构建第一个模型:KNN算法(Iris_dataset)
利用鸢尾花数据集完成一个简单的机器学习应用~万丈高楼平地起,虽然很基础,但是还是跟着书敲了一遍代码。
一、模型构建流程
1、获取数据
- 本次实验的Iris数据集来自skicit-learn的datasets模块
from sklearn.datasets import load_iris
iris_dataset = load_iris()
-
查看一下数据:
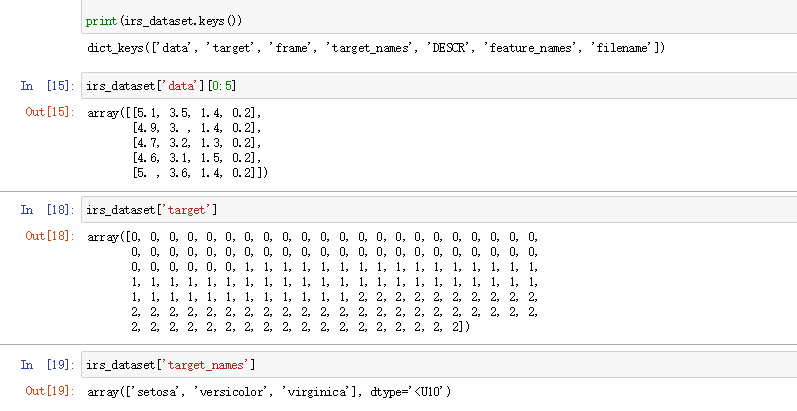
-
可以发现iris_dataset类似一个字典,里面包含键和值,其中键值对包括数据的简介(DESC)、标签值(target)、数据样本(data),标签名(target name)等
2、数据预处理
- 本次使用的数据无需预处理,已经处理好了,目标值也被表示为0,1,2的数字标签,data和target都是ndarray数组。
3、特征工程
- 本次数据还比较简单,特征也少,无需特征选择,
- 这里利用pandas的scatter.metrix将数据进行可视化一下,进行观察各个特征之间的关系,
在此之前先划分一下训练集和测试集
- 这里利用pandas的scatter.metrix将数据进行可视化一下,进行观察各个特征之间的关系,
#划分训练集,测试集
X_train,X_test,y_trian,y_test = train_test_split(irs_dataset['data'],irs_dataset['target'],random_state = 0)
#利用pd,画散点图,观察数据是否有异常值
irs_dataframe = pd.DataFrame(X_train,columns=irs_dataset.feature_names)
grr = pd.plotting.scatter_matrix(irs_dataframe,c=y_trian,figsize=(8,8),marker='o',
hist_kwds={'bins':20},s=60,alpha=.8)
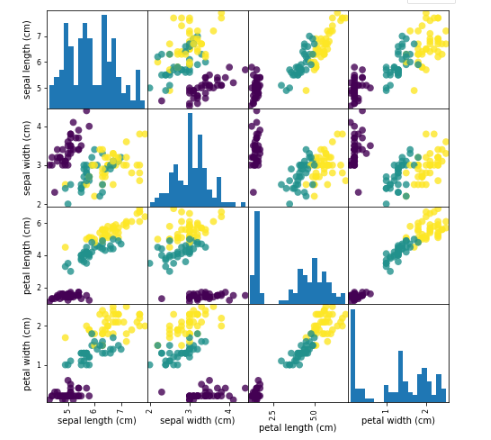
4、(机器学习)构建模型
-
考虑到这个数据特点,这里使用KNN算法
-
KNN:在判断一个数据X的标签时,会计算距离它与其他所有样本x1,x2,x3,...,的距离,选择距离它最近的k个样本的标签值,作为该数据X的标签值。
#建立模型:KNN算法
knn = KNeighborsClassifier(n_neighbors=2) #把k值设为2
knn.fit(X_train, y_trian) #基于训练集构建模型,两个参数都是Numpy 数组
5、模型评估
-
怎么知道该模型在预测新数据时的有效性呢?有很多评估指标,比如说精确率、召回率...
-
这里使用精确率:正确预测列别的数据,占所有数据的比例
#评估模型
y_pred = knn.predict(X_test)
print(y_pred)
print("precision={:.2f}".format(np.mean(y_pred==y_test)))
print(knn.score(X_test, y_test))
二、遇到的问题
- 按照书上所写使用pandas的scatter.metrix画散点图做相关性分析时遇到’module ‘pandas’ has no attribute ‘scatter_matrix’'这个问题

-
解决方法:
-
现在的pandas的scatter_matrix用法已经发生变化了,在使用时需要加上plotting,即:pandas.plotting.scatter_matrix
三、参考文献
《python机器学习基础教程》--【德】Adreas C.Muller

 浙公网安备 33010602011771号
浙公网安备 33010602011771号