数据表示与特征工程--分类变量
💚特征工程:对于某个特定的应用,如何找到最佳的数据表示
- 用正确的方式表示数据,对监督模型性能的影响比所选择的精确参数还要大~
💚分类特征(离散特征):数据输入不以连续的方式变化,不同的分类之间也没有顺序,不可以比较和四则运算
💚连续特征:输入是连续的
1、关于要用到的adult数据集
data = pd.read_csv('../../datasets/adult/adult.data',header=None,index_col=None)
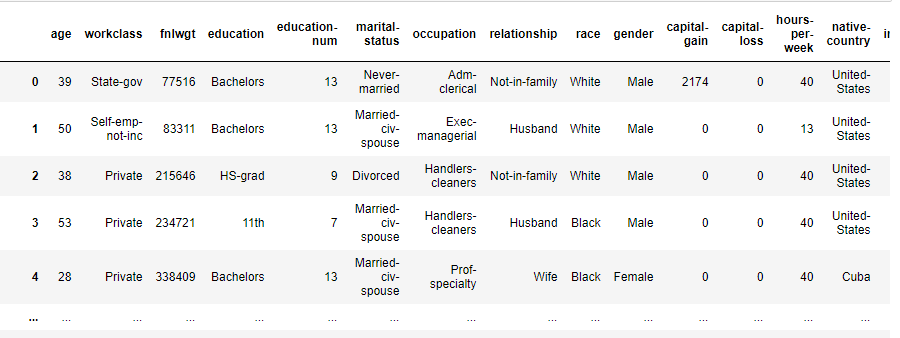
- Adult数据集是一个经典的数据挖掘项目的的数据集,该数据从美国1994年人口普查数据库中抽取而来,因此也称作“人口普查收入”数据集,共包含48842条记录,年收入大于 50k$ 的占比23.93%年收入小于 50k$的占比76.07%,数据集已经划分为训练数据32561条和测试数据16281条。
- 该数据集类变量为年收入是否超过 50k$ ,属性变量包括年龄、工种、学历、职业等14类重要信息,其中有8类属于类别离散型变量,另外6类属于数值连续型变量。
- 该数据集是一个分类数据集,用来预测年收入是否超过50k$
2、One-Hot编码(虚拟变量)
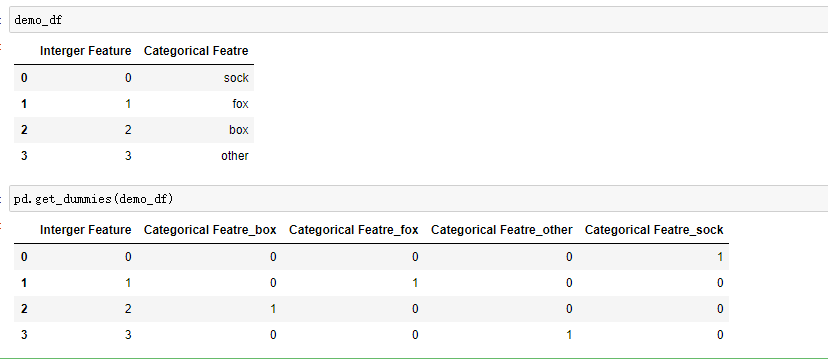
💚one-hot 编码(one-hot encoding)也叫虚拟变量(dummy variables),是一种将分类变量转换为几个二进制列的方法。其中 1 代表某个输入属于该类别。
💚虚拟变量的思想:将一个分类变量替换为一个或多个新的特征
#我们只选取该数据中的几列
data = data[['age','workclass','education','gender','hours-per-week','occupation','income']]
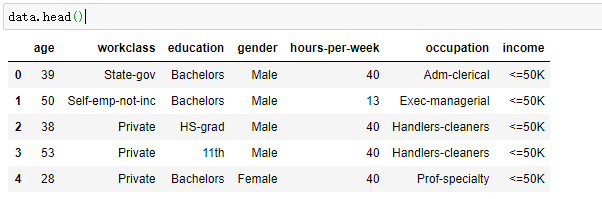
2.1 检查字符串编码的分类数据(s.value_count())
💚读取完数据集后,最好先检查每一列是否包含有意义的分类数据
#检查字符串编码的分类数据有个类别
print(data.gender.value_counts())

#get_dummies 函数,自动变换所有具有对象类型
print('original feature:{}'.format(data.columns))
data_dummies = pd.get_dummies(data)
print('after dummies feature:{}'.format(data_dummies.columns))

2.2 用逻辑回归进行拟合
💚将数据转换为numpy的数组之后,就可以被sklearn处理,像之前一样
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=0)
logreg = LogisticRegression().fit(X_train,y_train)
print('Test score:{}'.format(logreg.score(X_test,y_test)))
输出
Test score:0.8067804937968308
3、数字可以编码分类变量
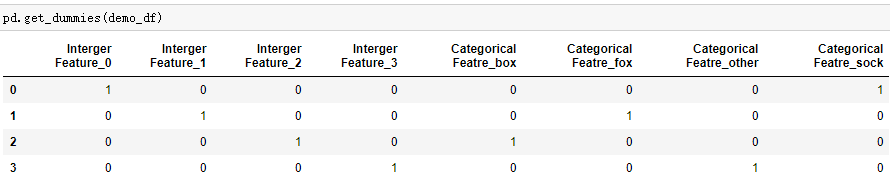
💚pandas 的 get_dummies 函数将所有数字看作是连续的,不会为其创建虚拟变量。可以用 scikit-learn 的 OneHotEncoder,指定哪些变量连续、离散,也可以将数据框中的数值列转换为字符串。
#分类特征通常用整数进行编码
#性别:0/1
#pandas的get_dummies把所有数字看做连续的,不会为其创建虚拟变量,可以自行指定
demo_df = pd.DataFrame({'Interger Feature':[0,1,2,3],
'Categorical Featre':['sock','fox','box','other']})
#若要为Integer Feature 创建虚拟变量,需要显示的指定coulumns=,或者将数字列astype成str类型
demo_df['Interger Feature']=demo_df['Interger Feature'].astype(str)
4、参考文献
《python机器学习基础教程》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号