Pandas 分组聚合 :分组、分组对象操作
1、概述
1.1 group语法
df.groupby(self, by=None, axis=0, level=None,
as_index: bool=True, sort: bool=True,
group_keys: bool=True,
squeeze: bool=False,
observed: bool=False, dropna=True)
📣
其中 by 为分组字段,由于是第一个参数可以省略,可以按列表给多个。会返回一个groupby_generic.DataFrameGroupBy对象,如果不给定聚合方法,不会返回 DataFrame。
1.2 DateFrame应用分组
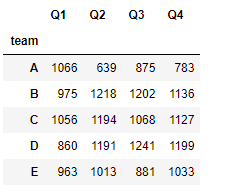
#按team进行分组,并求和
df.groupby('team').sum()
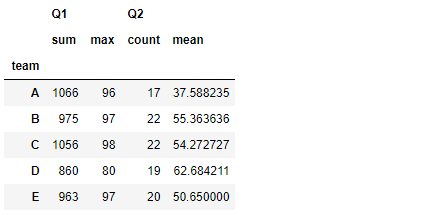
#对不同列进行不同的聚合计算,对分组对象使用agg,传入函数字典
#对分组后的同一列进行不同运算
df.groupby('team').agg({'Q1':['sum','max'],'Q2':['count','mean']})
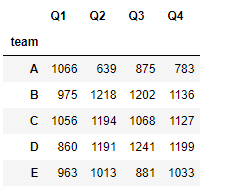
1.3 Series应用分组
⭐如果给groupby的by参数传入一个Series,此series与分组数据的索引对齐后,按series的值进行分组
df.groupby(by=df.team).sum()
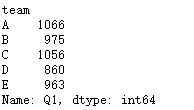
df.Q1.groupby(df.team).sum()
2、分组
⭐df.groupby()会生成一个分组对象,把这个对象的各个字段按照一定的聚合方法输出
下面介绍,分组对象 and 分组对象的方法有哪些
2.1 分组对象
2.2 按标签分组
⭐按某一列/多列进行分组
⭐如果是多列,会按照这几个列的排列组合的去重,进行分组,并且get_group()时要传入元组
grouped = df.groupby('team')
grouped.get_group('A')
grouped = df.groupby(['team','name'])
grouped.get_group(('A','Ack'))

2.3 表达式
将数据分为ture 和 false两组
grouped = df.groupby(lambda x: x>60)
grouped.sum()
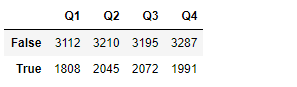
df.groupby(lambda x: 'Q' in x,axis=1).sum() #按列名是否包含字母Q,分成两列 ‘name’和‘team’不包含被分到了一起
# 按索引的奇偶行分组
df.groupby(df.index%2==0).sum()
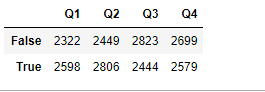
2.4 函数分组
:satr:by参数可以调用一个函数,通过函数计算返回一个分组依据
#按姓名首字母为元音or辅音分组
