专家知识
任务:
要求预测给定日期和时间,预测会有多少人在Andreas的家门口组一辆自行车。
1、先看一下数据集数据集
自行车数据集给出了2015年8月每天的自行车租赁的数目,每隔3小时统计一次
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
import mglearn
import pandas as pd
citibike = mglearn.datasets.load_citibike()
print("citi bike :\n{}".format(citibike.head()))
'''
```
citi bike :
starttime
2015-08-01 00:00:00 3
2015-08-01 03:00:00 0
2015-08-01 06:00:00 9
2015-08-01 09:00:00 41
2015-08-01 12:00:00 39
Freq: 3H, Name: one, dtype: int64
```
'''
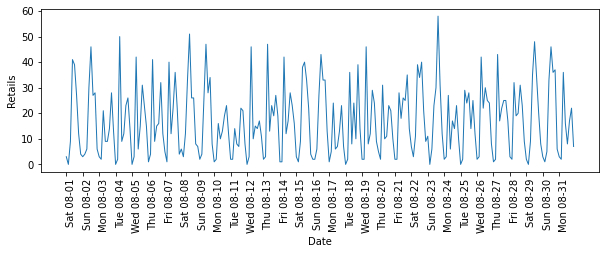
#给出整个月租车数量的可视化
plt.figure(figsize=(10,3))
xticks = pd.date_range(start=citibike.index.min(),end=citibike.index.max(),freq='D')
plt.xticks(xticks,xticks.strftime("%a %m-%d"),rotation=90,ha='left')
plt.plot(citibike,linewidth=1)
plt.xlabel("Date")
plt.ylabel("Retails")
📣
在对这种时间序列上的预测任务进行评估时,我们通常希望从过去学习并预测未来。
- 在划分训练集和测试集的时候,我们希望使用某个特定日期之前的所有数据作为训练集,该日期之后的所有数据作为测试集
2、用单一整数特征作为数据表示
#提取目标值(租车数量)
y = citibike.values
#利用“%s”将时间转换为POSIX时间
X = citibike.index.astype("int64").values.reshape(-1,1)
#定义一个函数,将数据划分为训练集和测试集,构建模型并将结果可视化
n_train = 184
def eval_on_features(features,target,regressor):
#将给定特征划分为训练集和测试集
X_train,X_test = features[:n_train],features[n_train:]
#同样划分目标数组
y_train,y_test = features[:n_train],features[n_train:]
#用训练集拟合模型,并用测试集进行测试
regressor.fit(X_train,y_train)
print("Test-set R^2:{:.2f}".format(regressor.score(X_test,y_test)))
y_pred = regressor.predict(X_test) #预测测试集
y_pred_train = regressor.predict(X_train) #预测训练集
plt.figure(figsize=(10,3))
plt.xticks(range(0,len(X),8),xticks.strftime("%a %m-%d"),rotation=90,ha='left')
plt.plot(range(n_train),y_train,label="train")
plt.plot(range(n_train,len(y_test)+n_train),y_test,'-',label='test')
plt.plot(range(n_train),y_pred_train,'--',label="prediction train")
plt.plot(range(n_train,len(y_test)+n_train),y_pred,'--',label="prediction test")
plt.legend()
plt.xlabel("Date")
plt.ylabel("Retails")
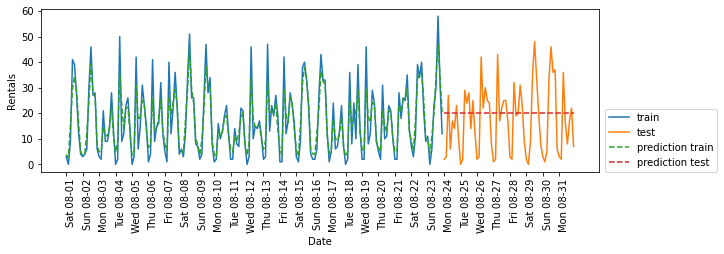
随机森林需要很少的数据预处理,它很适合作为第一个模型
我们使用POSIX时间特征X,并将随机森林回归传入eval_on_features函数
from sklearn.ensemble import RandomForestClassifier
regressor = RandomForestClassifier(n_estimators=100,random_state=0)
plt.figure()
eval_on_features(X,y,regressor)
'''
`Test-set R^2: -0,04`
