数据表示与特征工程--分箱、离散化、线性模型与树
1、线性模型与决策树在wave数据集上的表现
⭐数据表示的最佳方法不仅取决于数据的语义,还取决于所使用的模型种类。
线性模型与基于树的模型(决策树、梯度提升树、随机森林)很常用的模型,但他们在处理不同特征表示时具有非常不同的性质。
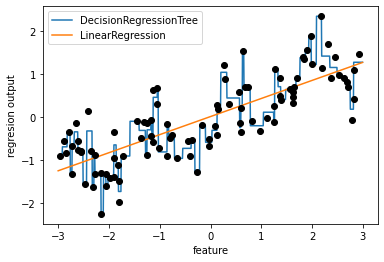
⭐下面是线性回归和决策树在make_wave数据集中的对比
import mglearn
from sklearn.linear_model import LinearRegression
X ,y = mglearn.datasets.make_wave(n_samples=100)
line = np.linspace(-3,3,1000,endpoint=False).reshape(-1,1)
#画出(-3,3)区间上,在决策树上的预测值,因此输入的横坐标是line而不是X
t_reg = DecisionTreeRegressor(min_samples_split=3).fit(X,y)
plt.plot(line,t_reg.predict(line),label='DecisionRegressionTree')
#在线性回归上的预测
l_reg = LinearRegression().fit(X,y)
plt.plot(line,l_reg.predict(line),label='LinearRegression')
#画出数据样本点
plt.plot(X[:,0],y,'o',c='k')
plt.legend()
plt.xlabel('feature')
plt.ylabel('regresion output')
📣
- 线性模型对单个特征的建模,就是直线 y=kx+b
- 决策树可以构建更复杂的数据表示,但依赖于数据表示
2、分箱(离散化)
⭐分箱(离散化):将单个特征划分为多个特征,让线性模型在连续的数据上变得更加强大
#创建10个箱子
bins = np.linspace(-3,3,11) #11个数据点,中间有10个数据间隔
bins.shape
#输出:(11,)
#用np.digitize函数找到每个数据点所在的箱子,which_bin 记录了每个数据点在哪个箱子,箱子从1开始编码
which_bin = np.digitize(X,bins=bins)
which_bin[0:5]
#输出:
''' array([[ 4],
[10],
[ 8],
[ 6],
[ 2]], dtype=int64)
'''
np.bincount(which_bin.ravel()) #看一下每个箱子里有多少个数据
#输出:array([ 0, 13, 15, 6, 12, 7, 10, 7, 12, 9, 9], dtype=int64)
2.1 One-Hot编码
⭐
接下来我们将wave数据集中 连续单个输入特征 变换为一个 分类特征
数据点属于哪个箱子,表示对应箱子特征取值就为1
用sklearn.preprocessing.OneHotEncoder实现(它与pd.get_dummies相似,但onehot只适用于整数的分类变量)
from sklearn.preprocessing import OneHotEncoder
#which_bin相当于分箱变换后的X,它记录了每个数据点的信息(在哪个箱子),一共100条数据点
encoder = OneHotEncoder(sparse=False).fit(which_bin) #fir找到which_bin(100,1)中的唯一值,
X_binned = encoder.transform(which_bin) #transform创建one-hot编码,注意这里是对which进行变换
print(X_binned[0:5])
输出:
'''
[[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]]
'''
2.2 构建模型进行对比
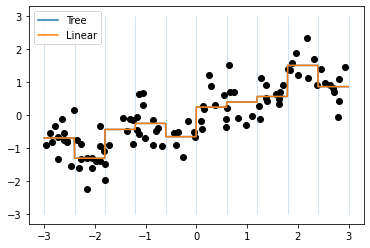
⭐接下来,我们在one-hot编码后的数据上构建新的线性模型+新的决策树模型
t_reg = DecisionTreeRegressor(min_samples_split=3).fit(X_binned,y)
l_reg = LinearRegression().fit(X_binned,y)
#记住,如果对X进行了如下变换:1、which-bin(分箱)2、one-hot编码。则对需要test的数据也要进行同样的变换
w_line = np.digitize(line,bins) #对line进行分箱
line_binned = encoder.transform(w_line) #对line进行one-hot编码(遵循训练集训练好的encoder器)
#画图
plt.plot(X,y,'o',c='k')
plt.plot(line,t_reg.predict(line_binned),label='Tree')
plt.plot(line,l_reg.predict(line_binned),label='Linear')
plt.vlines(bins,-3,3,linewidth=1,alpha=.2)
plt.legend()
📣
两条线完全重合,说明两个模型做出了完全相同的预测
对于每个分箱的预测值都是一个常数,因为每个箱子内的特征是不变的,
- 分箱针对单个特征
- 所以对于同一个箱子内的所有点,任何模型都会预测相同的值
分箱特征对于树的模型没有什么大的改进,但是对于线性模型的表现力提升很有成效
-对于线性模型,如果数据集很大,维度很高,有些特征与输出的关系是非线性的,则分箱不失为一种好方法
3、参考文献
《python机器学习基础教程》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号