def first_letter(name):
if name[0].lower() in 'aeiou':
return 'yuan yin'
return 'fu yin'
df.set_index('name').groupby(first_letter).sum()

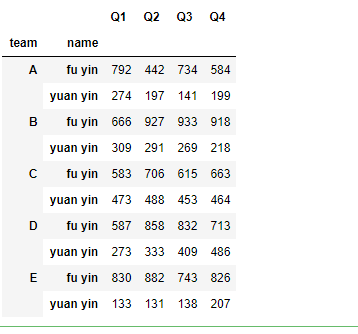
2.5 多种方法混合
by参数传一个list
df.groupby(['team',df.name.apply(first_letter)]).sum()
3、分组对象操作
3.1 选择分组
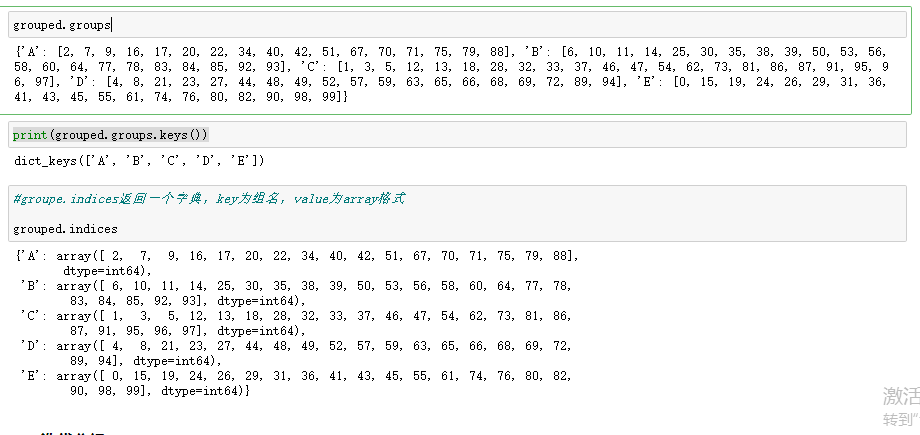
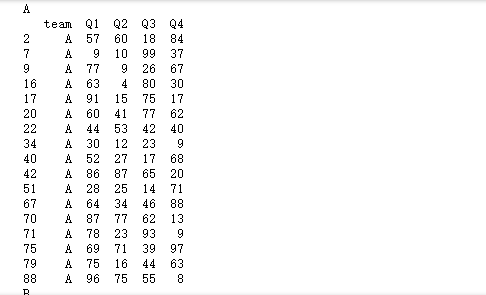
3.2 迭代分组
for name, item in grouped:
print(name)
print(item)
3.3 选择列
#选择分组后各组的某一列,像df那样选择即可
grouped.Q1.sum()
#选择多列
grouped['Q1','Q2'].sum()

3.4 应用函数apply
⭐分组对象调用apply,是传入一个df,返回经过函数计算后的df,s,或者标量,再把数据组合
#将Q1的数据*2
grouped.apply(lambda x:x.Q1*2)
'''
```
team
A 2 114
7 18
9 154
16 126
17 182
...
E 80 184
82 8
90 76
98 22
99 42
Name: Q1, Length: 100, dtype: int64
```
'''
#见分组中的一列输出为列表
grouped.apply(lambda x:x.Q1.to_list())
'''
```
team
A [57, 9, 77, 63, 91, 60, 44, 30, 52, 86, 28, 64...
B [61, 17, 9, 80, 89, 57, 9, 97, 2, 66, 18, 21, ...
C [36, 93, 24, 83, 51, 80, 50, 91, 90, 1, 29, 69...
D [65, 64, 79, 80, 62, 15, 24, 57, 50, 79, 5, 14...
E [89, 48, 97, 74, 71, 35, 67, 88, 48, 8, 8, 12,...
dtype: object
```
'''
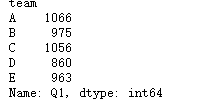
#实现每组成绩前三
def get_head(df):
df['sum']=df.sum(1)
df = df.sort_values('sum',ascending = False)
return df.head(3)
df.set_index('name').groupby('team').apply(get_head)
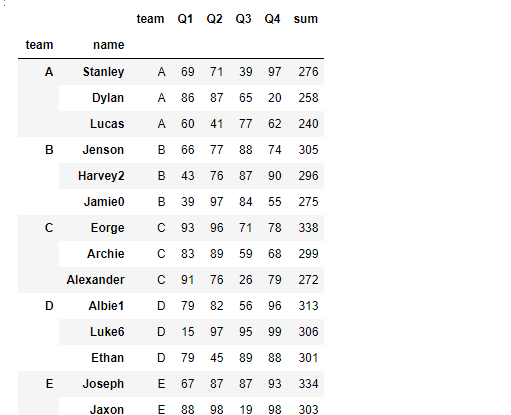
#传入一个series,隐射系列不同的聚合统计方法
def f_mi(x):
d = []
d.append(x['Q1'].sum())
d.append(x['Q2'].max())