'''
📣
在训练集上预测结果相当好,这符合随机森林通常的表现。
但对于测试集来说,预测结果是一条常数直线 ,说明什么都没有学到。
- 测试集中POSIX时间特征的值超出了训练集中特征的取值范围:测试集中的数据点的时间戳要晚于训练集中的所有数据点。
- 树以及随机森林无法外推到训练集之外的特征范围。
- 结果就是模型只能预测训练集中最近数据点的目标值,即最后一天观测到数据的时间。
3、专家知识
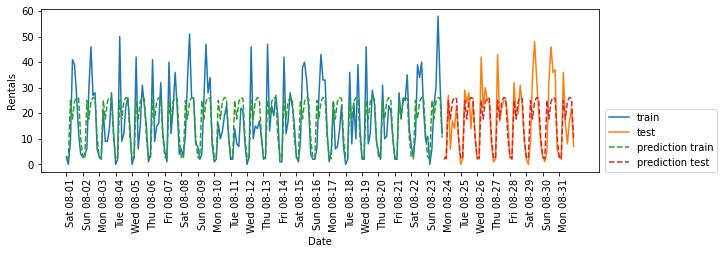
3.1 每天的hour作为特征
通过观察训练集中租车数量的图像,我们发现两个因素非常重要:一天内的时间与一周的星期几。因此,我们来研究这两个特征。
#使用每天时刻作为特征
X_hour = citibike.index.hour.values.reshape(-1, 1)
eval_on_features(X_hour, y, regressor)
'''
`Test-set R^2: 0.60`
'''
3.2 一周星期几和每天的时刻作为特征
X_hour_week = np.hstack([citibike.index.dayofweek.values.reshape(-1, 1),
citibike.index.hour.values.reshape(-1, 1)])
eval_on_features(X_hour_week, y, regressor)
'''
`Test-set R^2: 0.84`
'''
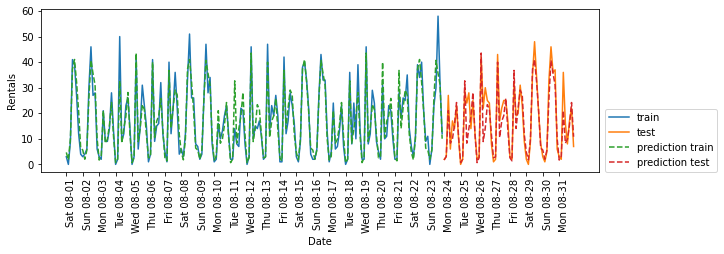
📣
此时模型的预测效果很好,模型学到的内容可能是8月前23天中星期几与时刻每种组合的平均租车数量(交互特征)。
3.2.1 尝试一下LinearRegression
from sklearn.linear_model import LinearRegression
eval_on_features(X_hour_week, y, LinearRegression())
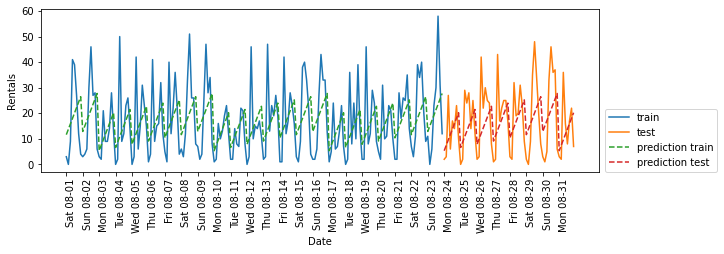
📣
LinearRegression的效果差得多,而且周期性模式看起来很奇怪。
其原因在于我们用整数编码一周星期几和一天内的时刻,它们被解释为线性函数。
因此,线性模型只能学到关于每天时间的线性函数。
它学到的是,时间越晚,租车数量越多。但实际模式比这复杂得多。
(1)one-hot编码
我们可以通过将整数解释为分类变量(用OneHotEncoder进行转换)来获取这种模式:
enc = OneHotEncoder()
X_hour_week_onehot = enc.fit_transform(X_hour_week).toarray()
eval_on_features(X_hour_week_onehot, y, Ridge())
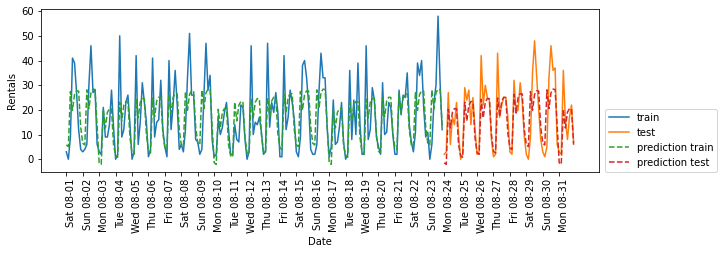
📣
它给出了比连续特征编码好得多的匹配。现在现在模型为一周内的每天都学到了一个系数,为一天内的每个时刻都学到了一个系数。
(2)用交互项作为特征
-
交互特征进行预测
poly_transformer = PolynomialFeatures(degree=2, interaction_only=True, include_bias=False) X_hour_week_onehot_poly = poly_transformer.fit_transform(X_hour_week_onehot) lr = Ridge() eval_on_features(X_hour_week_onehot_poly, y, lr)
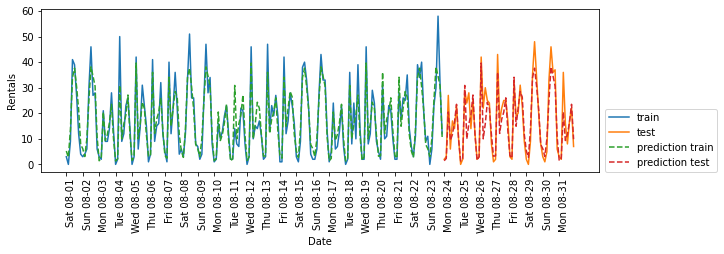
📣
这一变换最终得到一个性能与随机森林类似的模型。
- 这一模型的一大优点是,可以很清楚地看到学到的内容:对每个星期几和时刻的交互项学到一个系数。我们可以将模型学到的系数作图,这对于随机森林是做不到的。
画图:
hour = ["%02d:00" % i for i in range(0, 24, 3)]
day = ["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"]
features = day + hour

4、总结
从上面的例子中我们可以看出,对于模型选取合适的特征数据表示方式,通过特征工程生成新特征和利用专家知识从数据中创建导出特征的运用很重要,特别是对于线性模型,可能会从分箱、添加多项式和交互项而生成新特征中大大受益;
对于更复杂的非线性模型(如随机森林、SVM),在无需显式扩展特征空间的前提下就可以学习更复杂的任务。
在实践中,所使用的特征(以及特征与方法之间的匹配)通常是机器学习表现良好的重要因素。
5、参考文献
《python机器学习基础教程》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号