Pandas:添加修改、高级过滤
1、添加修改数据
Pandas 的数据修改是进行赋值,先把要修改的数据筛选出来,然后将同结构或者可解包的数据赋值给它:
修改数值
df.Q1 = [1, 3, 5, 7, 9] * 20 # 就会把值进行修改
df.loc[1:3, 'Q1':'Q2'] = 99 # 这个范围的数据会全变成 99
df.loc[df.name=='Arry', 'Q1':'Q4'] = [66,77,88,99] # 指定多列
df.loc[df.name.isin(['Arry', 'Ack']), 'Q1'] = (33, 44) # 修改列值
- 将Q1分数<60的值改为60
替换数据
s.replace(0, 5) # 将列数据中 0 换为 5
df.replace(0, 5) # 将数据中所有 0 换为 5
df.replace([0, 1, 2, 3], 4) # 将 0-3 全换成 4
df.replace([0, 1, 2, 3], [4, 3, 2, 1]) # 对应修改
# {‘pad’, ‘ffill’, ‘bfill’, None}
s.replace([1, 2], method='bfill') # 向下填充
df.replace({0: 10, 1: 100}) # 字典对应修改
df.replace({'Q1': 0, 'Q2': 5}, 100) # 指定字段的指定值修改为 100
df.replace({'Q1': {0: 100, 4: 400}}) # 指定列里指定值按指定的值替换
- 将team中的A改为classA

填充空值
df.fillna(0) # 空全修改为 0
# {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None
df.fillna(method='ffill') # 都修改为它前一个值
values = {'A': 0, 'B': 1, 'C': 2, 'D': 3}
df.fillna(value=values) # 各列替换空值不同
df.fillna(value=values, limit=1) # 只替换第一个
修改索引名
df.rename(columns={"Q1": "a", "Q2": "b"}) # 对表头进行修改
df.rename(index={0: "x", 1: "y", 2: "z"}) # 对索引进行修改
增加列
df['foo'] = 100 # 增加一列 foo, 所有值都是 100
# 把所有为数字的加起来
df['total'] = df.select_dtypes(include=['int']).sum(1)
df['total'] = df.loc[:,'Q1':'Q4'].apply(lambda x: sum(x), axis='columns')
# 增加一列并赋值,不满足条件的为 NaN
df.loc[df.num >= 60, '成绩'] = '合格'
df.loc[df.num < 60, '成绩'] = '不合格'

插入列df.insert()
# 一般格式 df.insert(新列索引位, 名字, 数据)
df.insert(len(df.columns), 'Qx',pd.Series(np.random.randn(100), index=df.index))
指定列df.assign()
df.assign(Q5=[100]*100) # 新增加一列 Q5
# 添加一列,值为表达式结果 True or False
df.assign(tag=df.Q1>df.Q2)
# True 为1 False 为 0
df.assign(tag=(df.Q1>df.Q2).astype(int))
# 映射文案
df.assign(tag=(df.Q1>60).map({True:'及格',False:'不及格'}))
# 增加多个
df.assign(Q8=lambda x: x.Q1*5,Q9=lambda x: x.Q8+1) # 注 Q8没生效不能直接 df.Q8
执行表达式df.eval()
-
可以进行赋值定义一个新列:
df['C1'] = df.eval('Q2 + Q3') df.eval('C2 = Q2 + Q3') # 计算 a = df.Q1.mean() df.eval("C3 = `Q3`+@a") # 使用变量 df.eval("C3 = Q2 > (`Q3`+@a)") # 加一个布尔值 df.eval('C4 = name + team', inplace=True) # 立即生效
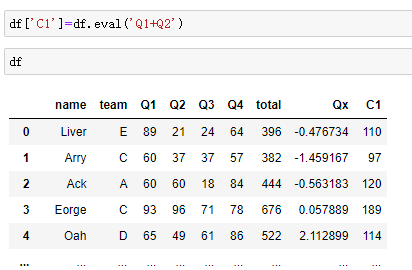
删除
df.pop('Q1') # 删除一列
s.pop(3) # 删除一个索引位
# 也可以把想要的列筛选出来赋值给 df 达到删除的目的
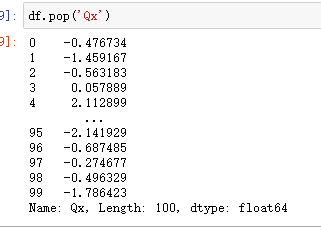
2、高级过滤
df.where(),df.mask()
# np.where, 大于80是真,否则是假
np.where(s>80, True, False)
np.where(df.num>=60, '合格', '不合格')
s.mask(s > 90) # 符合条件的为 NaN
s.mask(s > 90, 0) # 符合条件的为 0
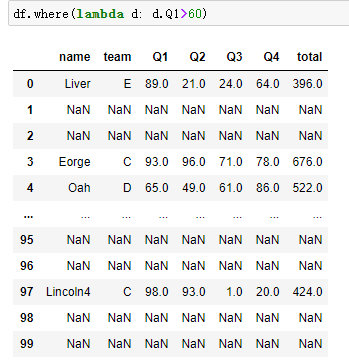
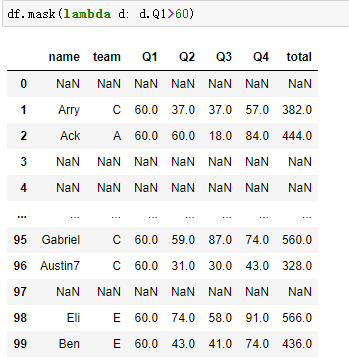
总结:
- where:替换不满足条件的(显示满足的)
- mask:替换满足条件的(显示不满足的)
3、参考文献
《深入浅出Pandas》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号