d.append(x['Q3'].mean())
d.append(x['Q4']*x['Q4'].sum())
return pd.Series(d,index=[['Q1','Q2','Q3','Q4'],['sum','max','mean','prodsum']])
df.groupby('team').apply(f_mi)
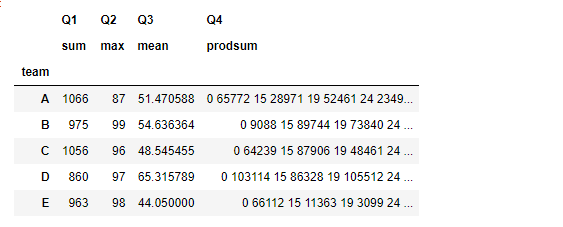
3.5 管道方法pipe
类似于df的管道方法
⭐将同组的所有数据应用在方法中,返回的是经过函数处理的返回数据格式
#每组最大值和最小值之和
grouped.pipe(lambda x:x.max()+x.min())
#下面使用自定义函数,经过计算,返回一个Series
#A/B组平均值的差值
def get_mean(df):
return df.get_group('A').mean()-df.get_group('B').mean()
grouped.pipe(get_mean)
'''
```
Q1 18.387701
Q2 -17.775401
Q3 -3.165775
Q4 -5.577540
dtype: float64
```
'''
3.6 转换方法transform
:satr:transform()类似于agg,但transform会返回与原始数据相同形状的DateFrame
- 会将原来数据的值一一替换成统计后的值
例如:按组计算平均成绩,那么返回的新的df中每个学生的成绩就是它所在组的平均成绩
#将所有数据替换成分组中的平均成绩
grouped.transform('mean')
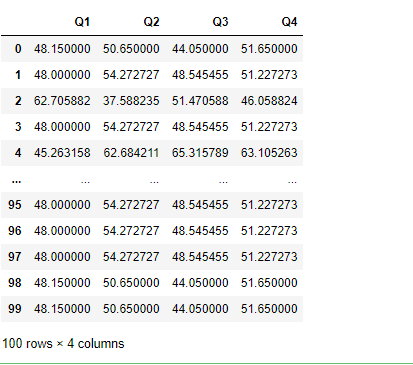
#可以用它进行按组筛选
#Q1成绩大于60的组的所有成员
df[grouped.transform('mean').Q1>60]
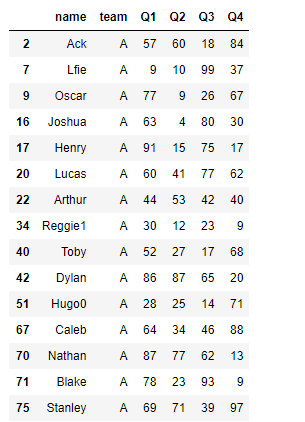
3.7 筛选方法filter
⭐使用filter()对组作为整体进行筛选,满足条件,整个组会被显示 传入它调用的函数的默认变量是每个分组的DateFrame,经过计算,最终返回一个布尔值,为真的DateFrame全部显示
#按团队分组,每组的每个季度成绩为本季度的的平均分
#全年的成绩为这个季度的平均分的平均费
#最终筛选出团队中分数高于51的所有成员
def get_score(df):
score = 51
return df.mean().mean() > score
df.groupby('team').filter(get_score)
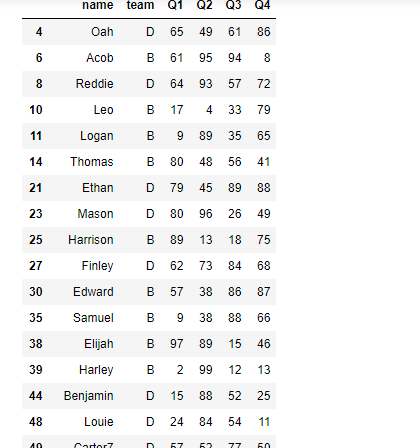
# Q1成绩至少有一个大于97的组
grouped.filter(lambda x:(x.Q1>97).any())
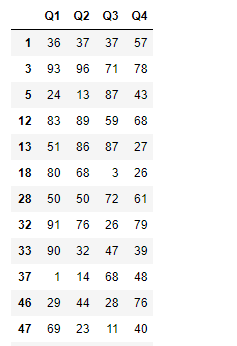
#所有成员平均成绩大于60的组
grouped.filter(lambda x: (x.mean()>30).all())
4、参考文献
《深入浅出Pandas》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号