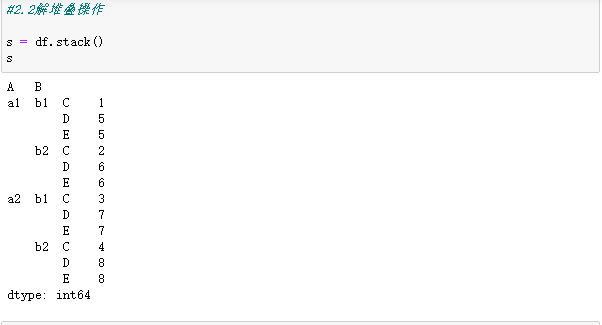
2.2解堆叠
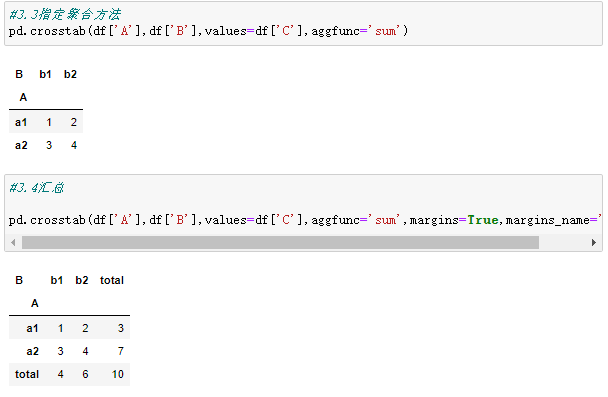
3、交叉表
交叉表是用于统计分组频率的特殊透视表。
简单来说,就是将两个或者多个列重中不重复的元素组成一个新的 DataFrame,新数据的行和列交叉的部分值为其组合在原数据中的数量。


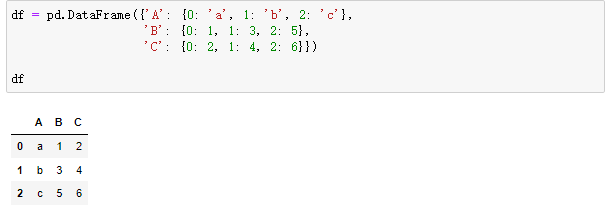
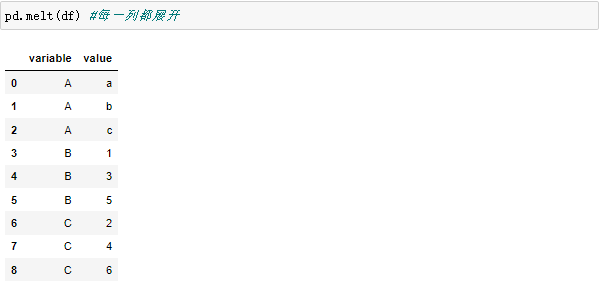
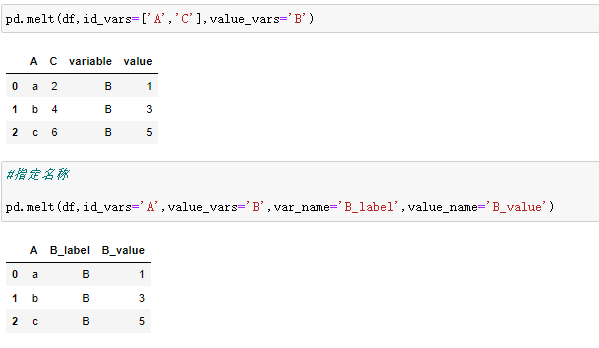
4、数据融合
df.melt() 是 df.pivot() 逆转操作函数。
简单说就是将指定的列放到铺开放到行上名为variable(可指定)列,值在value(可指定)列。
5、虚拟变量
虚拟变量(Dummy Variables) ,又称虚设变量、名义变量或哑变量,用以反映质的属性的一个人工变量,是量化了的自变量,通常取值为0或1。经常用在 one-hot 特征提取。

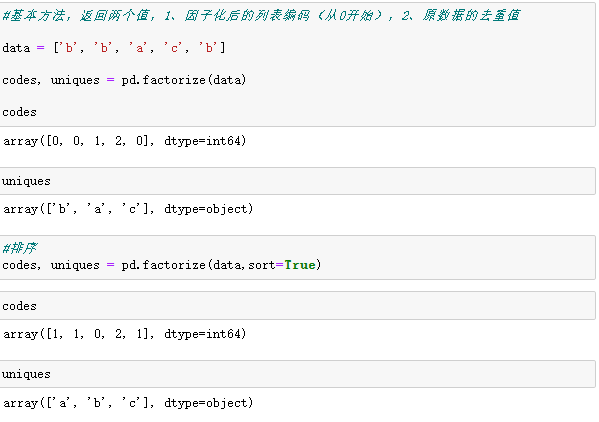
6、因子化
因子化值是指将个一维的数据,由于在大量的重复值,可以解析成枚举值,这样我们就方便进行分辨。
factorize 既可以用作顶层函数 pandas.factorize(),也可以用作Series.factorize() 和 Index.factorize() 方法。
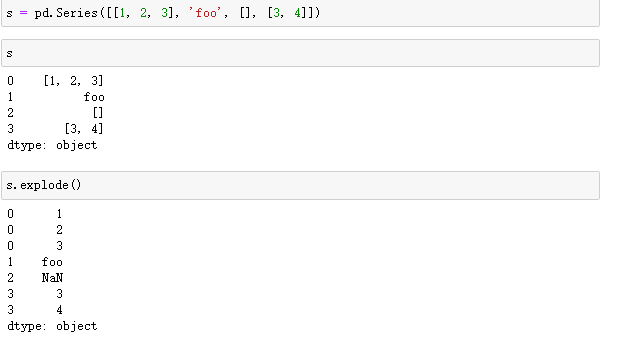
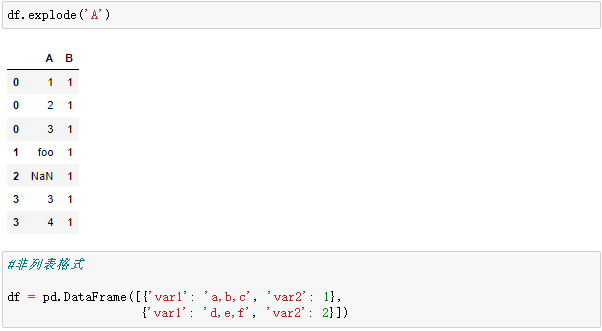
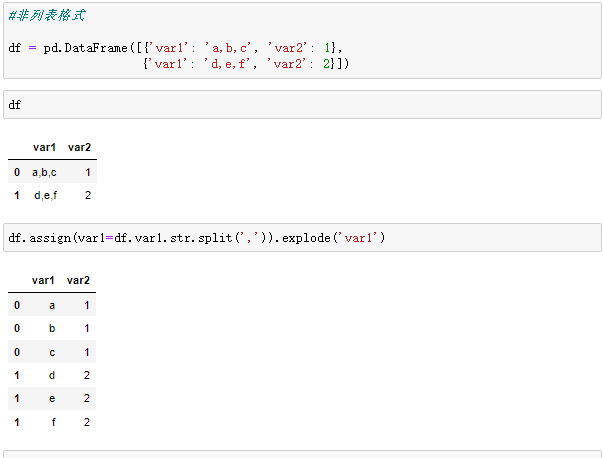
7、爆炸列表
爆炸这个词非常形象,是指将类似列表的每个元素转换为一行,索引值是相同的


 浙公网安备 33010602011771号
浙公网安备 33010602011771号