K近邻
监督机器学习问题主要分两种:1、分类,2、回归
👍 区分分类任务和回归任务:输出是否具有某种连续性。
泛化:一个模型能对新数据进行很好地预测,则该模型泛化性能好
过拟合:模拟模型时过分关注训练集的细节,得到一个在训练集上表现好,但不能泛化到新数据上
拟合:选择过于简单的模型
1、K近邻
算法思想:想要对新数据点进行预测,算法会在训练数据集中找到最邻近的数据点,就是它的“最近邻”,除了考虑最近邻,还可以考虑任意个(K个)邻居,并使用“投票法”指定标签。
1)、K近邻分类
这里使用 forge数据集
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
#获取数据
X,y = mglearn.datasets.make_forge()
#划分数据集
X_train, X_test, y_train, y_test =train_test_split(X, y,random_state=0)
#选择KNN模型+拟合模型
clf = KNeighborsClassifier(n_neighbors=3).fit(X_train,y_train)
#测试精度
print("test accuracy: {:.2f}".format(clf.score(X_test,y_test)))
2)、分析KneighborsClassifier
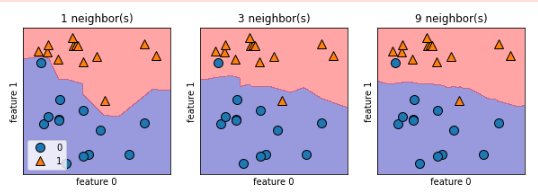
- 决策边界:算法对类别0和类别1的分界线
- 使用更少的邻居对应更高的模型复杂度;随着邻居数量增加,模型复杂度下降,决策边界会变得光滑
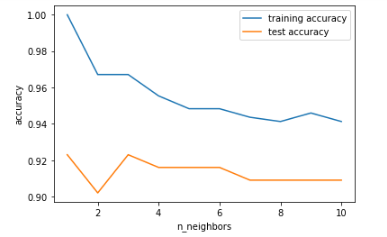
-
模型复杂度和泛化能力的关系
可以看出仅考虑单一邻居时,模型在训练集上表现得非常完美,但随着邻居个数增多,模型复杂度下降,训练集精度下降,测试集精度提升;
而随着邻居数量不断增大到10个时,模型又过于简单,性能变得更差,因此最佳性能在中间的某处,大约邻居数为6。
👍为什么K值越小,模型反而越复杂,易出现过拟合现象?
- 首先应该弄清楚过拟合的意思是模型在训练时过分注重细节,学到了不少局部信息,或者噪声,使得模型包含一些“不是规律的规律”。
而使用KNN算法时,k值越小,则说明该模型在测试时,高概率会受到“有误差信息”的影响,导致预测错误。
这也就是为什么K值越小,模型越复杂,越容易出现过拟合。
3)、K近邻回归
K近邻算法不仅可以用于分类,还能用于回归,这里使用wave数据集。
from sklearn.neighbors import KNeighborsRegressor
#获取数据
X,y = mglearn.datasets.make_wave(n_samples=40)
#划分数据集
X_train, X_test, y_train, y_test =train_test_split(X, y,random_state=0)
#选择KNN模型+拟合模型
clf = KNeighborsRegressor(n_neighbors=3).fit(X_train,y_train)
#测试精度
print("test accuracy: {:.2f}".format(clf.score(X_test,y_test)))
4)、分析KneighborsRegressor
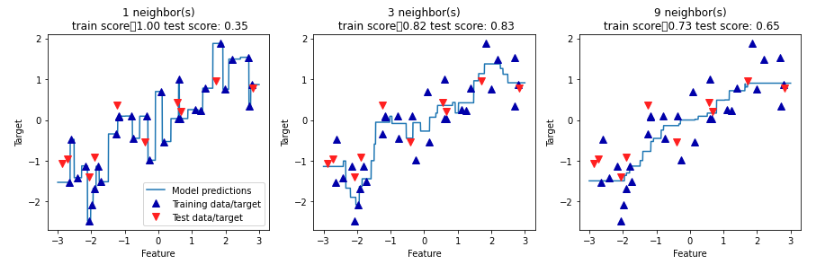
- 使用单一邻居,训练集中的每个点,都对预测结果有显著影响,预测结果的图像经过所有数据点;
- 考虑更多邻居后,预测结果变得更加平滑,但对训练数据的拟合也不好。
5)、优点、缺点和参数
KNeighbors分类器的两个重要参数:1、邻居个数 ,2、数据点之间距离的度量方法
使用较小的邻居个数(比如3个或5个)往往可以得到比较好的结果,但应该调节这个参数.
-
优点:
- 模型很容易理解,构建模型的速度通常很快
-
缺点:
- 👍不能处理具有很多特征的数据集
- 预测速度可能会比较慢
2、一些数据集
本算法中用到的两个数据集:1、forge数据集,2、wave数据集
forge数据集:可以用于模拟二分类问题,数据集包含26个数据点和2个特征,两种输出。
wave数据集:用来测试回归算法,数据集只有一个输入特征,一个连续的目标变量/响应。
3、参考文献
《Pyhon机器学习基础教程》第二章p28-p35

 浙公网安备 33010602011771号
浙公网安备 33010602011771号